

邮箱|damoxingjidongzu@pingwest.com
在近日红杉资本举办的 AI Ascent 2025 演讲中,NVIDIA 人工智能总监 Jim Fan 介绍了“物理图灵测试”的概念,并解释了大规模仿真将如何解锁机器人技术的未来。我们针对其演讲内容进行了梳理,并进行了编译:
Jim Fan:
几天前,我看到一篇博客文章,它引起了我的注意。文章说大模型已经通过了图灵测试,但却没人注意到。图灵测试曾经是神圣不可侵犯的,对吧?它是计算机科学的圣杯,其理念是,你无法区分与你对话的是人类还是机器。
然后,我们就这么悄无声息地通过了图灵测试。但当机器思考的时间多了几秒钟,或者云端无法调试你糟糕的代码时,人们就会感到不满。每一次突破都在平淡无奇中度过,就像又一个普通的周二。
我想提出一个非常简单的概念,叫做 “物理图灵测试”。设想一下,周日晚上你举办了一场黑客马拉松派对,周一早上,你想找人收拾这一片狼藉,并且在晚餐时为你点上一支精美的蜡烛让你的伴侣开心起来。而当你回到家时,却无法分辨这一切是人类还是机器的杰作。
这就是简单的物理图灵测试。但我们现在进展到什么程度了呢?快实现了吗?看看这个类似的机器人,准备去工作,结果却没能做好。再看看机器狗面对香蕉皮的场景,还有被指令为你制作早餐麦片的机器人呢?

它能正确识别牛奶,这一点我给它勉强及格。它的意图是好的,或者说用勺子的体验就像是贵宾级的。看看,我都有点嫉妒了,都没人能给我这样的体验。这就是我们目前的现状。那么,为什么解决物理图灵测试这么困难呢?
大家都知道,研究人员经常抱怨。最近,有个叫ilia的人抱怨说,预训练的数据快用完了。他甚至把互联网比作人工智能的 “化石燃料”,还说我们用于训练网络的数据即将耗尽。只要和机器人专家相处一天,就知道那些深度学习研究人员有多 “娇惯” 了。

我们连 “化石燃料” 都没有。这是在英伟达总部的咖啡馆进行的数据收集场景。设置了人形机器人,通过操作它们来收集数据。
这就是收集到的数据,机器人的关节控制信号,这些是随时间变化的连续值,无法从互联网上获取,在维基百科、YouTube 或其他任何地方都找不到。人们必须自己收集。那要怎么收集的呢?有一种非常复杂但也很昂贵的方法,叫做 “远程操作”。让人戴上虚VR头盔,头盔能识别手部动作,并将动作信号传输给机器人。
通过这种方式,人类可以教机器人做事,比如从烤面包机里拿出面包,然后在上面淋上蜂蜜。但可以想象,这是一个非常缓慢且痛苦的过程。

真正的机器人数据是 “人力燃料”,而这比化石燃料还糟糕,因为这是在消耗人力。更糟糕的是,每个机器人每天最多只能运行 24 小时,甚至实际过程中远远达不到这个时长,因为人会累,机器人比人更容易累。
这就是现状,那该怎么办呢?如何突破这个障碍?机器人领域的 “核能” 在哪里?我们需要清洁能源,不能永远依赖 “化石燃料”。于是,模拟技术登场了。
必须离开现实世界,在模拟环境中做点什么。所以尝试让机器人的手在模拟环境中完成超越人类灵巧度的任务,比如转笔。对我来说这是超人类的技能,因为我小时候就放弃尝试转笔了。
我很高兴机器人至少在模拟环境中比我做得好。那么如何训练机器人的手完成这样复杂的任务呢?有两个思路。第一,模拟速度要比实时快 10000 倍,这意味着在单个 GPU 上并行运行 10000 个物理模拟环境。这是第一点。第二点是,这 10000 个模拟环境不能完全相同,必须改变一些参数,比如重力、摩擦力和重量,我们称之为 “域随机化”。这就是模拟的原理。

为什么这样做有效呢?想象一下,如果一个神经网络能够控制机器人在 100 万个不同的世界中完成任务,那么它很有可能也能应对第 100 万零一个世界,也就是现实世界。
换句话说,现实世界是这些训练场景的一部分。那么如何应用呢?可以创建一个数字孪生体,也就是机器人和现实世界 1:1 的复制体。然后在训练模拟中进行测试,再直接应用到现实世界,实现零样本学习。
可以用手来举例。这是能完成的最令人印象深刻的任务之一。比如让机器狗站在球上,然后将训练成果应用到现实世界。这是在加州大学伯克利分校(UCB),有人在操控机器狗行走。研究人员想法很奇特,这场景看起来就像《黑镜》里的情节。
实际上,这被称为 “尤里卡博士” 项目。有个研究人员让他的机器狗站在瑜伽球上,至少现在在机器狗的灵活性方面取得了很大进展,不过真正的狗可做不到。接下来,还可以将这种方法应用到更复杂的机器人上,比如人形机器人。

这些人形机器人通过 2 小时的模拟训练,就掌握了相当于现实中 10 年才能学会的行走技能,并可以将训练成果应用到现实中。无论机器人的形态如何,只要有机器人模型,进行模拟训练,就可以让它学会行走。
能做的不止是行走,对吧?当控制身体时,可以追踪任何想要追踪的点、任何关键部位,跟随任何想要的速度向量。这就是人形机器人的全身控制问题。
这非常困难,但可以通过并行运行 10000 个模拟环境来进行训练。将训练成果零样本、无需微调地应用到现实机器人上,这是在英伟达实验室。实际上,需要放慢视频播放速度。
第一个视频是实时播放的,下一个视频是放慢后的。可以看到机器人动作的复杂性,它在保持平衡的同时做出类似人类的敏捷动作。猜猜完成这些动作需要多大规模的神经网络?
只需要 150 万个参数,不是几十亿,150 万个参数就足以捕捉人体的潜意识处理过程。这个系统的推理过程,150 万个参数就够了。如果将其放在速度与模拟多样性的图表中,我认为这可以称为 “模拟 1.0”,也就是数字孪生范式,它使用经典的矢量化物理引擎。
然后可以将模拟速度提升到每秒 1 万到 100 万帧。但问题是,必须创建数字孪生体,需要有人构建机器人、搭建环境等等。这非常繁琐,而且需要大量手工操作。
能不能开始生成模拟的部分内容呢?所有这些 3D 资源都是由 3D 生成模型生成的,所有的纹理来自 Stable Diffusion 或其他扩散模型,所有的场景布局由提示词和语言模型生成,再编写 XML 将它们整合在一起,构建了一个名为 “Robot-CASa” 的框架,这是一个大规模的合成模拟框架。
它用于模拟日常任务,除了机器人,其他内容都是生成的。可以组合不同的场景,它仍然依赖经典引擎运行,但已经可以完成很多任务。
现在,可以再次让人进行远程操作,但这次是在模拟环境中,而不是在现实机器人上。在模拟环境中重现操作轨迹,并且加入强大的硬件加速光线追踪技术,让模拟场景更加逼真。

甚至可以改变动作。比如在远程操作时将杯子从这里移动到那里,不需要反复演示同样的动作。综合这些,在模拟环境中进行一次人类演示,通过环境生成和动作生成,将数据量扩展 n 倍,再乘以 n 倍。我保证这是今天需要接触的唯一数学计算。这就是扩充数据的方法。第一列和第三列是现实机器人的真实视频,第二列到第四列是 Robot-CASa 模拟生成的视频。
仍然可以看出这些纹理不是真实的,但已经足够接近了。把这种足够接近的情况称为什么呢?称之为 “数字表亲” 范式。它不是数字孪生体,但在一定程度上捕捉到了相似性。这种数字表亲模拟运行速度较慢,但它是一种混合生成物理引擎,生成部分内容,然后将其余部分交给经典图形管道处理。

现在,模拟包含软体、流体等各种元素的场景,对于艺术家或图形工程师来说,要正确模拟这样的场景需要很长时间。看看图形技术的发展历程,从早期到现在花了 30 年时间。
而视频联合模型只用了 1 年时间,就实现了从模拟简单物体到模拟可变形物体(比如面条)的跨越。这里可能少了点趣味性,但这是我愿意付出的代价。对于最新的 Sora 等策略模型,也只用了 1 年时间,这就是规模扩展和数据驱动过程的力量。
还记得一开始给你们看的视频吗?这个视频里没有一个真实像素,它完全是由定制模型生成的。使用一个通用的开源 VR 视频生成模型,在现实机器人实验室收集的领域数据上进行微调,然后生成了这些内容。现在,可以通过提示词让模型想象不同的未来场景,模拟反事实情况。看,这两帧画面原本完全相同,但根据不同的语言提示,生成的视频会做出正确的反应。
即使这些动作在现实世界中从未发生过,也能实现。视频扩散模型并不在乎场景有多复杂,也不在乎是否有流体或软体。
同样地,可以让它拿起不同的东西,它会用正确的手抓取物体并放入篮子里。这些都是生成的,没有一个像素是真实的。它还能正确模拟出各种反射效果,对吧?

所有这些交互效果都能正确模拟。我最喜欢的一个场景是机器人在那边弹尤克里里。基本上,视频模型可能看过数百万人类弹尤克里里的画面,然后它就能模拟机器人的手指做出相应动作,即使硬件实际上并不支持。视频生成模型就能做到这一点。从这个角度来看,这就是 “模拟 2.0”。
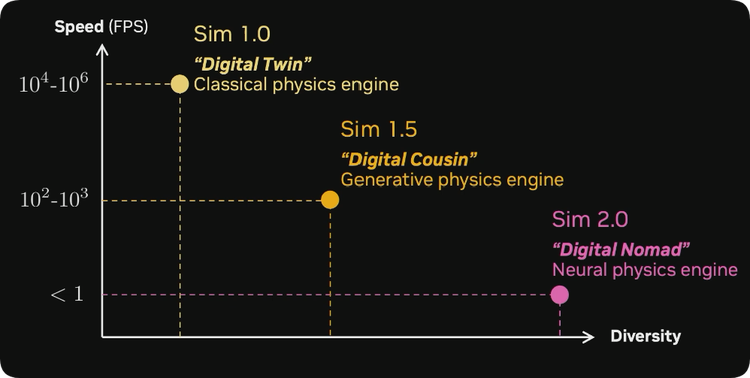
它具有很高的多样性,但目前运行速度可能较慢。没人给它起名字,但我叫它 “数字游牧民”,它就像是在视频扩散模型的梦幻空间里漫游。
什么是视频扩散模型呢?它就像是将数亿个互联网视频压缩成一个多元宇宙的模拟场景。很神奇,对吧?在这个梦幻空间里创建机器人,机器人现在可以与任何地方的物体进行交互,无处不在,无所不能。
詹森之前离开了,但我觉得他会很喜欢这个。要扩展经典模拟,需要大量的计算资源,这也是 1.x 系列的情况。问题是,随着规模的扩大,它会遇到瓶颈,因为手工制作的系统在多样性方面存在限制。
而神经世界模型,也就是模拟 2.0,将随着计算资源呈指数级扩展。这就是神经网络超越经典图形工程师的地方。两者相加,将成为扩展下一代机器人系统的 “核能”。

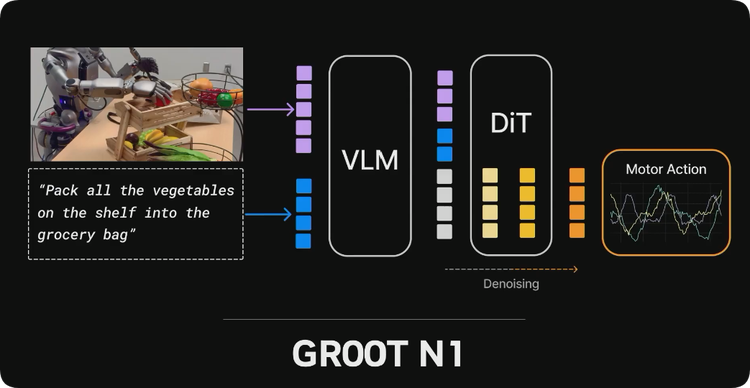
那些一开始就说计算机状况会改善而不是恶化的人,把这句话刻在视网膜上,再好好想想吧。把所有这些数据输入到所说的视觉语言动作模型中,这个模型输入像素和指令,输出电机控制信号。
在 3 月英伟达 GTC 大会约翰逊(Johnson)的主题演讲中开源了一个名为 Groot 的模型。在机器人上运行这个模型,有时候会有很神奇的效果。无法想象在训练过程中清理了多少数据。它能够完美地拿起香槟,做得非常好。
它还能完成一些工业任务,比如拿起工厂里的物品,也能实现多机器人协作。Groot 模型是完全开源的,实际上,未来的一系列模型也将开源,因为遵循约翰逊的开源理念,致力于让物理人工智能更加普及。
那么接下来呢?在看到物理人工智能的发展后,下一步是什么?我认为是物理 API。纵观人类历史,5000 年来,我们拥有了更好的工具,社会也在整体上有了很大进步。但做晚餐以及进行很多手工劳动的方式,从埃及时代到现在,或多或少都没有太大变化。
在人类历史的 99% 时间里,一直遵循这样的模式:从原材料出发,通过人类劳动构建文明。而在过去的 1%,也就是大约 50 年里,人类劳动占比逐渐减少,出现了高度专业化、高度复杂的机器人系统,它们一次只能完成一项任务。
编程成本非常高,但它们仍然在社会中发挥着作用。这就是现状。未来是要把代表机器人劳动占比的区域扩展到各个领域,就像语言模型 API(LLM API)处理数字和比特一样,物理 API 将处理原子。
基本上可以给软件配备物理执行器,让它改变物理世界。在物理 API 之上,将会出现新的经济模式和新的范式,比如物理提示。如何指令这些机器人?如何训练它们?
有时候语言是不够的。还会有物理应用商店和技能经济。比如说,米其林星级厨师不必每天都去厨房,他可以训练机器人,然后将提供米其林星级晚餐作为一种服务。再引用一次约翰逊的话:未来,一切可移动的物体都将实现自动化。
有一天,回到家,会看到干净的沙发和点着蜡烛的晚餐,伴侣会微笑着迎接,而不是因为没洗衣服而大喊大叫,这一点每天都激励着我。上个月买了两个人形机器人,它们运行良好。
这些机器人就像环境智能一样融入背景,甚至不会注意到通过物理图灵测试的那一刻。而那一天,也只会被当作又一个普通的周二被人们记住。谢谢大家。

(文:硅星GenAI)