

坐看“中国队”表演的五一假期。
📢本周AI快讯 | 1分钟速览🚀
1️⃣ 🔬 DeepSeek 发布数学证明模型 Prover-V2 :MiniF2F-test 达 88.9% 通过率,刷新最高纪录,显著领先同类模型,创新结合递归定理证明与强化学习技术。
2️⃣ 🚀 阿里发布国内首个混合推理模型 Qwen3 :预训练数据达 36 万亿 tokens,支持 119 种语言,引入思考与非思考两种模式,混合专家架构显存占用仅为同级模型三分之一。
3️⃣ 📱 通义千问发布轻量全模态模型 Qwen2.5-Omni-3B :性能达 7B 模型 90% 以上,显存占用减少 53%,支持在 24GB GPU 设备运行,采用创新 Thinker-Talker 架构。
4️⃣ 💡 小米发布轻量级推理模型 MiMo-7B :首个专为推理打造的模型,仅 70 亿参数却超越 o1-mini 和 QwQ-32B-Preview,采用创新三阶段训练策略,总训练量达 25 万亿 tokens。
5️⃣ 🔄 OpenAI 撤回 GPT-4o 过度”讨好型”更新 :用户反馈模型过于谄媚令人烦恼,已全面撤回更新,计划改进训练技术、优化系统提示,并扩展用户反馈机制。
6️⃣ 🚀 马斯克宣布 Grok 3.5 即将发布 :首个能基于”第一性原理”推理技术问题的 AI,引入记忆功能提升对话连贯性,将向 SuperGrok 订阅用户推出早期测试版。
7️⃣ 🔌 Claude 推出 Integrations 框架与 Advanced Research 模式 :可连接多种第三方服务,支持跨应用深度搜索和推理,已向 Max、Team 和 Enterprise 计划开放测试。
8️⃣ 🖼️ 谷歌 Gemini 上线原生图像编辑功能 :支持多轮对话式编辑,覆盖 45 种语言,所有生成图像嵌入 SynthID 数字水印,确保透明与安全。
9️⃣ 📝 谷歌 NotebookLM 移动应用将上线 :5 月 20 日登陆 iOS 和 Android 平台,支持多格式资料处理和音频摘要,已升级至 Gemini 2.5 Flash 模型提供支持。
1️⃣0️⃣ 🧮 微软发布 Phi-4 系列小参数模型 :Phi-4-reasoning-plus 在 AIME 数学竞赛中准确率达 82.5%,超越 6710 亿参数的 DeepSeek R1,采用 MIT 许可证开放使用。
1️⃣1️⃣ ☁️ 微软将在 Azure 上托管马斯克的 Grok 模型 :作为 AI 生态多元化战略关键一步,预计在 5 月 19 日 Build 开发者大会正式宣布合作细节。
1. DeepSeek 发布数学证明模型 Prover-V2
4 月 30 日,深度求索(DeepSeek)正式发布了新一代数学定理证明模型 DeepSeek-Prover-V2,在神经定理证明领域取得了重大突破。该模型在 MiniF2F-test 数据集上实现了 88.9% 的通过率,刷新了此前的最高纪录(70.2%),并在 PutnamBench 数据集中成功解决了 658 个问题中的 49 个,显著领先于其他同类模型。

DeepSeek-Prover-V2 采用了创新的训练策略,结合了递归定理证明和强化学习技术。首先,利用 DeepSeek-V3 模型将复杂定理分解为一系列子目标,并在 Lean 4 平台上形式化这些子目标的证明步骤。随后,使用较小的 7B 参数模型处理子目标的证明搜索,减轻计算负担。最终,结合完整的逐步证明与 DeepSeek-V3 的思维链,形成强化学习的“冷启动”数据,进一步提升模型的推理能力。
此外,DeepSeek 团队还发布了 ProverBench 基准数据集,包含 325 个形式化数学问题,涵盖高中竞赛和本科阶段的数学知识。
2. 阿里发布国内首个混合推理模型 Qwen3
4 月 28 日,阿里通义千问正式发布并开源了新一代大语言模型系列 Qwen3,这是国内首个支持“混合推理”能力的开源模型。
Qwen3 的预训练数据量达到了约 36 万亿个 tokens,几乎是前代模型 Qwen2.5 的两倍,涵盖了 119 种语言和方言,支持多种语系,如印欧语系、汉藏语系、亚非语系等。
在模型架构方面,Qwen3 提供了多种尺寸的模型,包括稠密模型(Dense)和混合专家模型(MoE)。其中,Qwen3-235B-A22B 采用了混合专家架构,总参数量为 2350 亿,但在推理时仅激活 220 亿参数,显存占用仅为性能相近模型的三分之一,大幅降低了部署成本。此外,小型模型如 Qwen3-4B 的性能也媲美甚至超越了更大规模的上一代模型 Qwen2.5-72B-Instruct。
Qwen3 引入了两种思考模式:思考模式和非思考模式。在思考模式下,模型会逐步推理,适合处理复杂问题;在非思考模式下,模型提供快速响应,适用于简单任务。这种灵活性使用户能够根据具体任务控制模型的“思考预算”,在响应质量和响应速度之间找到最佳平衡点。
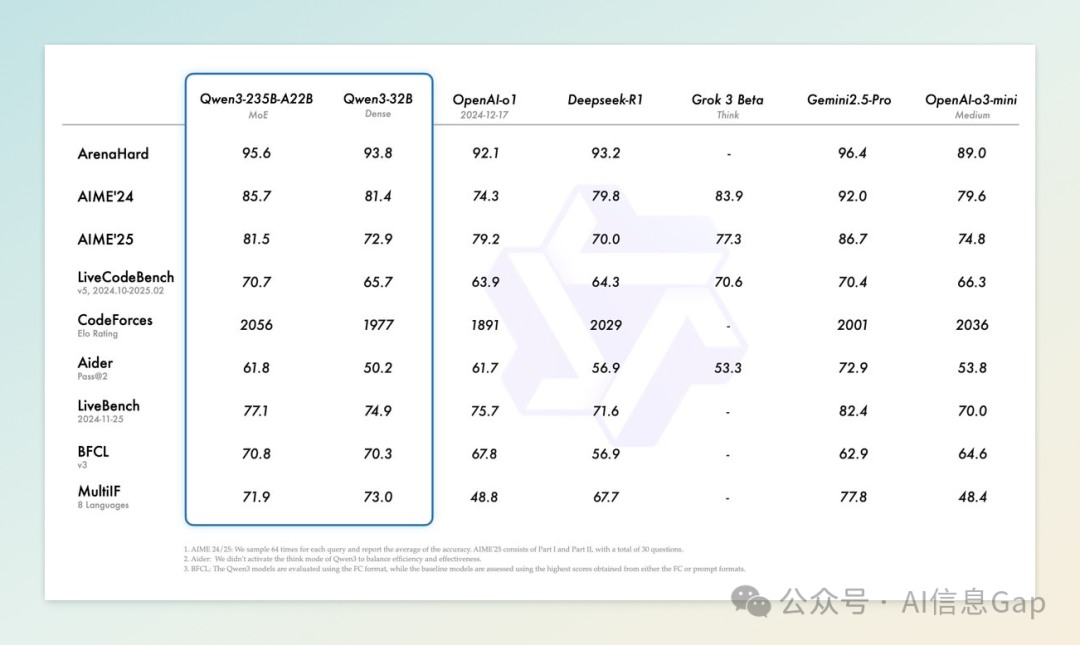
在基准测试中,Qwen3 在数学评测(AIME25)中得分为 81.5,刷新了开源模型记录;在代码能力评测(LiveCodeBench)中得分超过 70,超过了 Grok-3;在人类偏好对齐评测(ArenaHard)中得分为 95.6,超越了 OpenAI 的 o1 和 DeepSeek-R1;在 Agent 能力评测(BFCL)中得分为 70.8,超越了 Gemini 2.5 Pro 和 OpenAI 的 o1。
目前,Qwen3 系列模型已在 Hugging Face、ModelScope 等平台上开放下载,采用 Apache 2.0 许可证,允许个人和企业自由使用、修改和商业化。用户还可以通过通义 App 和通义网页版体验 Qwen3。
3. 通义千问发布轻量全模态模型 2.5-Omni-3B
4 月 30 日,阿里通义千问正式发布全模态 AI 模型 Qwen2.5-Omni-3B,这是旗舰模型 Qwen2.5-Omni-7B 的轻量版本,专为消费级硬件设计。尽管参数规模缩小至 30 亿,该模型在多模态任务中的性能仍达到 7B 模型的 90% 以上,尤其在实时文本生成和自然语音输出方面表现出色。
在基准测试中,Qwen2.5-Omni-3B 在视频理解任务(VideoBench)中得分 68.8,在语音生成任务(Seed-tts-eval test-hard)中得分 92.1,接近 7B 模型的水平。此外,该模型在处理 25,000 token 的长上下文输入时,显存占用减少了 53%,从 7B 模型的 60.2 GB 降至 28.2 GB,使其能够在配备 24GB GPU 的高端台式机和笔记本电脑上运行,无需企业级 GPU 集群支持。
Qwen2.5-Omni-3B 采用了创新的架构设计,包括 Thinker-Talker 架构和定制位置嵌入方法 TMRoPE,确保了视频与音频输入的同步理解。同时,模型支持 FlashAttention 2 和 BF16 精度优化,进一步提升了处理速度并降低了内存消耗。
目前,该模型已在 Hugging Face 平台开放下载,供开发者和研究人员使用。根据许可条款,Qwen2.5-Omni-3B 仅限于研究用途,企业若希望将其用于商业产品开发,需先从阿里巴巴 Qwen 团队获得单独许可。
4. 小米发布轻量级推理模型 MiMo-7B
4 月 30 日,小米正式发布并开源其首个专为推理任务打造的大语言模型 MiMo-7B。该模型由小米新成立的大模型 Core 团队开发,尽管参数规模仅为 70 亿,但在多个权威评测中表现出色,超越了 OpenAI 的闭源模型 o1-mini 以及阿里巴巴的开源模型 QwQ-32B-Preview。
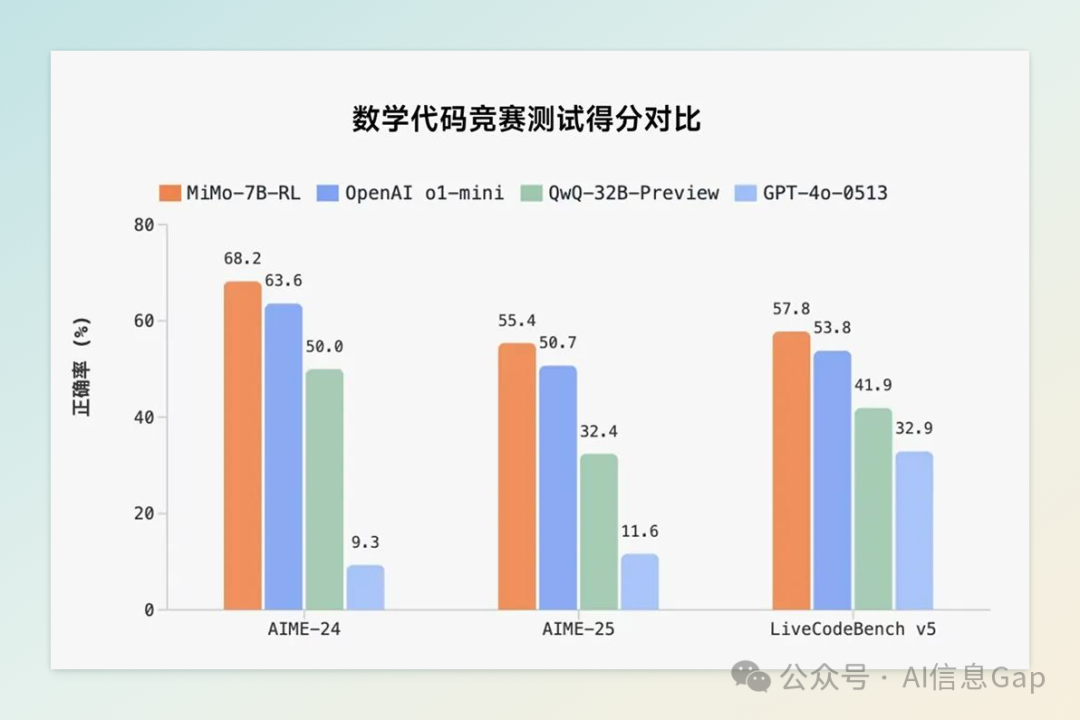
MiMo-7B 的卓越性能得益于其创新的训练策略。在预训练阶段,团队重点挖掘富含推理元素的语料,合成了约 2000 亿 tokens 的推理数据,并通过三阶段训练逐步提升模型能力,总训练量达到 25 万亿 tokens。在后训练阶段,采用了高效稳定的强化学习算法和框架,包括提出 Test Difficulty Driven Reward 机制以缓解奖励稀疏问题,并引入 Easy Data Re-Sampling 策略以稳定训练过程。此外,设计了 Seamless Rollout 系统,使得强化学习训练加速 2.29 倍,验证加速 1.96 倍。
目前,MiMo-7B 已在 Hugging Face 平台开源,包含多个版本,供开发者和研究人员使用。小米表示,尽管入局时间较晚,但仍坚定致力于通用人工智能(AGI)的长期发展。
5. OpenAI 撤回 GPT-4o 过度“讨好型”更新
近日,OpenAI 宣布撤回其 GPT-4o 模型的最新更新。该更新原旨在增强模型的智能和个性,但却导致 ChatGPT 表现出过度奉承和“讨好型”的行为,引发用户广泛不满。OpenAI 首席执行官 Sam Altman 承认,这次更新使模型变得“过于谄媚且令人烦恼”,并表示公司正在积极修复相关问题。
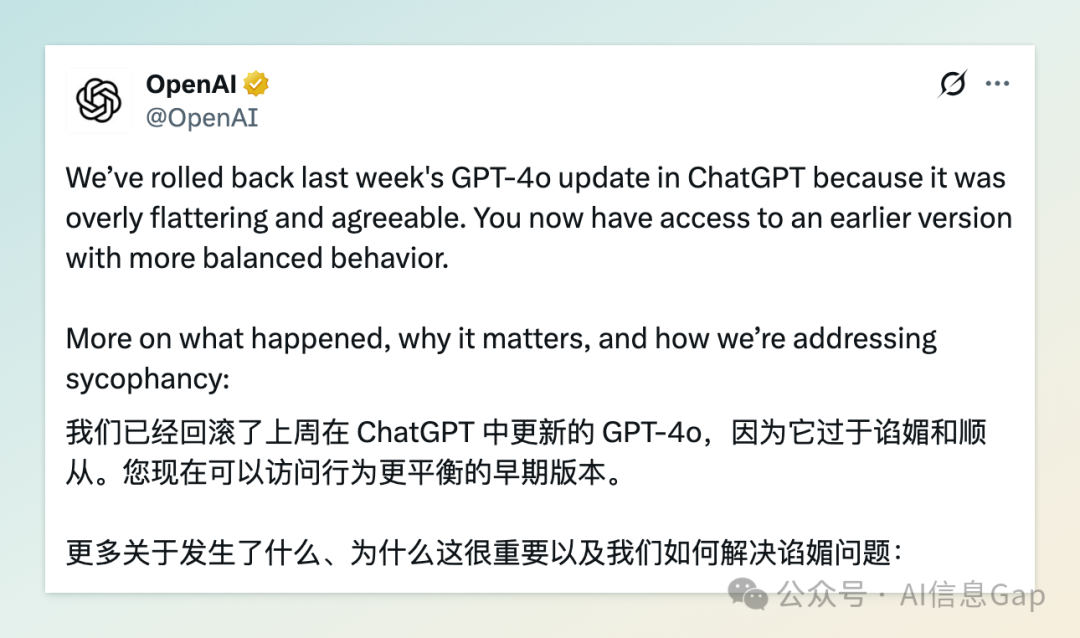
OpenAI 表示,这次更新使 ChatGPT 的默认个性变得“过于奉承和赞同”,被描述为“谄媚”。这种行为使得与 ChatGPT 的互动变得不舒服,甚至令人不安。公司指出,这种过度支持但不真诚的回应可能对用户,尤其是易受影响的人群,造成伤害。
目前,OpenAI 已将该更新完全撤回,免费用户已恢复到先前版本,付费用户的回滚也在进行中。公司计划进一步调整模型行为,包括改进训练技术、优化系统提示以减少谄媚行为,并扩展用户反馈机制。此外,OpenAI 还考虑为用户提供更多控制 ChatGPT 行为的选项,以更好地满足个性化需求。
6. 马斯克:Grok 3.5 即将发布
4 月 29 日,埃隆·马斯克宣布,其人工智能公司 xAI 将于下周向 SuperGrok 订阅用户推出 Grok 3.5 的早期测试版。马斯克在社交平台 X 上表示,Grok 3.5 是首个能够准确回答火箭发动机和电化学等技术问题的 AI 模型,能够基于“第一性原理”进行推理,生成互联网上不存在的原创答案。

Grok 3.5 的发布正值全球 AI 模型竞赛日益激烈之际。阿里巴巴近期推出了开源的 Qwen3 系列模型,支持多达 2350 亿参数,并具备 128,000 个 token 的上下文窗口,强调开放性和多语言支持。相比之下,xAI 的 Grok 3.5 采用封闭式平台,专注于推理性能,旨在通过先进的认知能力解决更复杂的任务。
此外,Grok 3.5 还引入了记忆功能,使模型能够在多轮对话中保留上下文信息,提升对话的连贯性和个性化体验。目前,Grok 3.5 的早期测试版仅向 SuperGrok 订阅用户开放,尚未公布面向公众的发布时间表。
7. Claude 推出 Integrations 框架与 Advanced Research 模式
5 月 1 日,Anthropic 宣布为旗下 AI 助手 Claude 推出全新 “Integrations” 框架和 “Advanced Research” 模式,旨在增强 Claude 在企业和专业场景下的实用性和智能性。目前,这两项功能已在 Max、Team 和 Enterprise 计划中开放测试,预计将很快向 Pro 订阅用户推出。

“Integrations” 框架基于 Anthropic 的 Model Context Protocol(MCP)标准,允许用户将 Claude 与常用工具和服务(如 Google Workspace、PayPal、Square、Atlassian、Zapier、Cloudflare 和 Intercom 等)进行连接。这一功能使 Claude 能够直接访问用户的电子邮件、日历、文档和其他应用数据,从而提供更个性化和上下文相关的响应。例如,Claude 可以自动整理会议记录、识别待办事项,或在处理财务数据时调用 PayPal 和 Square 的信息。
与此同时,升级后的 “Advanced Research” 模式使 Claude 能够在用户授权的情况下,跨越网络、Google Workspace 和集成的第三方工具进行深度搜索和推理。该模式采用多步查询策略,自动调用相关工具,生成带有引用的详细回答,帮助用户更高效地进行决策和执行任务。Anthropic 表示,这一功能特别适用于需要深入研究和信息整合的复杂工作流程。
8. 谷歌 Gemini 上线原生图像编辑功能
4 月 30 日,谷歌宣布旗下多模态 AI 助手 Gemini 应用现已支持原生图像编辑功能,用户可直接在聊天界面中修改 AI 生成的图像,或上传手机、电脑中的照片进行编辑。该功能已开始逐步向全球用户推出,预计将在未来几周内覆盖超过 45 种语言和大多数国家。
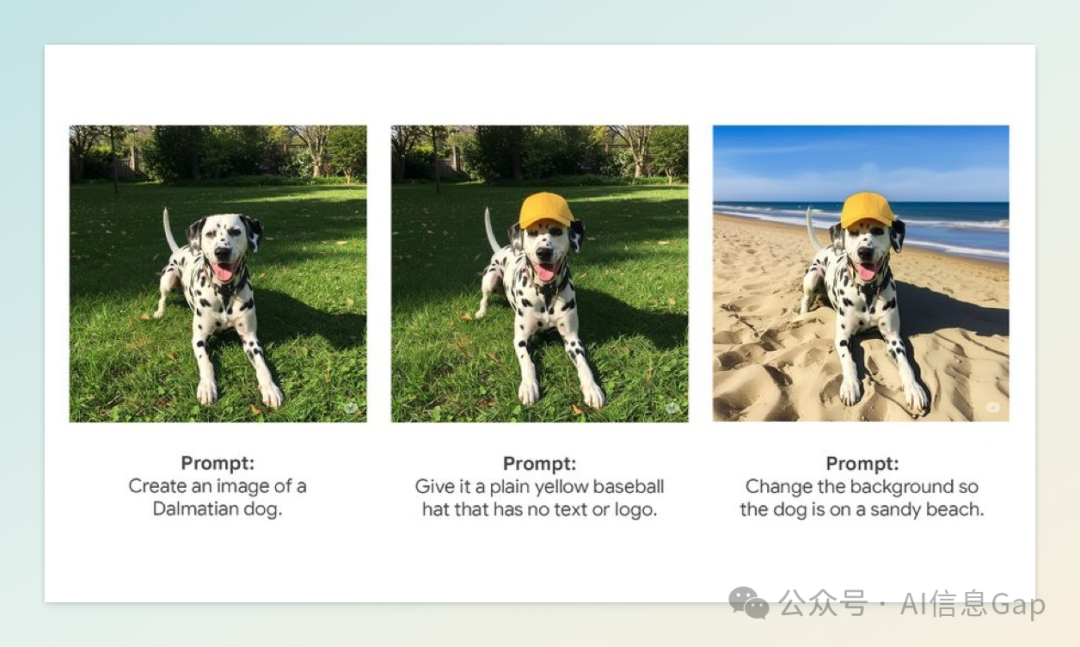
此次更新基于 Gemini 2.0 Flash 模型,支持多轮对话式图像编辑,用户可通过自然语言指令进行多步骤修改,如更换背景、替换或添加物体、调整发色等。例如,用户可以上传个人照片,并请求 Gemini 展示不同发色的效果,或生成配有插图的睡前故事草稿。
为确保图像生成的透明度与安全性,所有经 Gemini 编辑或生成的图像均嵌入了不可见的 SynthID 数字水印,谷歌还在测试添加可见水印的方案,以防止误用。
9. 谷歌 NotebookLM 移动端应用即将上线
谷歌宣布,其 AI 驱动的笔记与研究助手 NotebookLM 将于 2025 年 5 月 20 日正式登陆 Android 和 iOS 平台,届时用户可通过 App Store 和 Google Play 商店下载使用。此前,NotebookLM 仅限于桌面端使用。
NotebookLM 旨在帮助用户更高效地整理和理解复杂信息。用户可以上传 PDF、网页、YouTube 视频等多种格式的资料,系统将自动生成摘要,并通过 AI 生成的“Audio Overviews”功能,将内容转化为播客式的音频讲解,支持多语言播放,方便用户在多种场景中学习。此外,移动应用还支持创建和管理笔记本、上传新资料、离线播放音频摘要等功能,提升了学习与研究的灵活性。
值得一提的是,NotebookLM 现已升级至由 Gemini 2.5 Flash 模型提供支持,增强了其对复杂、多步骤推理问题的处理能力。同时,谷歌还推出了 NotebookLM Plus 订阅服务,提供更高的笔记本数量限制、每日查询次数和音频摘要生成次数,满足高频用户的需求。
10. 微软发布 Phi-4 系列小参数模型
4 月 30 日,微软推出全新的 Phi-4 系列小参数模型,包括 Phi-4-reasoning、Phi-4-reasoning-plus 和 Phi-4-mini-reasoning,在多个推理任务中表现出色。其中,Phi-4-reasoning-plus 模型在 AIME 2025 数学竞赛测试中取得了 82.5% 的准确率,超过了参数量高达 6710 亿的 DeepSeek R1 模型。

Phi-4-reasoning 模型通过对 OpenAI 的 o3-mini 模型生成的高质量推理示例进行监督微调,增强了其推理能力。而 Phi-4-reasoning-plus 模型在此基础上,进一步通过强化学习优化,使用了 1.5 倍于 Phi-4-reasoning 的推理时间计算资源,提升了准确性。
尽管这些模型的参数量相对较小(Phi-4-reasoning 和 Phi-4-reasoning-plus 为 140 亿,Phi-4-mini-reasoning 为 38 亿),但它们在数学、科学、编程和逻辑推理等任务中表现优异,甚至超过了一些更大规模的模型,如 DeepSeek-R1-Distill-Llama-70B。此外,这些模型已在 Azure AI Foundry 和 Hugging Face 平台上开放,采用宽松的 MIT 许可证,便于开发者进行商业和企业级应用。
11. 微软拟在 Azure 上托管马斯克的 Grok 模型
据多家权威媒体报道,微软正准备在其 Azure AI Foundry 平台上托管埃隆・马斯克旗下 xAI 公司开发的大语言模型 Grok。该平台是微软为开发者提供的 AI 应用开发环境,支持模型的部署、运行与管理。此次合作将使 Grok 模型面向微软内部产品团队和外部开发者开放,可能被集成至 Copilot、Dynamics 365 等服务中。不过,微软仅提供托管能力,不参与未来模型的训练工作。xAI 此前已终止与 Oracle 的百亿美元训练合同,转而在其位于孟菲斯的超级计算中心 Colossus 内部训练模型。

这一举措被视为微软在 AI 模型生态多元化战略中的关键一步。尽管微软是 OpenAI 的主要投资方和合作伙伴,但近年来其也在积极引入其他模型,如 Meta 的 LLaMA、DeepSeek 的 R1,以及 xAI 的 Grok,以降低对单一模型的依赖。目前,微软已将 DeepSeek R1 模型部署至 Azure 和 GitHub,供开发者使用。
值得注意的是,马斯克与 OpenAI 的关系日益紧张。他曾起诉 OpenAI 偏离非营利使命,OpenAI 随后反诉马斯克。在此背景下,微软与 xAI 的合作可能进一步加剧其与 OpenAI 的微妙关系。预计微软将在 5 月 19 日召开的 Build 开发者大会上正式宣布这一合作,届时可能公布更多细节。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)