

今天是2025年5月13日,星期二,北京,晴。
我们来看两个工作,一个是RAG进展,看一个多模态路由检索思路。
另一个是文档信息抽取框架ContextGem剖析,看看它具体怎么做的,有什么不足,有什么优势,实现逻辑设计,这对于工程设计会有一些借鉴意义。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、UniversalRAG路由多模态检索思路
先看看多模态RAG进展,《UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities》,https://arxiv.org/pdf/2504.20734,https://universalrag.github.io,核心思想是通过动态识别和路由查询到最合适的模态和粒度知识源来进行检索,是个单分类任务,包括无检索(None)、段落(Paragraph)、文档(Document)、图像(Image)、片段(Clip)、视频(Video)6个。

有几个点可以重点看看。
一个是路由是个啥?
给定一个查询q,Router预测与查询相关的模态信息:{无检索(None)、段落(Paragraph)、文档(Document)、图像(Image)、片段(Clip)、视频(Video)},然后再进行相应检索操作。

注意,为了配合这种检索,就需要得到‘Paragraph’,‘Document’, ‘Image’, ‘Clip’, ‘Video’这几种数据信息,例如:
对于文本模态,构建段落级和文档级语料库Cdocument={d1,…,dl} ,其中每个d是通过连接多个段落并编码生成文本得到的文档的向量表示;
对于视频模态,构建片段级和完整视频级语料库。片段级别的语料库Cclip={k1,…,kp} ,其中每个k表示从原始全长视频中提取的裁剪视频片段的表示。
由于图像本身是细粒度的,不对图像语料库进行额外的分割,并保持其原样。
2、怎么做路由?
一个是直接不训练,直接提示大模型(GPT-4o)做,给定一个查询q,通过详细的指令描述路由任务,并附带几个上下文中的示例,然后预测最合适的检索类型,从六个预定义选项中选择,例如使用如下的prompt:

另一个是使用训练的方式,去做一个路由,这个还好做,训练Dis-tilBERT、T5-Large就行,核心是怎么做数据,做数据的思路可以看看,如下:
对于文本QA,仅基于模型参数知识回答的数据集中的查询被标记为‘None’;
单跳RAG中的查询被标记为‘Paragraph’;
多跳RAG中的查询被标记为‘Document’;基于图像的RAG基准中的查询被标记为‘Image’;
对于视频QA,关注视频中局部事件或特定时刻的查询,例如在特定时间戳识别一个动作——被标记为‘Clip’,而需要理解完整故事情节或更广泛的时间上下文的查询被标记为‘Video’;
使用此构建的数据集,在推理时训练路由器以预测给定查询的适当检索类型。
2、 检索后如何做生成
注意,这里使用的多模态模型在做,例如,InternVL2.5-8B 、Qwen2.5-VL-7B-Instruct以及Phi-3.5-Vision-Instruct。
LVLM在检索内容c的基础上生成最终响应a,这反映了为给定查询q确定的最合适模态和粒度。
此外,如果不需要检索(即c=None),LVLM直接根据q生成响应,而无需任何其他上下文。
但是,这个工作比较奇怪的点是,我们真的在做的时候,其实并不会选择单一模态去做,而是会想着说,尽可能将多种模态的数据都混合起来。所以,这个工作给我们更多的意义,其实是怎么针对不同的模态做建库处理。
二、文档信息抽取框架ContextGem剖析
文档提取工具进展,ContextGem:文档中结构化数据提取框架,http://github.com/shcherbak-ai/contextgem,https://contextgem.dev/,我们可以在https://deepwiki.com/shcherbak-ai/contextgem/2.3-document-pipeline中找到几个详细的说明。事实上,对于抽取这事情,需要很严肃,对结果负责。
1、ContextGem是什么?
ContextGem用于从单个文档中提取结构化数据的框架,利用LLM的长上下文窗口来抽取相应信息,不是一个RAG,也不是一个Agent。
为了说明它的优势,所以在https://contextgem.dev/中把langchain、LangChain、LlamaIndex、LlamaIndex (RAG)以及Instructor几个拉出来对比,

对染可以使用这些框架,来指定搭建相应的抽取工作流workflow,但是很繁琐,不够丝滑。

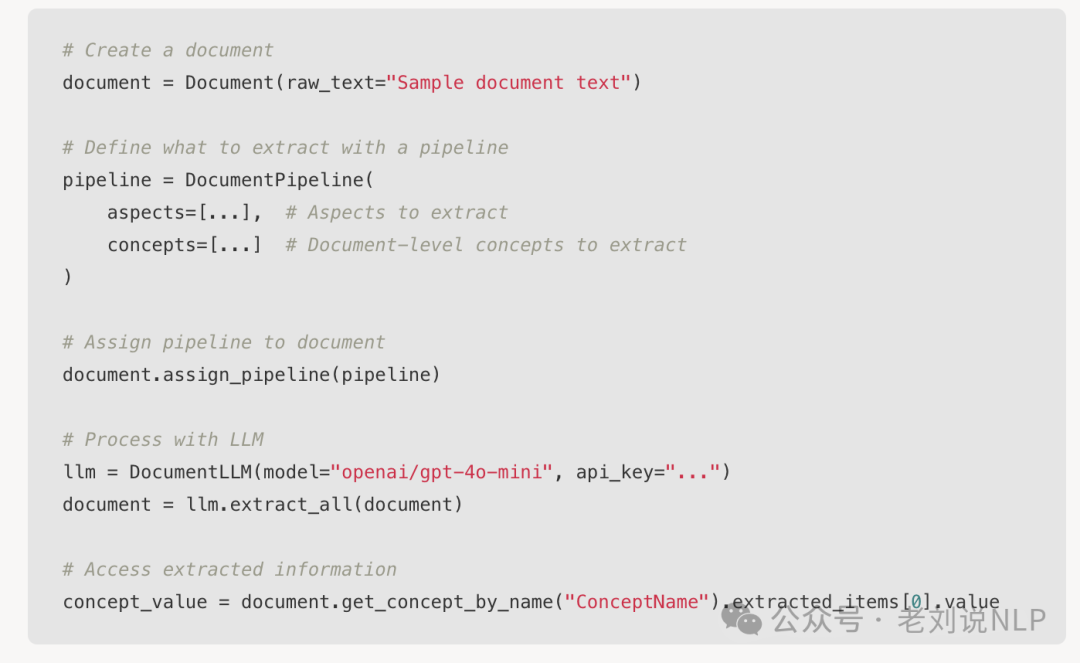
2、ContextGem仅支持docx格式的解析
ContextGem就是一个自动化抽取文档结构化信息抽取的框架,但是一旦要做文档结构化抽取,则需要解决几个问题。首先是文档预处理,文档有很多种格式,有docx,pdf,excel,ppt等等,需要将这些进行转换。
但是ContextGem只支持docx解析,将docx文件,直接解析Word XML来处理从DOCX文件中提取文本、格式、表格、图像、脚注、注释和其他元素。转为markdown,https://contextgem.dev/converters/docx.html;
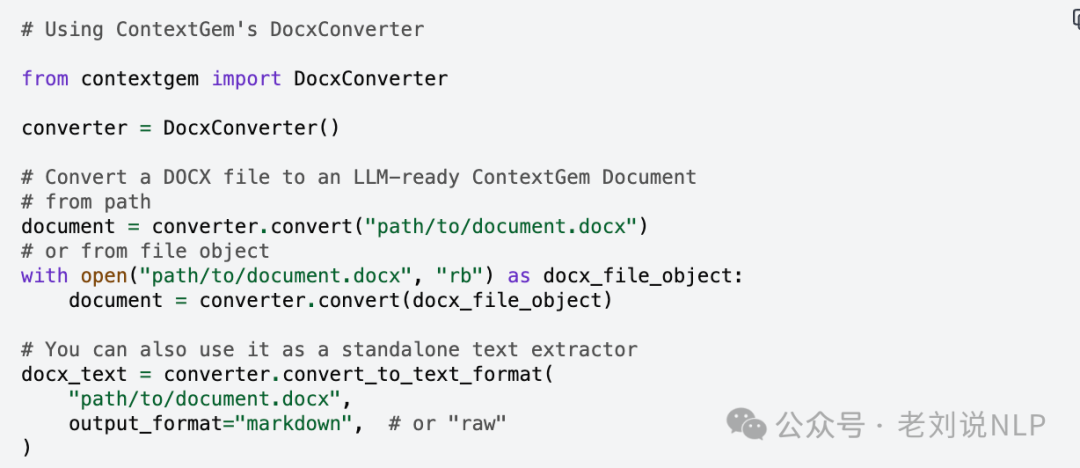
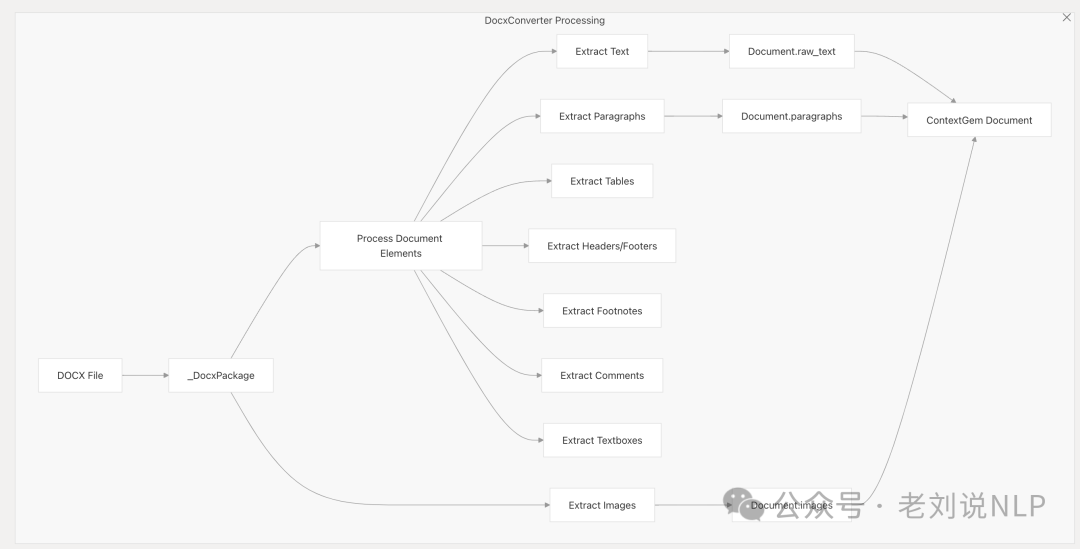
抽取出Text、Paragraphs、Headings、Lists、Tables、Headers & Footers、Footnotes、Comments、Text Boxes、Images等要素。
所以ContextGem可以当作一个docx的文档解析工具来用,所以如果真要用,我们其实还有很多工作可以做,来支持更多的文档类型。
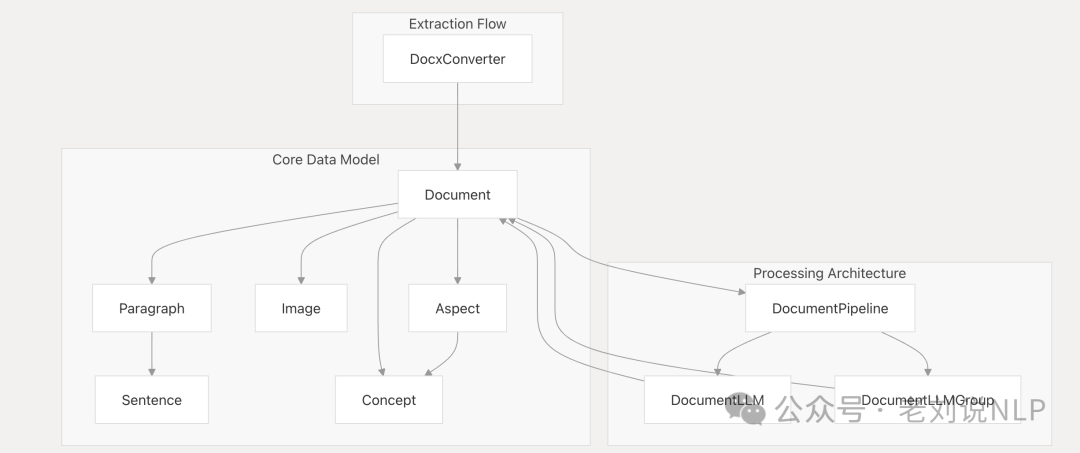
这种好处在于,完整的文档元素提取,提取文本、表格、注释、脚注、页眉、页脚、文本框和图像;维护文档结构,包括标题、列表和表格格式;向段落添加详细的上下文元数据,以提高LLM理解,输出原始文本或markdown格式的文本。
3、ContextGem搭了一套可以溯源的文档信息抽取流程
另一个是抽取的问题。抽取的话,一般都是需要给定特定的schema,比如一个人,要抽取出姓名、出生日期、工作地点等,然后结构化输出。
但这并不是万事大吉,在抽取之外,还需要给出抽取文本的来源位置,是来自于哪个句子、段落、文章,甚至是哪个图片?
抽取之后还需要进行校验,对齐、聚合等等,尤其是涉及到事件抽取的时候,其实怎么把事件要素都对齐到一个事件上,以及当一个文本中存在多个人的时候,怎么把抽取出来的这些字段信息都准确归类到这个人身上,这都是需要做处理操作的。
但是,显然,ContextGem在这个方面,还是十分初级。没有解决抽取之后还需要进行校验,对齐、聚合这些问题,会导致使用很demo化,但在抽取来源跟踪、抽取结构化信息上,也提供了自己的方案【虽然不是最优解】,在数据流转和数据抽取组织上,设计了一套抽取流程
其中,在数据的组织上,有个三层的概念:Document->Aspect->concept,分成多级关系,也可以当成一个文件存储结构,这种结构可以很好做定位跟踪。
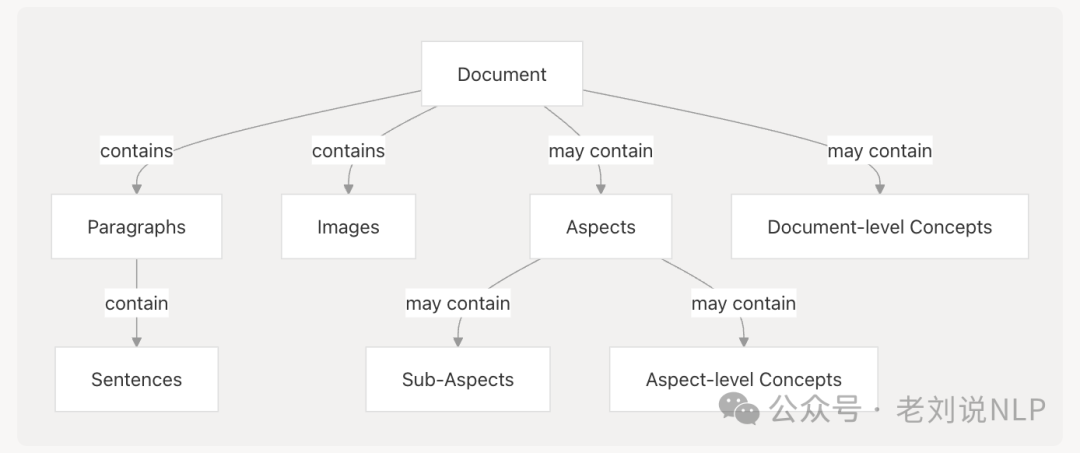
Document(含代表特定文档的文本和/或视觉内容) 。例如,合同:定义条款和义务的法律协议;发票:详细说明交易和付款的财务文件;个人简历(CV):概述个人专业经验和资历的简历;一般文档:任何其他可能包含文本或图像的文档类型。
Aspect(表示文档中需要重点关注的特定领域或主题(或其他方面)的文本),每个方面都反映了一个特定的主题。 例如:合同:付款条款、涉及的各方或终止条款;发票:到期日、项目明细或税务详情; 简历:工作经验、教育背景、或技能。这个相当于找到待提取数据的相关文本段落,待提取的位置,是一个过滤操作;

**concept(具体的抽取的实体、字段值)**,例如,一个人的毕业院校、年纪、任职公司。
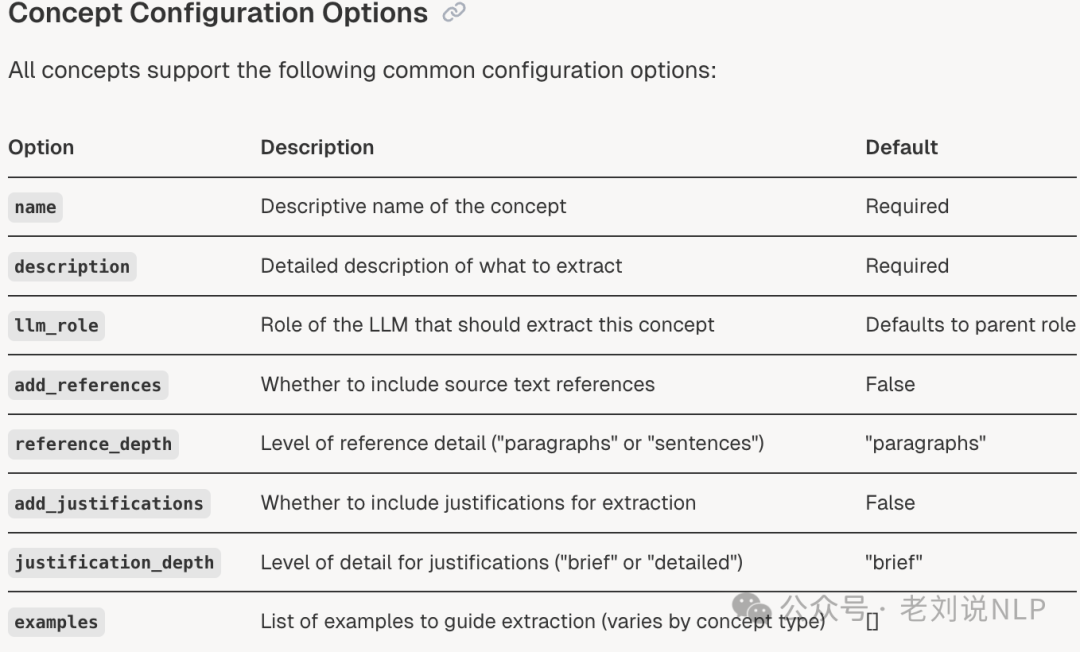
然后再进行抽取时,流程如下:

具体的数据流程如下:
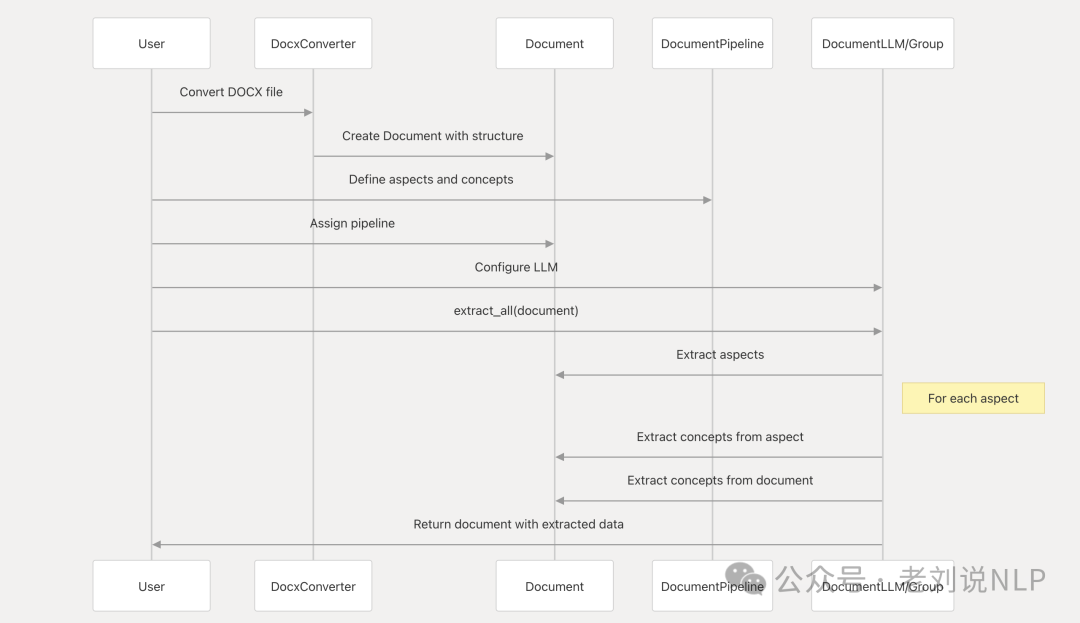
4、ContextGem集成不同的模型适配到不同抽取任务
当然,更进一步地,对于抽取而言,抽取的广度。针对不同的抽取目标,可以配置不同的抽取模型,例如有图片内容的提取(解析),也有需要判定式的抽取(分类),会就会涉及到extractor_text、reasoner_text、extractor_vision,如下图:

可以配置选择不同的模型API,选择特定的模型,根据特定的任务,当然,这个需要自行进行设定;

进一步的,抽取过程,除了抽取过程,还包括调用llm的消耗统计信息等等。
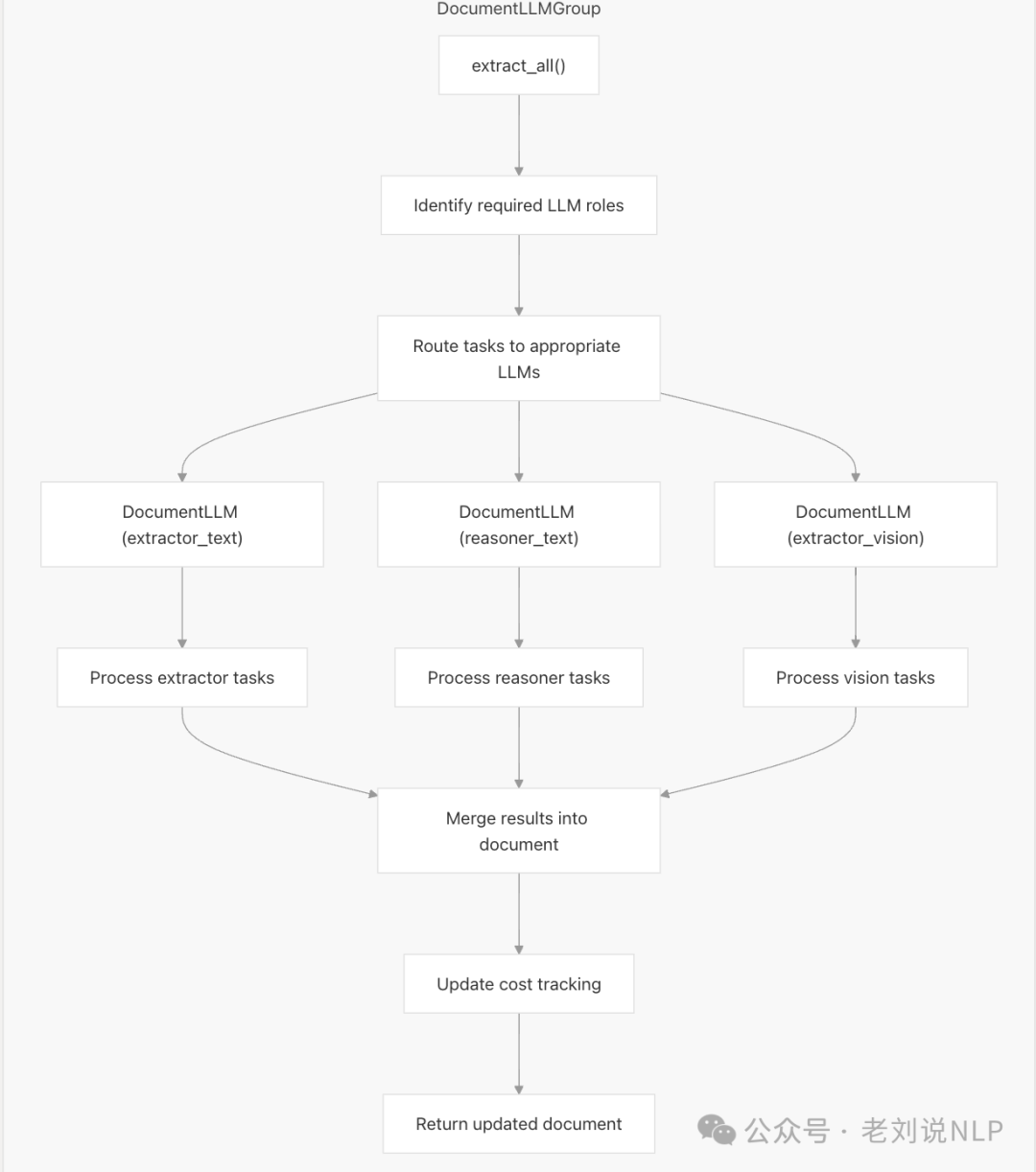
所以,以上几点来看,可以总结下。
先说不足:
1)只支持docx,其他格式不支持,可以补充开发,docx在文档抽取场景其实并不那么多见。
2)没有后续处理的逻辑(消歧等)、存储、校验等,流程搭的很全,但是对于抽取这个事情不是很严肃,尤其是在对抽取结果的准确性、可用性上;
3)还是很demo级别,适合做二次开发,但要补充的点还有很多;
再说优点:
1)整个的设计很有想法,可配置在不同级别(段落、句子),提取抽取字段所在的参考文献并映射到原始文档,也提供了面向docx的解析,整个文档的组织思路很好;
2)简单配置,配置llm等,代码量低,整个抽取的流程也搭建好了,小白上手会好用,封装的好。
3)是想做通用信息抽取的技术框架,可支持不同类型、图片、文本类型的提取,通过配置不同大模型参与处理,也能记录推理过程中的一些统计信息。
总而言之,ContextGem是一个很有创意的初级框架,还有很长的路要走,对落地意义帮助不是很大,因为在抽取这件事上,它想得太简单的。
参考文献
1、https://arxiv.org/pdf/2504.20734
2、http://github.com/shcherbak-ai/contextgem
(文:老刘说NLP)