
微软在官网开源了三个新版Phi-4小参数模型,分别是Reasoning、Min-Reasoning和Reasoning-plus。
Reasoning是基于Phi-4开发而成,mini版本适用于平板、手机等移动设备,而plus是强化学习版本,针对数学等特定领域进行了强化训练。
这三款模型的最大亮点之一便是算力消耗非常低,可以直接在消费级硬件环境上运行,以普通的 Windows 11设备为例,无论是CPU还是GPU,都能轻松实现本地部署。同时微软已经将Phi-4系列模型深度融入Windows系统生态,使其成为Copilot+PC的重要组成部分。
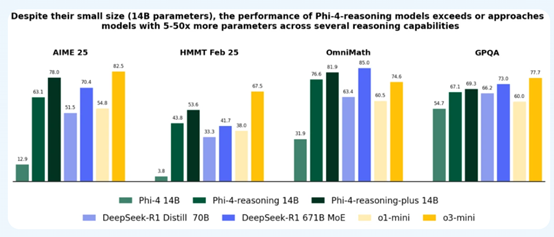
根据测试数据显示,Phi-4-Reasoning-plus版本只有140亿参数,但与DeepSeek开源的R1 6710亿参数相比性能几乎差不多,例如,在美国数学奥林匹克竞赛资格赛2025中,Reasoning-plus得分为78,R1为70.4;
哈佛–麻省理工数学竞赛Reasoning-plus为53.6,R1为41.7;Ominimath的测试中,Reasoning-plus为81.9,R1为85;GPQA中Reasoning-plus为69.3,R1为73,成为目前最强的开源小参数模型。
开源地址:https://huggingface.co/microsoft/Phi-4-reasoning
https://huggingface.co/microsoft/Phi-4-mini-reasoning
https://huggingface.co/microsoft/Phi-4-reasoning-plus
Phi-4-Reasoning的基础架构源自微软开源的Phi-4 模型,为了提升其推理能力,微软通过监督微调和强化学习相结合的训练方法行了深度强化。
该方法的核心在于,先通过监督微调让大模型学习高质量的推理演示数据,从而生成详细的推理链,并能够有效地利用推理时的计算资源。优点类似于给模型提供了一个“标准答案”,让模型知道如何正确地进行推理。

但仅依靠监督微调是不够的,因为模型可能在某些领域仍然存在不足。微软又引入了强化学习阶段,尤其是对数学推理等特定领域帮助非常大。强化学习阶段通过奖励函数引导模型生成更准确、更深入的推理链,主要为模型提供了一个“奖励机制”,鼓励模型在推理过程中更加努力地思考,从而提高推理的准确性和深度。
Phi-4-Reasoning模型在推理标记与长推理链支持方面也进行了创新。为了更好地支持推理过程,模型引入了特定的推理标记<think> 和 </think>,用于标识推理链的开始和结束。
相当于给模型提供了一个“思考的框架”,使得模型能够更清晰地组织推理过程,并在生成推理链时更加注重推理的逻辑性和连贯性。
同时,模型的最大支持令牌长度从16K提升至32K,为长推理链的生成提供了足够的“思考空间”。使得模型能够处理更复杂的推理任务,而不会因为推理链过长而受限。
此外,微软发现使用高质量和合成数据对于训练模型非常重要,于是从多个渠道收集了大量问题,包括公开网站、现有数据集。这些数据涵盖了数学、科学、编程以及与安全相关的任务等多个领域。

还通过合成数据生成技术,将部分问题转换为新的形式。例如,将编程问题转换为文字问题,或者对数学问题进行改编,以更好地适应推理训练的需求。这种数据策划和合成策略不仅丰富了训练数据的内容,还为模型提供了更多样化的学习场景,从而提升了模型的泛化能力。

(文:AIGC开放社区)