


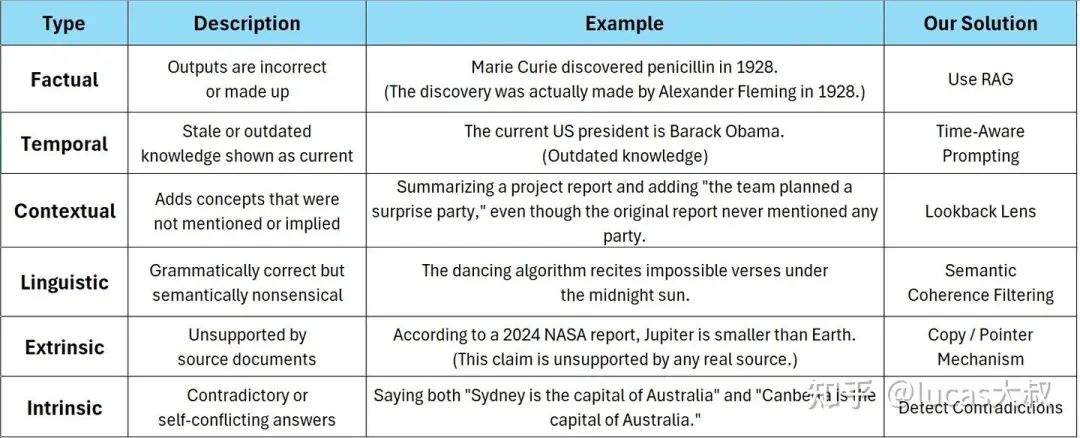
LLM中的幻觉有多种不同的形式,例如以下几种:
-
• 事实幻觉:表现为输出错误回复或捏造答案,可通过RAG解决 -
• 时间幻觉:表现为将陈旧或过时的知识作为当前知识,可通过时间感知提示解决 -
• 上下文幻觉:表现为在回复中增加上下文中未提及或暗示的概念,可通过 Lookback Lens(一种基于回溯比例的检测器)解决 -
• 语言幻觉:表现为回复的内容语法上没有问题但语义上没有意义,可通过语义连贯过滤解决 -
• 外在幻觉:表现为回复为源文档不支持的内容,可通过拷贝/指针机制解决 -
• 内在幻觉:表现为自相矛盾的答案,可通过矛盾检测解决
本文将使用1B LLaMA模型用于文本生成,以展示如何解决小模型中的幻觉问题。我们将处理每一种幻觉类型,以了解不同的技术如何克服这些问题。
模型介绍
几乎所有出现幻觉的AI产品都基于两个组件:
-
• 文本生成大语言模型(LLM) -
• 嵌入模型
OpenAI、Gemini和Anthropic的模型非常出色,即使在非常复杂的情况下,它们也几乎不会产生幻觉。然而,它们的使用是有成本的。另一方面,开源大语言模型,尤其是小模型成本更低,但在生成高质量答案方面表现欠佳。

由于此次使用的是1B LLaMA模型进行文本生成。这样,我们就可以使用成本较低的模型,作为 RAG 或其他任何chatbot应用场景的可行解决方案。
首先创建一个函数,该函数基于系统/用户提示模板重复生成文本。
import torch
from transformers import pipeline
# Load the LLaMA model using HuggingFace Transformers pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 for efficient computation
device_map="auto", # Automatically selects available GPU/CPU
)然后,利用LLM创建函数:
def generate_response(system_prompt: str, user_prompt: str) -> str:
"""
Generate a response from the model based on a system prompt and user prompt.
Parameters:
- system_prompt (str): The instruction or persona for the model (e.g., "You are a pirate chatbot").
- user_prompt (str): The actual user query or message to respond to.
Returns:
- str: The generated text response from the model.
"""
# Construct the input message format for the model
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
# Generate output using the pipeline
outputs = pipe(messages)
# Extract and return the generated text
return outputs[0]["generated_text"][-1]['content']对于开源嵌入模型,随机选一个很小的模型,这样就能在本地环境加载。此次使用大小为45MB的GTE Tiny来快速创建嵌入。
from sentence_transformers import SentenceTransformer
import numpy as np
# Load the model once (outside the function) to avoid reloading on each call
embedding_model = SentenceTransformer("TaylorAI/gte-tiny")
def get_sentence_embedding(sentence: str) -> np.ndarray:
"""
Generate an embedding vector for a given sentence using a preloaded SentenceTransformer model.
Parameters:
- sentence (str): The input sentence to encode.
Returns:
- np.ndarray: The sentence embedding as a NumPy array.
"""
# Encode the sentence into a dense vector using the preloaded model
embedding = embedding_model.encode(sentence)
return embedding现在我们已经搭建好了大语言模型(LLaMA 1B)和嵌入模型(GTE Tiny)。接下来逐一解决这些幻觉类型。
基于RAG的事实性纠错
让我们从小LLM的基本问题开始,它们常常对事实性问题给出错误答案。
看下面这个例子:
# The system prompt sets the behavior or persona of the AI
system_prompt = "You are an AI Chatbot!"
# The user prompt is the actual question or input from the user
user_prompt = "Who discovered Penicillin in 1928?"
# Generate a response from the AI using the system and user prompts
response = generate_response(system_prompt, user_prompt)
# Print the response returned by the AI
print(response)查询的真正答案是“Penicillin was discovered in 1928 by Alexander Fleming.”,但大模型的回答是:
Robert Withering, an English physician, is often credited with the discovery of penicillin in小模型将功劳归错了人(如果尝试多次,它可能会给出正确答案),但在实际应用中,没有多次尝试的机会。1B参数的LLaMA训练数据可能包含也可能不包含正确答案,但无论哪种情况,它的第一个回答都不正确。RAG是解决这个问题最常用的技术之一。
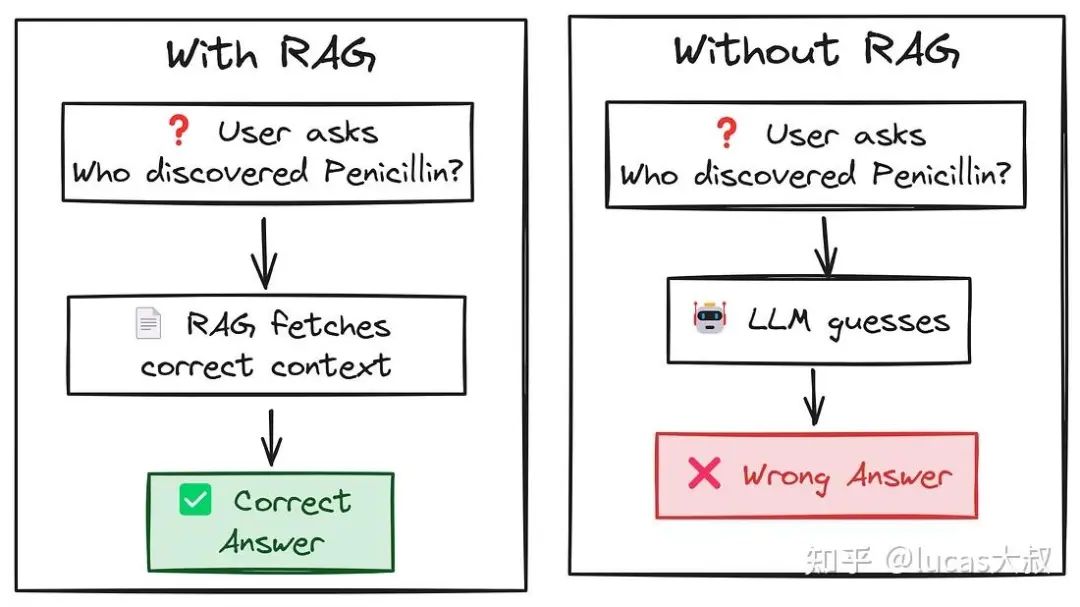
所以,我们通常有大量的文档,而在这些文档的某个地方就隐藏着测试查询的答案。否则,大模型应该回应说它没有相关的训练数据,而不是给出错误的答案。这样,模型的质量对用户来说仍然是可信的。
让我们定义知识库:
# Our Knowledge Base (5 Documents)
documents = [
"Robert Withering, an English physician and botanist, is known for his study of the foxglove plant and its medicinal properties, particularly its use in treating dropsy (edema).",
"The process of fermentation is a metabolic process that produces chemical changes in organic substrates through the action of enzymes. It typically occurs in yeast and bacteria, and also in oxygen-starved muscle cells, as in the case of lactic acid fermentation.",
"Sir Alexander Fleming, a Scottish physician and microbiologist, discovered the antibiotic substance penicillin from the mould Penicillium notatum in 1928. This discovery revolutionized medicine.",
"The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It was named after the engineer Gustave Eiffel, whose company designed and built the tower."
]知识库包含五份文档,LLM将使用这些文档来回答查询。所以,让我们创建简单的RAG管道,看看它是否能提升大模型的回复质量。
# Embed the user query
user_query = "Who discovered Penicillin in 1928?" # Our test query
user_query_embedding = get_sentence_embedding(user_query)
# Embed the Knowledge Base
document_embeddings = [get_sentence_embedding(doc) for doc in documents]
# Find the most relevant document based on embedding similarity (using dot product)
similarity_scores = np.dot(document_embeddings, user_query_embedding)
# Find the index of the document with the highest score
most_relevant_doc_index = np.argmax(similarity_scores)
# Retrieve the text of the most relevant document
retrieved_context = documents[most_relevant_doc_index]在生产环境中,通常会检索和试验块大小(chunk size)、重叠(overlap)以及其他参数,包括最相关的块。但此处为了简化操作,仅检索相似度得分最高的文档作为参考,该文档将被传递到LLM输入中。
下面创建系统和用户提示,看看LLM会给出什么响应。
# We explicitly tell the AI to use the context provided
rag_system_prompt = f"""You are an AI Chatbot!
Use the following context to answer the user's question accurately.
If the context does not contain enough information to answer the question,
respond that you don't have sufficient information from the provided context.
Context:
{retrieved_context}
"""
# The user prompt remains the same
user_prompt = "Who discovered Penicillin in 1928?"
# Generate a response using the RAG system prompt and original user prompt
rag_response = generate_response(rag_system_prompt, user_prompt)
# Print the RAG-enhanced response
print(rag_response)LLM响应是
Penicillin was actually discovered by Sir Alexander Fleming, a Scottish physician and microbiologist,LLM在事实性回答方面有了明显的改进;现在它能正确回答事实性问题了。
让我们继续探讨下一种幻觉类型,看看如何解决它。
使用时间感知提示进行时间校正
时间幻觉是指 LLM 产生对时间敏感的错误或过时信息的情况。这是因为大语言模型有固定的 “知识截止日期”(它们只了解到其训练日期之前的世界信息)。
看下面这个例子:
# The system prompt sets the behavior or persona of the AI
system_prompt = "You are an AI Chatbot!"
# The user prompt is the actual question or input from the user
user_prompt = "Who is the president of France today?"
# Generate a response from the AI using the system and user prompts
response = generate_response(system_prompt, user_prompt)
# Print the response returned by the AI
print(response)我们向大模型询问法国现任总统的信息,以下是大模型给出的输出:
The current President of France is Emmanuel Macron.解决这个问题的一种方法是使用RAG,但并非总是需要有可用的相关知识库。那么,该如何处理这种情况呢?
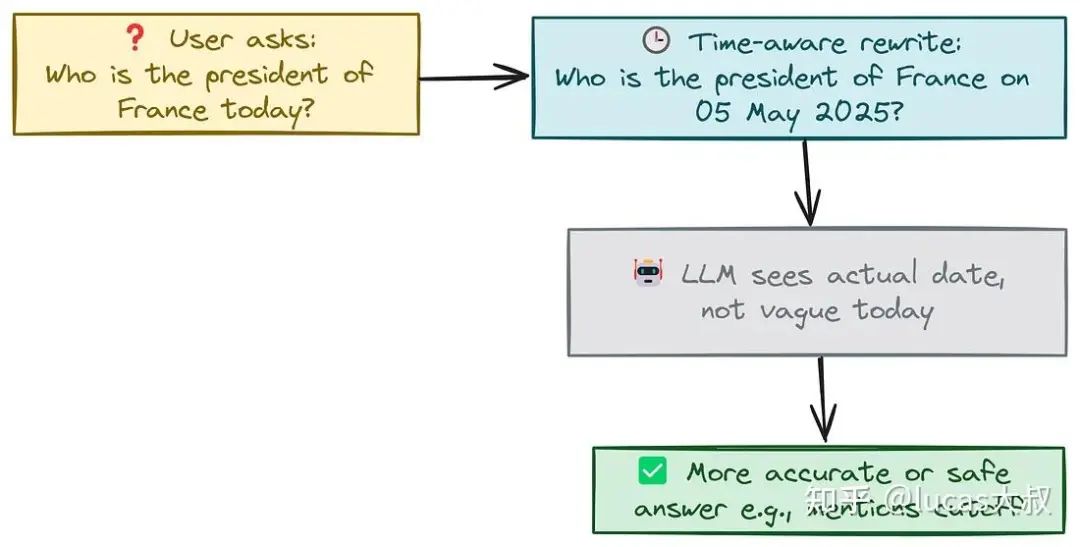
研究人员提出了一个重写查询以包含时间约束的框架 — TimeR4[1]。可以使用这种时间感知提示方法让LLM知晓所提出查询的时间范围。
-
• today → 14 May 2025 -
• this year → 2025 -
• this month → May
通过这种方式,用重写的查询引导LLM,该查询明确指定了所涉及的时间范围,使大模型能够根据其训练数据更准确地做出回应。
这也可以提高 RAG 的检索质量,因为我们在其中纳入了时间范围。
让我们实现这种时间感知提示技术。可以为此使用Python的datetime模块,也可以使用大模型。但目前,我们将创建一个函数或一些简单的代码,通过将诸如“today”之类的时间关键词替换为实际的当前日期来重写用户查询。
from datetime import datetime
def make_query_time_aware(user_prompt: str) -> str:
"""
Rewrites the user prompt to include the current date for temporal context.
This is a simplified example targeting specific keywords.
Parameters:
- user_prompt (str): The original user query.
Returns:
- str: The rewritten, time-aware query.
"""
current_date_str = datetime.now().strftime("%d %B %Y") # e.g., "05 May 2025"
# Simple replacements - expand this for more temporal keywords
rewritten_prompt = user_prompt.replace("today", current_date_str)
rewritten_prompt = rewritten_prompt.replace("this year", datetime.now().strftime("%Y"))
rewritten_prompt = rewritten_prompt.replace("this month", datetime.now().strftime("%B %Y"))
# You might add more complex logic or regex for different temporal phrases
return rewritten_prompt让我们在查询上执行此函数。
# Let's apply this to our original temporal query
user_prompt = "Who is the president of France today?"
time_aware_user_prompt = make_query_time_aware(user_prompt)
print(f"Original Query: {user_prompt}")
print(f"Time-Aware Query: {time_aware_user_prompt}")今天是2025年5月14日,此代码片段的输出将是:
Original Query: Who is the president of France today?
Time-Aware Query: Who is the president of France 14 May 2025?现在将time_aware_user_prompt与最初的简单系统提示一起使用来生成响应。
系统提示不需要更改,因为时间信息现在直接嵌入到用户查询本身。
# The system prompt remains simple
system_prompt = "You are an AI Chatbot!"
# Generate a response using the simple system prompt and the time-aware user prompt
temporal_response = generate_response(system_prompt, time_aware_user_prompt)
# Print the time-aware response
print(temporal_response)1B LLaMA的响应是
I'm an AI chatbot, and my training data is up to December 2023这种方法不仅为LLM提供了一个不回答这个问题的有力理由,而且当你引入RAG时,时间框架肯定会影响信息获取过程,因为 “today” 会给大模型造成混淆,而日期则不会。如果知识库中存在相关文档,这种方法将确保能够检索到它们。
使用回顾视角的上下文问题
上下文幻觉是指语言模型给出不正确或具有误导性的答案,即使获取了所有的正确信息。当模型没有正确使用或理解所提供的细节时,就会发生这种情况,导致答案看似相关,但实际上是错误或不完整的。看下面这个例子:
# Our source context (representing a document or retrieved chunk)
source_context = """ByteBuilders Q3 profit: ~5.02% adj, 4.9% unadj,
+502 bps margin, –0.1 ppt FX drag, vs. 4.5% est."""
# The system prompt (Report + System prompt)
system_prompt = f"""You are an AI Chatbot!
Article Snippet:
{source_context}
"""
# The user prompt is simply asking for the summary
user_prompt = "Summarize the Q3 earnings."
# Generate a response using the system prompt with context
response = generate_response(system_prompt, user_prompt)
# Print the response returned by the AI
print(response)源上下文可以是检索到的文本块、文档或网络搜索结果,基本上是ByteBuilders公司的财务报告。
由于文档中已有相关信息,我们要求LLM对其进行总结。
这是得到的回复:
ByteBuilders reported Q3 earnings (4th quarter) with a net profit of approximately 4.它给出的净利润数值是错误的,尽管文档中明确给出了正确数值。以下是我们的事实依据:
-
• 季度混淆:Q3是第三季度,而非第四季度。 -
• 错误的利润数据:利润增长并非 “约4”(无论是百分比还是其他单位)。在上下文中,ByteBuilders实际公布的调整后利润增长率为5.02%(预期为4.50%)。
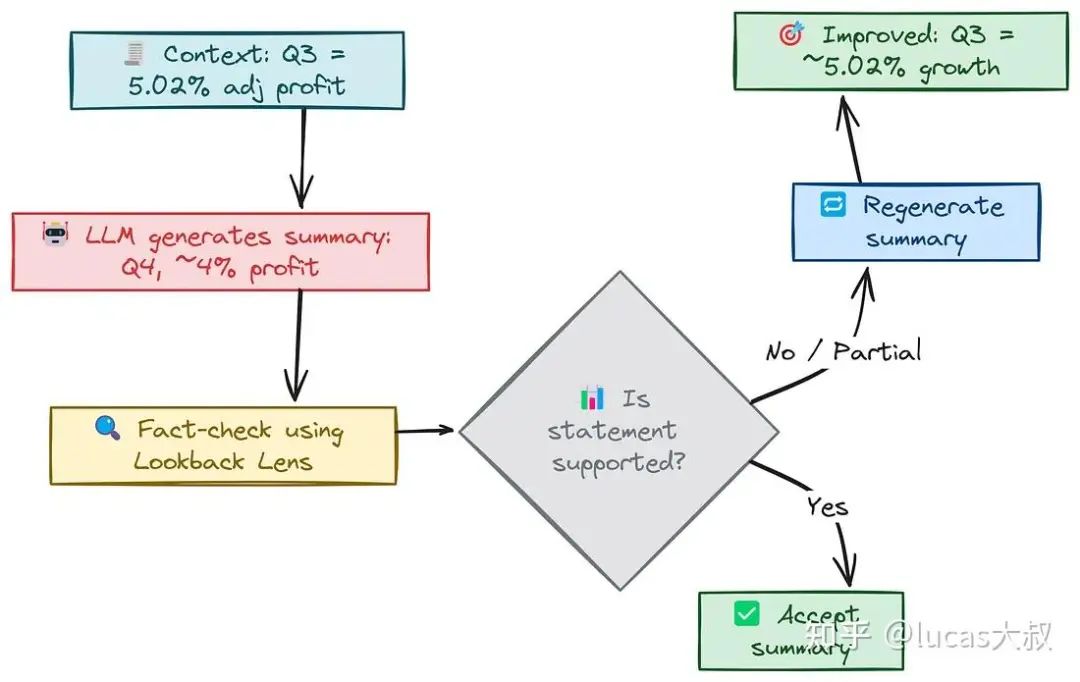
我们可以使用一种类似于Lookback Lens[2]的方法,以确保模型所做的任何具体事实性陈述实际上都有提供的输入上下文支持。
我们可以从生成的摘要中提取关键信息(如“净利润为4”),并将其作为明确的验证问题抛给大模型,再次向其提供原始源上下文,并要求它充当事实核查员。
好处是通常可以使用与生成内容时相同的小模型来执行此验证任务!
# Our source context (representing a document or retrieved chunk)
source_context = """ByteBuilders Q3 profit: ~5.02% adj, 4.9% unadj,
+502 bps margin, –0.1 ppt FX drag, vs. 4.5% est."""
# Fact checking system prompt
verification_system_prompt = f"""You are a fact-checking assistant.
Your task is to determine if the following STATEMENT is
fully and directly supported by the provided CONTEXT.
Answer (only one option to select):
1. Yes
2. No
3. Partially Supported
CONTEXT:
{source_context}
"""
# Proper naming (Last summarized response = hallucinated summary)
hallucinated_summary = response我们正在定义验证系统提示,它将与幻觉生成的总结信息一起传递,以查看大模型会给出什么回应。
# Generate a response using the system prompt with context
verify = generate_response(source_context, hallucinated_summary)
# Print the response returned by the AI
print(verify)以下是得到的响应:
Based on the provided context, The statement is partially supported我们可以使用这些验证信息,并在此基础上,要么要求大模型重新生成其总结回复,要么将任务重定向到更强大的大模型,以便为查询生成更准确的总结。让我们看看这样做,对回复有何影响。
# Decide based on the verification outcome
if "No" in verify or "Partially" in verify:
# Regenerate the summarized info
response = generate_response(improved_system_prompt, user_prompt)
# Show the new response
print(response)
else:
pass生成的响应:
ByteBuilders reported Q3 earnings of ~5.02% annualized growth我们可以在for循环中构建管道,以便并行地重新尝试,这有助于避免让用户等待答案。但在例子中,第二次尝试已经给了一个更好的结果。
使用语义连贯过滤的语言问题
语言幻觉是指语言模型生成的句子听起来正确,语法上也说得通,但意思却是错误的、不相关的或毫无意义。
其结果表面上看起来不错,但缺乏真实或有用的内容。
设想一下,当10个不同的人同时向大模型提出类似的问题,或者多次输入相同的提示时,很有可能其中一人或多人会遇到这种问题。
看下面这个例子:
# The system prompt sets the behavior or persona of the AI
system_prompt = "You are an AI Chatbot!"
# The user prompt is the actual question or input from the user
user_prompt = "Explain how photosynthesis works in plants"
# Initializing a list to store multiple generated responses
responses = []
# Loop to generate 10 different responses
for i in range(10):
# Generating Responses
response = generate_response(system_prompt, user_prompt)
# Append the generated response to the list
responses.append(response)我们使用一个非常简单的查询,许多大模型的训练数据很可能包含这个查询。
既然已经生成了回复,那么在查询和生成的回复之间生成相似度分数,以确定问题出在哪里。
# Get the embedding for the user's query
user_query_embedding = get_sentence_embedding(user_query)
# Get embeddings for all responses
response_embeddings = [get_sentence_embedding(response) for response in responses]
# Calculate similarity scores between the query and each response using dot product
similarity_scores = np.dot(response_embeddings, user_query_embedding)
# Printing sim score
print(similarity_scores)得分为:
array([68.78545 , 69.63894 , 67.53516 , 67.09607 , 32.15152, 67.746735,
67.09607 , 69.6586 , 28.45125, 69.6586 ], dtype=float32)索引为(4, 8)的两个回复相似度得分极低。打印其中一个低得分回复,看看可能存在什么问题:
# Printing Response at index 4
print(f"response[4]: {responses[4]}")“Photosynthesis is a process where plants turn sunlight into sound waves, which they use to create energy.”
这是对光合作用的错误描述,因为该过程并不涉及声波。这个回答听起来语法正确,但在这里意思却毫无意义。
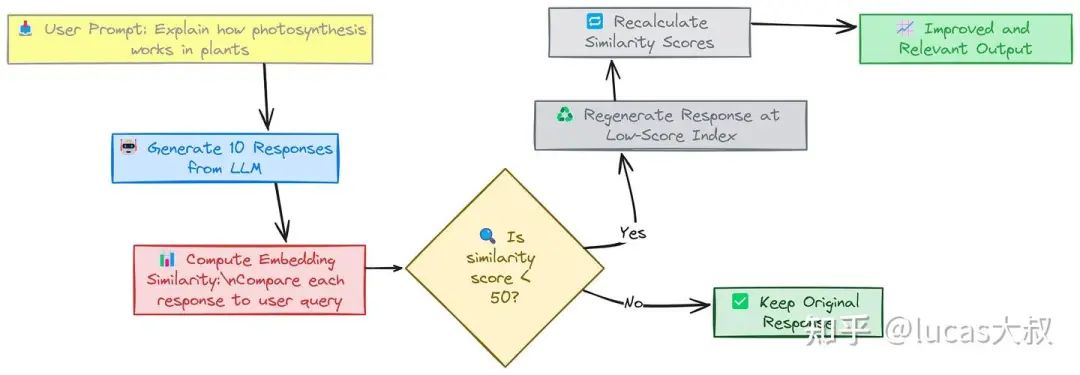
我们可以为相似度分数设置一个阈值(例如,20%)。任何相似度分数低于此阈值的回复都将被标记以便重新生成。
# Set a similarity score threshold
threshold = 50
# Iterate over the responses and regenerate if the score is below the threshold
for i, score in enumerate(similarity_scores):
if score < threshold:
# Regenerate the response
regenerated_response = generate_response(system_prompt, user_prompt)
responses[i] = regenerated_response在重新生成索引4和8处的回复后,重新检查相似度分数,以确保新的回复更相关且准确。
重新计算相似度分数:
# Get embeddings for the regenerated responses
response_embeddings = [get_sentence_embedding(response) for response in responses]
# Recalculate similarity scores between the query and each regenerated response
new_similarity_scores = np.dot(response_embeddings, user_query_embedding)
# Printing the new similarity scores
print("New similarity scores after regeneration:")
print(new_similarity_scores)看下最新生成的相似度得分:
array([68.78545 , 69.63894 , 67.53516 , 67.09607 , 51.479702, 67.746735,
67.09607 , 69.6586 , 69.21619 , 69.6586 ], dtype=float32)索引4和索引8分数有所提高,并且越来越接近用户查询,这意味着它们现在可能包含与查询相关的信息。
当你需要从大模型获得高质量回复时,这种技术非常有用且重要。
使用矛盾检查的内在问题
内在幻觉是指LLM的输出与输入源相矛盾或错误解读输入源的情况。换句话说,模型错误地歪曲了给定的事实。
你可能觉得内在幻觉和上下文幻觉非常相似,我们先通过简单的例子来理解一下:
-
• 输入: The dog is running in the park. -
• (上下文幻觉): The dog is running on the beach. -
• (内在幻觉): The dog is flying in the park.
内在输出与输入直接矛盾。狗不会飞,所以与原始陈述产生了根本性的不一致,这与上下文问题不同,在上下文问题中,模型保持在狗奔跑的上下文中,但改变了地点(从公园到海滩)。
让我们生成一个有此问题的输出。
# Our source context (representing a document or retrieved chunk)
source_context = """The Nile River originates from the Great Lakes
region in Africa."""
# Our user prompt
user_prompt = "Where does the Nile originate?"
# Generate a response using the system prompt with context
response = generate_response(system_prompt, user_prompt)
# Print the response returned by the AI
print(response)让我们看下大模型的输出:
The Nile River originates from Lake Hindia, in Tanzania.大模型输出与输入直接矛盾。为了检测前提(源文本)和假设(模型输出)之间的矛盾,可以使用基于BERT的预训练模型,该模型针对自然语言推理(NLI)进行了微调。
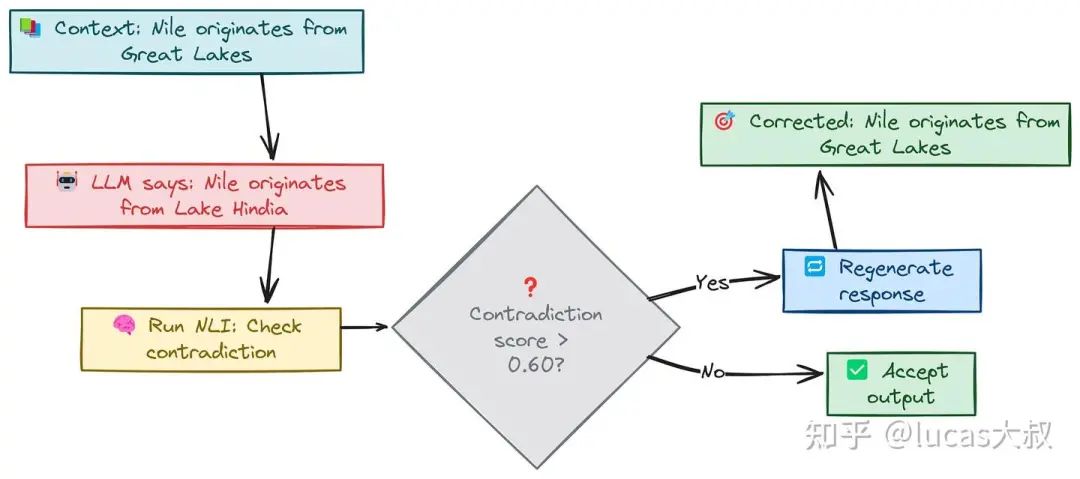
该模型将帮助我们对前提和假设之间的关系进行分类,尤其关注寻找矛盾关系。
为此,使用facebook/bart-large-mnli,这是在MNLI数据集上微调过的流行模型。
from transformers import pipeline
# Define premise (source text) and hypothesis (model output)
premise = source_context
hypothesis = response
# Load an NLI model (fine-tuned on MNLI)
nli_pipeline = pipeline("text-classification", model="facebook/bart-large-mnli")
# Use a prompting format for NLI
result = nli_pipeline(f"Premise: {premise} Hypothesis: {hypothesis}")
print(result)让我们看看模型输出与源文本之间的矛盾得分。
[{'label': 'contradiction', 'score': 0.9499581456184387}]矛盾分数非常高,约为95%,显然我们可以使用与语言方法相同的方法,即设置阈值参数,重新生成LLM的回复,看是否能解决问题。
# Set a contradiction score threshold
threshold = 0.60
# Iterate over the responses and regenerate if the score is below the threshold
if score < threshold:
# Regenerate the response
regenerated_response = generate_response(source_context, user_prompt)
print(regenerated_response)重新生成的响应为:
The Nile River originates from the Great Lakes region in Africa.通过这种方式,可以得出一个尽可能少矛盾的恰当的大模型回复。
使用复制/指针机制的外部问题
外在幻觉是指语言模型添加了原始输入中没有依据的额外信息。与内在幻觉不同,内在幻觉与所提供的数据相冲突,而外在幻觉则创造出全新的、编造的事实。请看下面的例子:
# Meeting summary Report
document = """
Meeting Summary – April 10, 2025
- Discussion of Q1 2025 performance and upcoming product launch.
- CFO presented the Q2 2025 budget proposal.
"""
# User prompt to test for extrinsic hallucinations
user_prompt = """Can you summarize the meeting that took place on April 10th,
2025, and include any decisions made about budget
allocations or new project approvals?"""
# Generating Responses
response = generate_response(document, user_prompt)
# Print the generated response
print(response)在这个提示中,我们特别询问LLM是否存在文档中未提及的新项目批准情况。让我们看看大模型是否会编造出任何事实。
Meeting Summary – April 10, 2025
**Introduction**
* The meeting was attended by the Executive Team, led by the CEO.
**Q1 2025 Performance Review**
* The team reviewed the Q1 2025 performance,
highlighting areas of success and challenges faced.
**New Project Approvals**
* The Executive Team approved several new projects, including:
+ A cloud-based CRM system for customer engagement and support当LLM设置为较高的最大新生成token数(例如500)时,1B参数的小模型就开始生成一堆编造的事实,只是为了填满token空间,而这些事实在原始文档中根本不存在。
一种已被证实可减少外部幻觉的方法是使用指针/复制机制[3]。
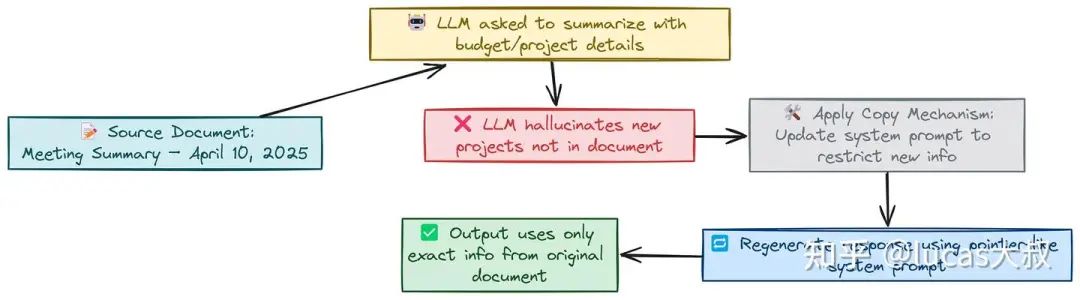
这些技术使模型直接从源文本中提取内容,而不是生成新信息。例如,摘要中的指针生成网络允许模型生成新词或从输入中复制。在大模型中强制进行复制的一种简单方法是使用系统提示,引导模型直接从源文本中复制。
以下是可以构建提示的一个示例:
system_prompt = """Please summarize the following document,
but make sure to only use information that is present in the text.
Do not add any new facts or details that are not in the original document."""让我们用这个更新后的模板生成回复,看看大模型输出是什么:
# User prompt + document
combined_info = document + user_prompt
# Generating Responses with copying mechanism
response_with_copy = generate_response(system_prompt, combined_info)
print(response_with_copy)更新后的输出是:
The meeting summary provided is as follows:
- The Q1 2025 performance was discussed.
- A product launch for the upcoming period was announced.
- The CFO presented a Q2 2025 budget proposal.LLM并非凭借自身“思考”来撰写内容,而只是从原始来源复制文本。这是一种有用的技术,因为在大多数情况下,知识库非常庞大,包含了相关信息,这些信息只需调用,无需重新表述。
总结
我们通过小模型(LLaMA 1B)和小嵌入模型(GTE Tiny),证明可以用更少的资源开展工作。
-
• 事实性问题?使用RAG来解决。简单又有效。 -
• 时间错误?让查询 “具有时间感知”,注入日期会产生奇妙效果! -
• 上下文混淆?实施 “回顾视角”,LLM根据来源进行自我事实核查! -
• 语言怪异?使用嵌入相似度阈值过滤无意义的输出并重新生成。 -
• 内在矛盾?使用自然语言推理(NLI)模型检测输出是否与来源冲突,若冲突则重新生成。 -
• 外在编造内容?通过提示强制采用 “复制/指针” 风格,紧扣源文本。
通过这些技术系统地解决幻觉问题,我们可以让小参数、低成本的大模型成为可行选择。
参考文档
https://medium.com/@fareedkhandev/8d15c11650d3
引用链接
[1] TimeR4: https://aclanthology.org/2024.emnlp-main.394/[2] Lookback Lens: https://arxiv.org/html/2407.07071v1#:~:text=To%20leverage%20signals%20from%20attention,The[3] 指针/复制机制: https://arxiv.org/pdf/2005.00661#:~:text=and%20inference,intrinsic%20hallucination
(文:机器学习算法与自然语言处理)