🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
一石激起千层浪。
OpenAI 近日正式发布了其精心打造的医疗 AI 评估新基准——HealthBench。
官方博客洋洋洒洒,详细阐述了这一“AGI 标志性用例”的背景、设计理念和宏大愿景。
这玩意儿不只是个新测试集,更像是 OpenAI 给未来医疗 AI 立了个新标尺,指了个方向。
OpenAI 在官宣里说了,AGI (通用人工智能) 要是能改善人类健康,那绝对是里程碑式的影响。大语言模型潜力是挺大,但真要用到医疗上,必须保证既好用又安全。
问题是,现在那些评估方法,普遍有三大硬伤:
-
不接地气:没法真实还原医疗场景。
-
专家缺位:缺少基于医生意见的严格验证。
-
天花板低:没给那些前沿模型留啥进步空间。
所以,HealthBench 横空出世。
他们这次下了血本,跟全球 60 个国家、262 名执业医生 深度合作,攒了个包含 5000 个真实医疗健康对话场景 的大数据库。
每个对话都配了详细的医生评分标准,总共搞了 48562 个 独特的评分细则。
OpenAI 搞医疗 AI 的负责人 Karan Singhal 对 HealthBench 信心满满。
他说,希望能靠它,把 AI 真正引向改善人类健康的正轨。
HealthBench 的设计,有三个核心想法:
首先,要 有现实意义。
评分得反映真实世界的医疗场景,抓住那些复杂的细节。
其次,要 值得信赖。
评分得是真医生给的,符合他们专业的要求。
最后,得让 AI 能进步。
这个测试不能让现有模型轻松过关,要能逼着它们拿出显著的改进。
除了主打的 HealthBench,OpenAI 还准备了进阶版。
有个叫 HealthBench Hard 的,是专门给那些更高难度场景准备的。
还有个 HealthBench Consensus,是请了好几个医生一起验证的,确保评估标准够专业。
准备把医疗 AI 的评估体系从易到难、从单人到多人,全方位无死角覆盖。
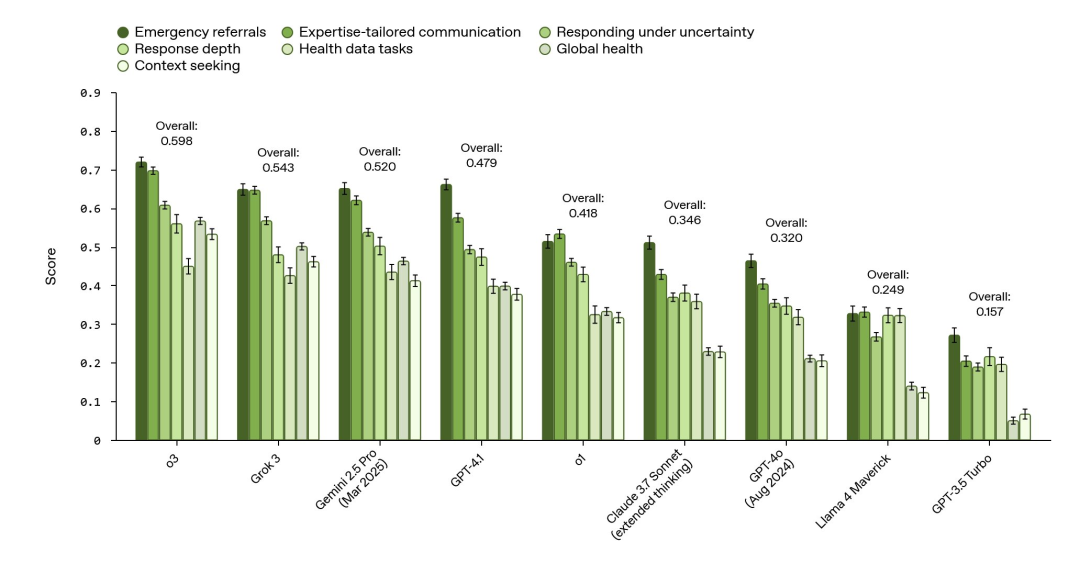
数据屠榜:o3 登顶,AI 单挑能力已达人类医生最佳水平?
HealthBench 一出,各大顶尖模型纷纷下场“应考”。结果显示,OpenAI 自家的 o3 模型表现最为抢眼,全面超越了 Grok 3、Gemini 2.5 Pro (Mar 2025) 和 Claude 3.7 Sonnet 等一众强敌,成功登顶。
Grok 3(基础模型)排名第 2,击败了除 o3 之外的所有模型。
更引人注目的是“AI 与医生正面交锋”的实验结果。OpenAI 让医生分别在无 AI 辅助和有 AI 参考的情况下作答,并与 AI 模型的回答进行对比。
-
对于 2024 年 9 月的模型 (如 o1-preview, 4o): 结论是“人机协作最佳”。得到模型辅助的医生,其表现优于模型自身的参考回答。
-
但当换上 2025 年 4 月的最新模型 (如 o3, GPT-4.1): 局面发生了戏剧性转变。OpenAI 发现,医生的优化回答与 AI 的原始回答相比,质量上没有显著提升。 这意味着,当前最强 AI 的回答质量,几乎已经达到了人类医生参考最新 AI 后能达到的最佳水平。
人类免疫学家 Derya Unutmaz 对此高度评价道:“这个关键的评估基准,将为 AI 医生铺平道路。我们现在正处于一场改变医学未来,拯救数百万人生命的革命开端。”
图表里的“扎心”细节:AI 进步神速,人类医生何去何从?
让我们通过 HealthBench 放出的对比图,更直观地感受这场“风暴”:
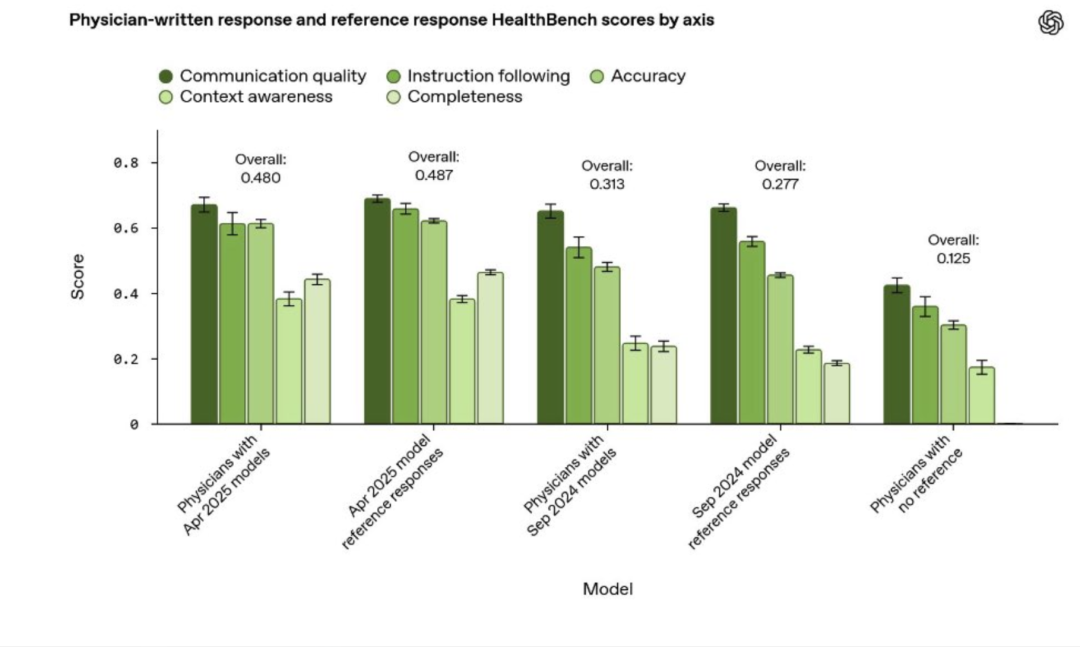
这张图清晰地显示:
-
医生独立手写 (Physicians with no reference): 总分仅 0.125,垫底。
-
2024 年 9 月模型独立作答 vs. 医生 + 2024 年 9 月模型辅助: 分别为 0.277 和 0.313,此时“人机协作”仍有优势。
-
2025 年 4 月模型独立作答 (Apr 2025 model) vs. 医生 + 2025 年 4 月模型辅助: 分别为 0.487 和 0.480。最新的 AI 模型单独作答,总分已经略微超过了“医生+最新 AI 辅助”的组合。
所以,仅靠 AI 模型就比独立医生好 4 倍。
同时,另一张汇集了更多新老模型的对比图则进一步佐证了 AI 的迅猛发展。
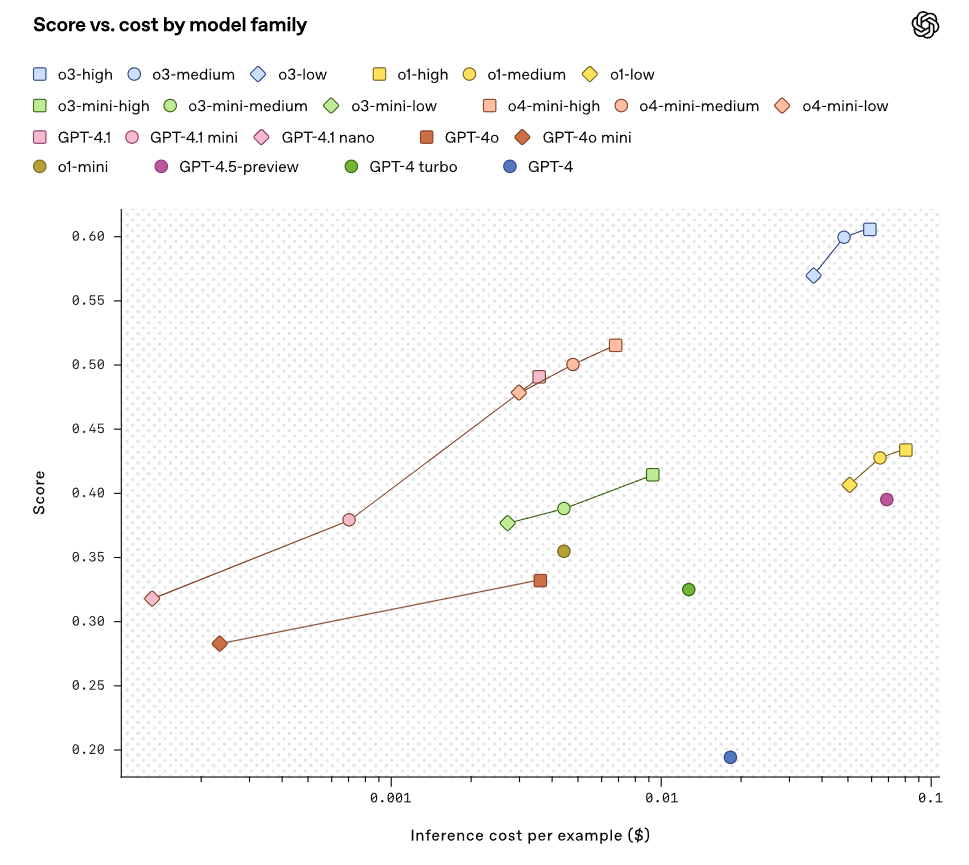
图表显示,小模型的性能在最近几个月也得到了显著改进, 例如 GPT-4.1 nano 尽管成本仅为 GPT-4o (2024年8月版) 的 1/25,表现却更优,这为 AI 在资源匮乏地区的应用带来了曙光。
在可靠性方面,OpenAI 关注“最差表现 (worst-of-n performance)”。结果显示,o3 模型在 16 个样本时的最差分数超过 GPT-4o 的两倍,展现出更强的稳健性。
为了确保 HealthBench 评分的专业性和可信度,OpenAI 还进行了“元评估”,对比模型评分器与医生判断之间的一致性。结论是,GPT-4.1 作为评分模型的表现已能与医生专家的评估相媲美,甚至在某些主题上超越了医生平均水平。
网友Emmanuel Afolabi 强调: AI 的优势在于信息处理,但真正的医疗需要同情心、伦理和情境判断。
还有人认为: AI 已不再是辅助技术,而是新的基准,医疗行业正在被实时重定义。
也有用国际象棋类比的: “人机混合最强”只是阶段性的。
正如 OpenAI 所言,HealthBench 的目标是支持整个生态系统的研究者,共同推动 AI 技术真正造福人类健康。这场由数据引发的“风暴”,或许正是开启 AI 医疗新篇章的“催化剂”。
未来已来,只是比我们想象的更快、更复杂。
AI 绘画元方法:不肝提示词,文章直出封面。(端到端篇)
AI 绘画“元方法”分享,免费绘图流,掌握思维比提示词更重要。(融图篇)
本号知识星球(汇集ALL订阅频道合集和其他):
星球里可获取更多AI实践和资讯:
MCP文章,从概念到实践再到自己构建:
MCP是什么:Windsurf Wave3:MCP协议让AI直接读取控制台错误,自动化网页调试不用复制粘贴了!Tab智能跳转、Turbo模式。
MCP怎么配置、报错解决:Windows下MCP报错的救星来了,1分钟教你完美解决Cursor配置问题。
MCP实践:Cursor + MCP:效率狂飙!一键克隆网站、自动调试错误,社区:每个人都在谈论MCP!
最新MCP托管平台:让Cursor秒变数据库专家,一键对接Github,开发效率暴增!
Blender + MCP 从入门到实践:安装、配置、插件、渲染与快捷键一文搞定!
比Playwright更高效!BrowserTools MCP 让Cursor直接控制当前浏览器,AI调试+SEO审计效率狂飙!
手把手教你配置BrowserTools MCP,Windows 和 Mac全流程,关键命令别忽略。
2分钟构建自己的MCP服务器,从算数到 Firecrawl MCP(手动挡 + AI档)
太简单了!Cline官方定义MCP开发流程,聊天式开发,让MCP搭建不再复杂。
🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
参考链接:
[基准博客] https://openai.com/index/healthbench/
点这里👇关注我,记得标星哦~
(文:AI进修生)