

原文链接: https://www.philschmid.de/agentic-pattern
发布时间: 2025-05-05

这篇文章《从零到一:学习智能代理模式》探讨了AI代理系统的设计模式,这些模式作为构建AI应用的蓝图或可重用模板。

文章强调了代理的关键特性是能够动态规划和执行任务,通常利用外部工具和记忆来实现复杂目标。
作者区分了更结构化的”工作流(workflow)“和更动态的”代理模式“,指出工作流通常遵循预定义路径,而代理在决策时拥有更多自主权。文章还讨论了何时使用代理系统,建议始终寻求最简单的解决方案,并意识到代理系统常常以增加延迟和计算成本为代价来获得更好的性能。
文章概要
-
工作流模式
文章首先介绍了三种常见的工作流模式:提示链(一个LLM输出顺序输入到下一个LLM)、路由(初始LLM分类并引导到合适的专业LLM)和并行化(任务分解为同时处理的独立子任务)。这些模式适用于较为可预测的任务执行流程。
-
代理模式
然后详细探讨了四种代理模式:反思模式(代理评估自身输出并迭代改进)、工具使用模式(LLM调用外部函数与现实世界交互)、规划模式(中央规划器分解任务分配给专门工作者)和多代理模式(多个不同角色的代理协作完成任务)。这些模式提供了更多自主性和灵活性。
-
模式应用与组合
文章最后强调这些模式不是固定规则而是灵活构建块,现实世界的代理系统通常结合多种模式元素。作者建议通过经验评估来设计系统:定义指标,测量性能,识别瓶颈,并迭代改进设计,同时抵制过度工程化。
这篇文章为希望构建健壮有效的智能代理系统的开发者提供了清晰的概念框架和实用指导,展示了如何用纯API调用(不依赖特定框架)实现这些模式。
下为原文翻译
从零到一:学习智能代理模式
AI代理、智能AI、代理架构、代理工作流、代理模式,代理无处不在。
但它们究竟是什么,我们如何构建健壮有效的代理系统?
虽然”代理”一词被广泛使用,但其关键特性是能够动态规划和执行任务,通常利用外部工具和记忆来实现复杂目标。
本文旨在探索常见的设计模式。将这些模式视为构建AI应用程序的蓝图或可重用模板。理解它们为解决复杂问题和设计可扩展、模块化和适应性强的系统提供了思维模型。
我们将深入探讨几种常见模式,区分更结构化的工作流和更动态的代理模式。工作流通常遵循预定义的路径,而代理在决定行动过程中拥有更多自主权。
为什么(智能)模式很重要?
-
模式提供了一种结构化思考和设计系统的方式。 -
模式使我们能够构建并在复杂性方面发展AI应用程序,并适应不断变化的需求。基于模式的模块化设计更容易修改和扩展。 -
模式通过提供经过验证的可重用模板,帮助管理协调多个代理、工具和工作流的复杂性。它们促进开发人员之间的最佳实践和共同理解。
何时(以及何时不)使用代理?
在深入探讨模式之前,考虑何时真正需要代理方法至关重要。
-
始终寻求最简单的解决方案。如果您知道解决问题所需的确切步骤,固定工作流甚至简单脚本可能比代理更高效可靠。 -
代理系统通常以增加延迟和计算成本为代价,以在复杂、模糊或动态任务上获得潜在更好的性能。确保收益超过这些成本。 -
处理定义明确的任务且步骤已知时,使用工作流来获得可预测性和一致性。 -
当需要灵活性、适应性和模型驱动的决策制定时,使用代理。 -
保持简单(仍然):即使在构建代理系统时,也要争取最简单有效的设计。过于复杂的代理可能难以调试和管理。 -
代理引入了固有的不可预测性和潜在错误。代理系统必须纳入健壮的错误日志记录、异常处理和重试机制,让系统(或底层LLM)有机会自我纠正。
下面,我们将探讨3种常见的工作流模式和4种代理模式。我们将使用纯API调用来说明每种模式,而不依赖特定框架如LangChain、LangGraph、LlamaIndex或CrewAI,以专注于核心概念。
模式概述
我们将涵盖以下模式:
-
模式概述 -
工作流:提示链 -
工作流:路由或交接 -
工作流:并行化 -
反思模式 -
工具使用模式 -
规划模式(编排者-工作者) -
多代理模式
工作流:提示链

一个LLM调用的输出顺序地输入到下一个LLM调用。此模式将任务分解为固定的步骤序列。每个步骤由处理前一步输出的LLM调用处理。适用于可以被清晰分解为可预测、顺序子任务的任务。
用例:
-
生成结构化文档:LLM 1创建大纲,LLM 2根据标准验证大纲,LLM 3基于验证后的大纲撰写内容。 -
多步数据处理:提取信息,转换信息,然后总结信息。 -
基于精选输入生成新闻简报。
import os
from google import genai
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# --- 步骤1:总结文本 ---
original_text = "大型语言模型是在大量文本数据上训练的强大AI系统。它们可以生成类似人类的文本,翻译语言,写各种创意内容,并以信息丰富的方式回答问题。"
prompt1 = f"用一句话总结以下文本:{original_text}"
# 使用client.models.generate_content
response1 = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt1
)
summary = response1.text.strip()
print(f"摘要:{summary}")
# --- 步骤2:翻译摘要 ---
prompt2 = f"将以下摘要翻译成法语,只返回翻译,不返回其他文本:{summary}"
# 使用client.models.generate_content
response2 = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt2
)
translation = response2.text.strip()
print(f"翻译:{translation}")
工作流:路由

初始LLM充当路由器,对用户输入进行分类并将其引导到最合适的专业任务或LLM。这种模式实现了关注点分离,允许单独优化各个下游任务(使用专门的提示、不同的模型或特定工具)。通过对简单查询使用更小的模型,提高效率并可能降低成本。当任务被路由时,选定的代理”接管”完成责任。
用例:
-
客户支持系统:将查询路由到专门处理账单、技术支持或产品信息的代理。 -
分层LLM使用:将简单查询路由到更快、更便宜的模型(如Llama 3.1 8B),将复杂或不寻常的问题路由到更强大的模型(如Gemini 1.5 Pro)。 -
内容生成:将博客文章、社交媒体更新或广告文案请求路由到不同的专门提示/模型。
import os
import json
from google import genai
from pydantic import BaseModel
import enum
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# 定义路由架构
class Category(enum.Enum):
WEATHER = "weather"
SCIENCE = "science"
UNKNOWN = "unknown"
class RoutingDecision(BaseModel):
category: Category
reasoning: str
# 步骤1:路由查询
user_query = "巴黎的天气怎么样?"
# user_query = "简单解释量子物理学。"
# user_query = "法国的首都是什么?"
prompt_router = f"""
分析下面的用户查询并确定其类别。
类别:
- weather:有关天气状况的问题。
- science:有关科学的问题。
- unknown:如果类别不明确。
查询:{user_query}
"""
# 使用client.models.generate_content配置结构化输出
response_router = client.models.generate_content(
model= 'gemini-2.0-flash-lite',
contents=prompt_router,
config={
'response_mime_type': 'application/json',
'response_schema': RoutingDecision,
},
)
print(f"路由决策:类别={response_router.parsed.category},理由={response_router.parsed.reasoning}")
# 步骤2:基于路由进行交接
final_response = ""
if response_router.parsed.category == Category.WEATHER:
weather_prompt = f"为'{user_query}'中提到的位置提供简短的天气预报"
weather_response = client.models.generate_content(
model='gemini-2.0-flash',
contents=weather_prompt
)
final_response = weather_response.text
elif response_router.parsed.category == Category.SCIENCE:
science_response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents=user_query
)
final_response = science_response.text
else:
unknown_response = client.models.generate_content(
model="gemini-2.0-flash-lite",
contents=f"用户查询是:{prompt_router},但无法回答。这是理由:{response_router.parsed.reasoning}。为用户写一个有帮助的回应,让他再次尝试。"
)
final_response = unknown_response.text
print(f"\n最终响应:{final_response}")
工作流:并行化
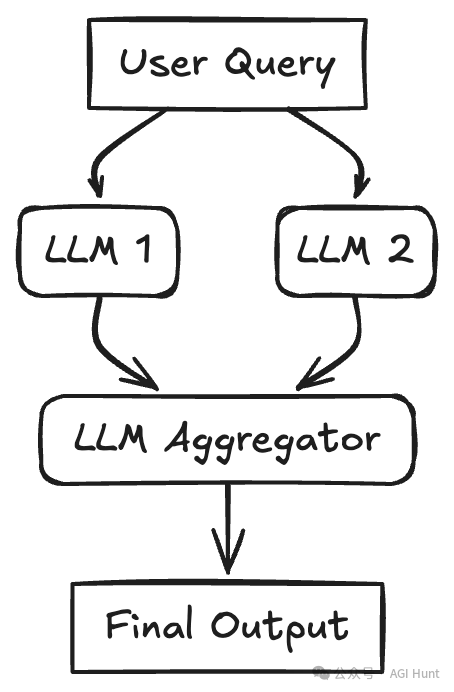
任务被分解为独立的子任务,由多个LLM同时处理,然后将它们的输出聚合。此模式对任务使用并发。初始查询(或其部分)通过单独的提示/目标同时发送给多个LLM。当所有分支完成后,收集各个结果并传递给最终的聚合器LLM,它将这些结果合成为最终响应。如果子任务不相互依赖,这可以改善延迟,或通过如多数投票或生成多样选项等技术提高质量。
用例:
-
具有查询分解的RAG:将复杂查询分解为子查询,为每个子查询并行运行检索,然后综合结果。 -
分析大型文档:将文档分为几个部分,并行总结每一部分,然后合并摘要。 -
生成多个视角:使用不同人物设定提示向多个LLM提出相同问题并汇总回应。 -
数据上的映射-减少风格操作。
import os
import asyncio
import time
from google import genai
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
asyncdef generate_content(prompt: str) -> str:
response = await client.aio.models.generate_content(
model="gemini-2.0-flash",
contents=prompt
)
return response.text.strip()
asyncdef parallel_tasks():
# 定义并行任务
topic = "一个友好的机器人探索丛林"
prompts = [
f"写一个关于{topic}的简短冒险故事创意。",
f"写一个关于{topic}的简短有趣故事创意。",
f"写一个关于{topic}的简短神秘故事创意。"
]
# 并发运行任务并收集结果
start_time = time.time()
tasks = [generate_content(prompt) for prompt in prompts]
results = await asyncio.gather(*tasks)
end_time = time.time()
print(f"耗时:{end_time - start_time}秒")
print("\n--- 个别结果 ---")
for i, result in enumerate(results):
print(f"结果{i+1}:{result}\n")
# 聚合结果并生成最终故事
story_ideas = '\n'.join([f"创意{i+1}:{result}"for i, result in enumerate(results)])
aggregation_prompt = f"将以下三个故事创意合并成一个连贯的摘要段落:{story_ideas}"
aggregation_response = await client.aio.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents=aggregation_prompt
)
return aggregation_response.text
result = await parallel_tasks()
print(f"\n--- 聚合摘要 ---\n{result}")
反思模式

代理评估自己的输出并使用该反馈迭代地完善其响应。这种模式也称为评估者-优化者,使用自我纠正循环。初始LLM生成响应或完成任务。然后第二个LLM步骤(甚至是具有不同提示的同一LLM)充当反思者或评估者,根据需求或期望质量批评初始输出。这一批评(反馈)被送回,促使LLM产生改进的输出。这个循环可以重复,直到评估者确认满足要求或达到令人满意的输出。
用例:
-
代码生成:编写代码,执行代码,使用错误消息或测试结果作为反馈来修复错误。 -
写作和改进:生成草稿,思考其清晰度和语气,然后修改。 -
复杂问题解决:生成计划,评估其可行性,并根据评估进行改进。 -
信息检索:搜索信息并使用评估者LLM检查是否找到所有必需的详细信息,然后再呈现答案。
import os
import json
from google import genai
from pydantic import BaseModel
import enum
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
class EvaluationStatus(enum.Enum):
PASS = "PASS"
FAIL = "FAIL"
class Evaluation(BaseModel):
evaluation: EvaluationStatus
feedback: str
reasoning: str
# --- 初始生成函数 ---
def generate_poem(topic: str, feedback: str = None) -> str:
prompt = f"写一首关于{topic}的简短四行诗。"
if feedback:
prompt += f"\n融入这个反馈:{feedback}"
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt
)
poem = response.text.strip()
print(f"生成的诗:\n{poem}")
return poem
# --- 评估函数 ---
def evaluate(poem: str) -> Evaluation:
print("\n--- 评估诗歌 ---")
prompt_critique = f"""批评以下诗歌。押韵好吗?是否恰好四行?
是否有创意?回答PASS或FAIL并提供反馈。
诗歌:
{poem}
"""
response_critique = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt_critique,
config={
'response_mime_type': 'application/json',
'response_schema': Evaluation,
},
)
critique = response_critique.parsed
print(f"评估状态:{critique.evaluation}")
print(f"评估反馈:{critique.feedback}")
return critique
# 反思循环
max_iterations = 3
current_iteration = 0
topic = "一个学习绘画的机器人"
# 模拟不会通过评估的诗歌
current_poem = "带着嗡嗡声的电路,冰冷而明亮,\n金属的手现在握着画笔"
while current_iteration < max_iterations:
current_iteration += 1
print(f"\n--- 迭代{current_iteration} ---")
evaluation_result = evaluate(current_poem)
if evaluation_result.evaluation == EvaluationStatus.PASS:
print("\n最终诗歌:")
print(current_poem)
break
else:
current_poem = generate_poem(topic, feedback=evaluation_result.feedback)
if current_iteration == max_iterations:
print("\n达到最大迭代次数。最后一次尝试:")
print(current_poem)
工具使用模式
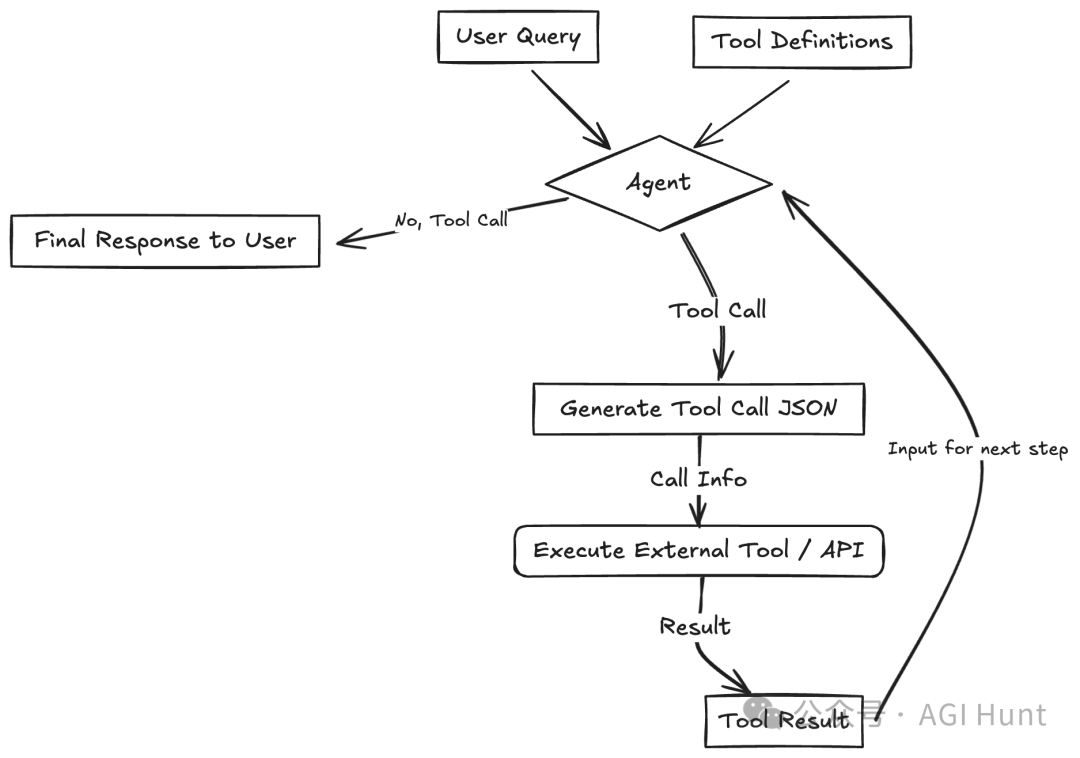
LLM能够调用外部函数或API与外部世界交互,检索信息或执行操作。这种模式通常被称为函数调用,是最广泛认可的模式。LLM提供了可用工具(函数、API、数据库等)的定义(名称、描述、输入架构)。根据用户查询,LLM可以决定通过生成匹配所需架构的结构化输出(如JSON)来调用一个或多个工具。此输出用于执行实际的外部工具/函数,结果返回给LLM。然后LLM使用此结果制定对用户的最终回应。这大大扩展了LLM超越其训练数据的能力。
用例:
-
使用日历API预订约会。 -
通过金融API检索实时股票价格。 -
在向量数据库中搜索相关文档(RAG)。 -
控制智能家居设备。 -
执行代码片段。
import os
from google import genai
from google.genai import types
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# 为模型定义函数声明
weather_function = {
"name": "get_current_temperature",
"description": "获取给定位置的当前温度。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如 旧金山",
},
},
"required": ["location"],
},
}
# 模拟API调用的占位函数
def get_current_temperature(location: str) -> dict:
return {"temperature": "15", "unit": "摄氏度"}
# 创建配置对象,如用户示例所示
# 使用带模型、内容和配置的client.models.generate_content
tools = types.Tool(function_declarations=[weather_function])
contents = ["伦敦现在的温度是多少?"]
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=contents,
config = types.GenerateContentConfig(tools=[tools])
)
# 处理响应(检查函数调用)
response_part = response.candidates[0].content.parts[0]
if response_part.function_call:
function_call = response_part.function_call
print(f"要调用的函数:{function_call.name}")
print(f"参数:{dict(function_call.args)}")
# 执行函数
if function_call.name == "get_current_temperature":
# 调用实际函数
api_result = get_current_temperature(*function_call.args)
# 将函数调用和函数执行结果附加到内容中
follow_up_contents = [
types.Part(function_call=function_call),
types.Part.from_function_response(
name="get_current_temperature",
response=api_result
)
]
# 生成最终响应
response_final = client.models.generate_content(
model="gemini-2.0-flash",
contents=contents + follow_up_contents,
config=types.GenerateContentConfig(tools=[tools])
)
print(response_final.text)
else:
print(f"错误:请求了未知的函数调用:{function_call.name}")
else:
print("响应中未找到函数调用。")
print(response.text)
规划模式(编排者-工作者)
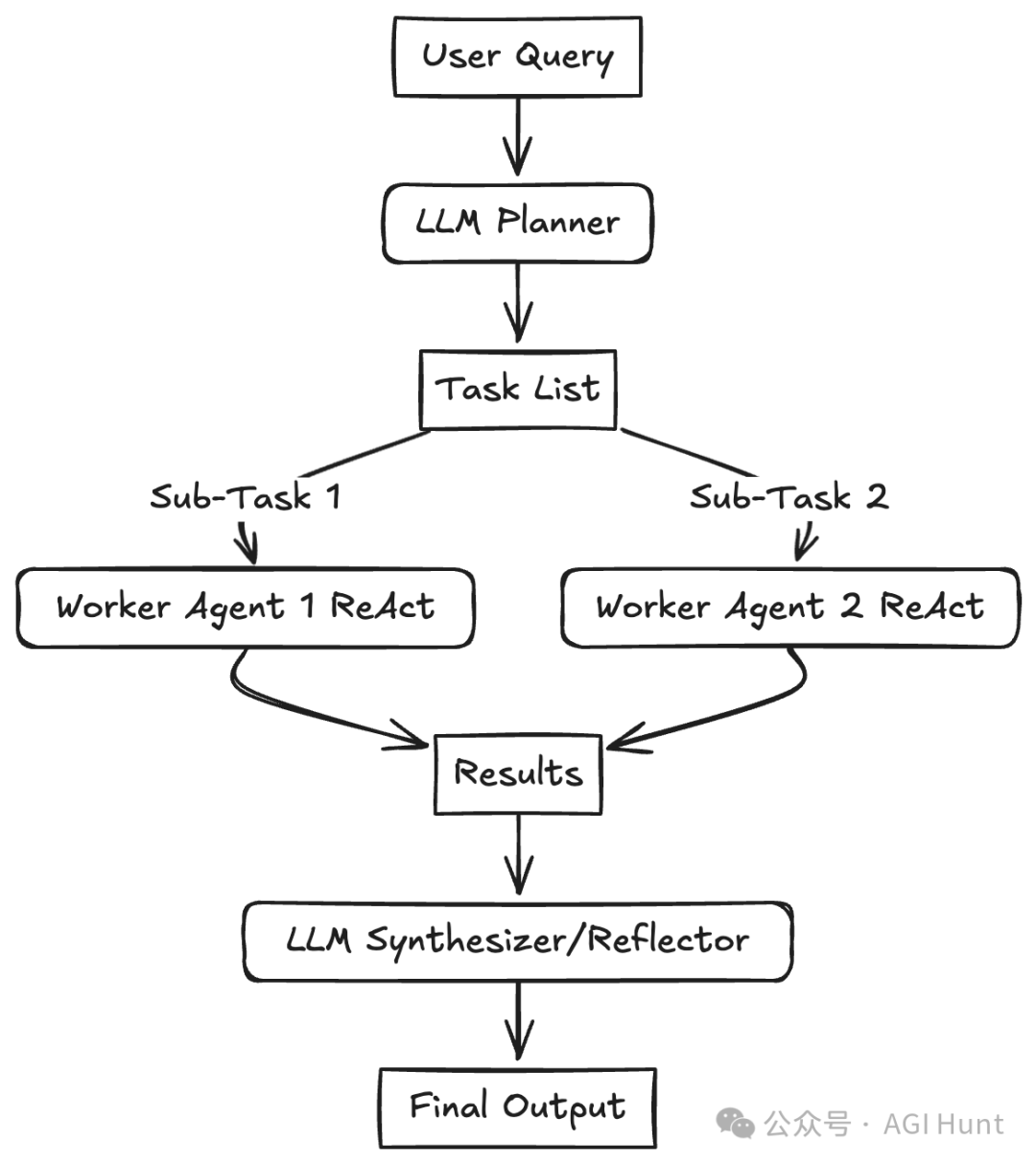
中央规划器LLM将复杂任务分解为动态子任务列表,然后将这些子任务委托给专门的工作代理(通常使用工具使用)执行。这种模式试图通过创建初始计划来解决需要多步骤推理的复杂问题。此计划根据用户输入动态生成。子任务然后分配给执行它们的”工作者”代理,如果依赖性允许,可能并行执行。”编排者”或”合成者”LLM收集工作者的结果,反思是否达成总体目标,要么合成最终输出,要么在必要时启动重新规划步骤。这减轻了任何单一LLM调用的认知负担,提高推理质量,最小化错误,并允许工作流的动态适应。与路由的关键区别在于,规划者生成一个多步骤计划,而不是选择单一的下一步。
用例:
-
复杂软件开发任务:将”构建功能”分解为规划、编码、测试和文档子任务。 -
研究和报告生成:计划如文献搜索、数据提取、分析和报告撰写等步骤。 -
多模态任务:计划涉及图像生成、文本分析和数据集成的步骤。 -
执行复杂用户请求,如”计划一个三天的巴黎之旅,预订在我预算范围内的航班和酒店。”
import os
from google import genai
from pydantic import BaseModel, Field
from typing import List
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# 定义计划架构
class Task(BaseModel):
task_id: int
description: str
assigned_to: str = Field(description="哪种工作者类型应该处理这个?例如,研究员、作家、编码员")
class Plan(BaseModel):
goal: str
steps: List[Task]
# 步骤1:生成计划(规划者LLM)
user_goal = "写一篇关于AI代理好处的简短博客文章。"
prompt_planner = f"""
创建一个分步计划来实现以下目标。
将每个步骤分配给假设的工作者类型(研究员、作家)。
目标:{user_goal}
"""
print(f"目标:{user_goal}")
print("生成计划...")
# 使用能够规划和结构化输出的模型
response_plan = client.models.generate_content(
model='gemini-2.5-pro-preview-03-25',
contents=prompt_planner,
config={
'response_mime_type': 'application/json',
'response_schema': Plan,
},
)
# 步骤2:执行计划(编排者/工作者 - 为简洁起见省略)
for step in response_plan.parsed.steps:
print(f"步骤{step.task_id}:{step.description}(分配给:{step.assigned_to})")
多代理模式
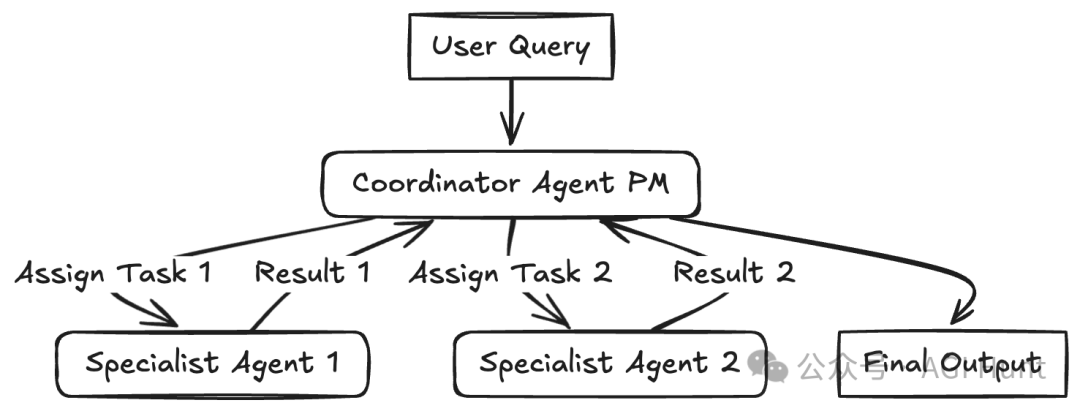
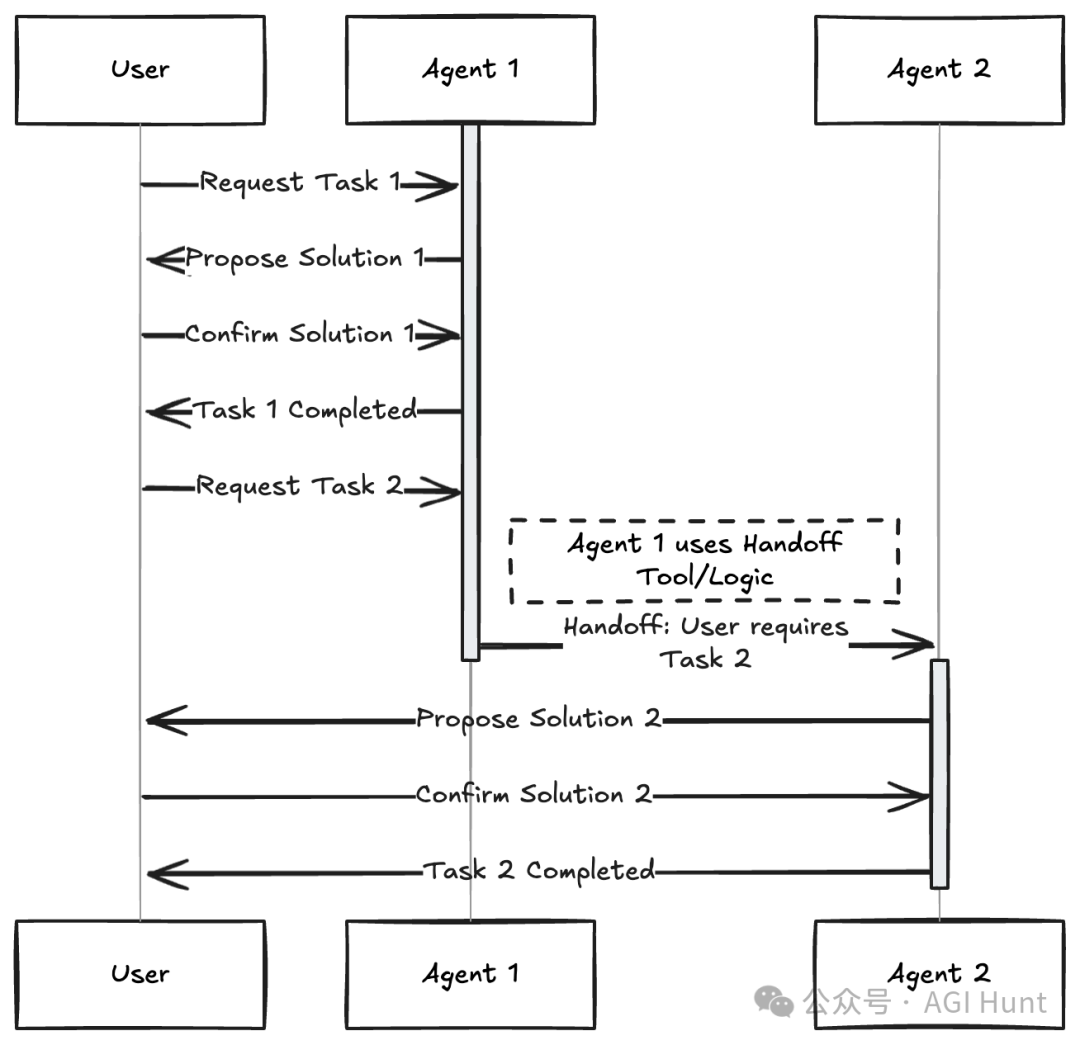
多个分配了特定角色、角色或专业知识的不同代理协作以实现共同目标。这种模式使用自主或半自主代理。每个代理可能有唯一的角色(例如,项目经理、编码员、测试员、评论员),专业知识或访问特定工具的权限。它们通过由中央”协调者”或”管理者”代理(如图中的PM)或使用交接逻辑(一个代理将控制权传递给另一个代理)进行交互和协作。
用例:
-
模拟具有不同AI角色的辩论或头脑风暴会议。 -
复杂软件创建,涉及规划、编码、测试和部署的代理。 -
运行虚拟实验或模拟,代理代表不同角色。 -
协作写作或内容创建过程。
注意:下面的示例是关于如何使用交接逻辑和结构化输出的多代理模式的简化示例。我建议查看LangGraph多代理群体[1]或Crew AI[2]
from google import genai
from pydantic import BaseModel, Field
# 配置客户端(确保环境中设置了GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# 定义结构化输出架构
class Response(BaseModel):
handoff: str = Field(default="", description="要交接给的代理的名称/角色。可用代理:'餐厅代理','酒店代理'")
message: str = Field(description="对用户的响应消息或给下一个代理的上下文")
# 代理函数
def run_agent(agent_name: str, system_prompt: str, prompt: str) -> Response:
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt,
config = {'system_instruction': f'你是{agent_name}。{system_prompt}', 'response_mime_type': 'application/json', 'response_schema': Response}
)
return response.parsed
# 为代理定义系统提示
hotel_system_prompt = "你是一个酒店预订代理。你只处理酒店预订。如果用户询问餐厅、航班或任何其他事情,请回复一个简短的交接消息,包含原始请求,并将'handoff'字段设置为'餐厅代理'。否则,处理酒店请求并将'handoff'留空。"
restaurant_system_prompt = "你是一个餐厅预订代理。你根据提示中提供的用户请求处理餐厅推荐和预订。"
# 关于餐厅的提示
initial_prompt = "你能为今晚2人预订一张意大利餐厅的桌子吗?"
print(f"初始用户请求:{initial_prompt}")
# 运行第一个代理(酒店代理)以强制交接逻辑
output = run_agent("酒店代理", hotel_system_prompt, initial_prompt)
# 模拟用户交互以更改提示和交接
if output.handoff == "餐厅代理":
print("触发交接:酒店到餐厅")
output = run_agent("餐厅代理", restaurant_system_prompt, initial_prompt)
elif output.handoff == "酒店代理":
print("触发交接:餐厅到酒店")
output = run_agent("酒店代理", hotel_system_prompt, initial_prompt)
print(output.message)
组合和定制这些模式
重要的是要记住,这些模式不是固定规则,而是灵活的构建块。现实世界的代理系统通常结合多种模式的元素。规划代理可能使用工具使用,其工作者可能采用反思。多代理系统可能在内部使用路由进行任务分配。
组合和定制这些模式
任何LLM应用程序,尤其是复杂的代理系统的成功关键是经验评估。定义指标,测量性能,识别瓶颈或失败点,并迭代您的设计。抵制过度工程化。
致谢
本概述是在深入手动研究的帮助下创建的,从几个优秀资源中汲取灵感和信息,包括:
-
5种代理AI设计模式[3] -
什么是代理工作流?[4] -
构建有效的代理[5] -
代理如何提高LLM性能[6] -
代理设计模式[7] -
代理食谱[8] -
LangGraph代理概念[9] -
OpenAI代理Python示例[10] -
Anthropic Cookbook[11]
参考资料
LangGraph多代理群体: https://github.com/langchain-ai/langgraph-swarm-py
[2]Crew AI: https://www.crewai.com/open-source
[3]5种代理AI设计模式: https://blog.dailydoseofds.com/p/5-agentic-ai-design-patterns
[4]什么是代理工作流?: https://weaviate.io/blog/what-are-agentic-workflows
[5]构建有效的代理: https://www.anthropic.com/engineering/building-effective-agents
[6]代理如何提高LLM性能: https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance
[7]代理设计模式: https://medium.com/@bijit211987/agentic-design-patterns-cbd0aae2962f
[8]代理食谱: https://www.agentrecipes.com/
[9]LangGraph代理概念: https://langchain-ai.github.io/langgraph/concepts/agentic_concepts/
[10]OpenAI代理Python示例: https://github.com/openai/openai-agents-python/tree/main/examples/agent_patterns
[11]Anthropic Cookbook: https://github.com/anthropics/anthropic-cookbook/blob/main/patterns/agents
(文:AGI Hunt)