


在人工智能领域,多模态大模型正逐渐成为推动技术发展的关键力量。随着对复杂场景理解需求的增加,能够同时处理视觉和语言信息的模型变得尤为重要。字节跳动Seed团队推出的Seed1.5-VL模型,以其高效、强大的多模态理解和推理能力,为这一领域带来了新的突破。
一、项目概述
Seed1.5-VL是由字节跳动Seed团队开发的视觉语言多模态大模型,旨在推进通用多模态理解和推理能力。该模型由一个5.32亿参数的视觉编码器和一个激活参数规模达200亿的混合专家(MoE)大语言模型组成,通过创新的架构和训练方法,在60个公开评测基准中的38个上取得了最佳表现,展现了其在视觉理解、语言处理以及两者结合的多模态任务中的卓越性能。其高效的推理成本和强大的功能使其成为多模态领域的一个重要里程碑。

二、技术架构
(一)模型组件
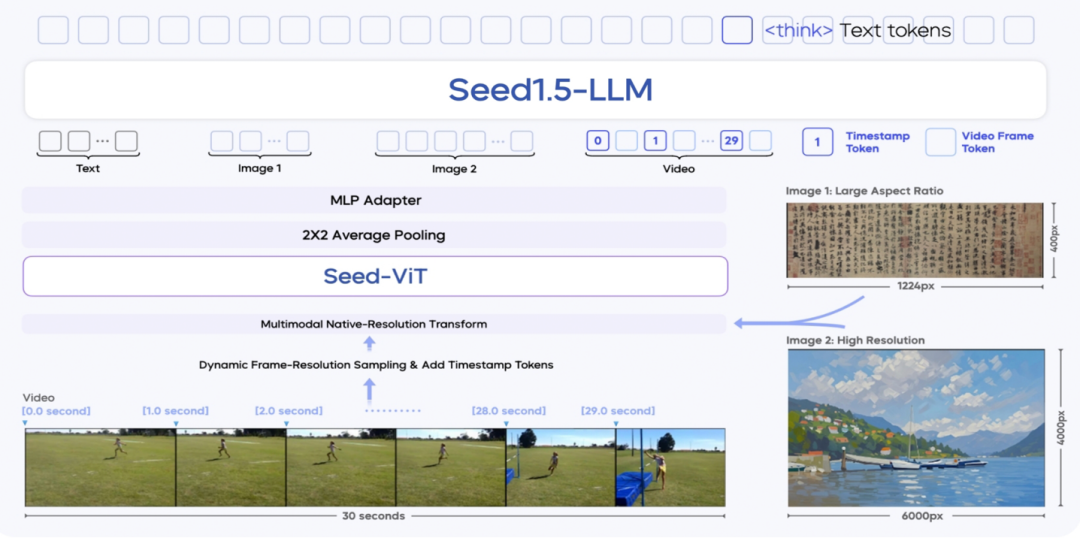
Seed1.5-VL由三个核心组件构成:SeedViT视觉编码器、MLP适配器和大语言模型。SeedViT用于对图像和视频进行编码,支持多种分辨率的图像输入,并通过原生分辨率变换最大限度保留图像细节。MLP适配器将视觉特征投射为多模态token,而大语言模型则用于处理多模态输入并执行推理。这种架构设计使得模型能够有效地结合视觉和语言信息,实现复杂的多模态任务。
(二)视频处理策略
在视频处理方面,Seed1.5-VL提出了动态帧分辨率采样策略,能够根据视频内容的复杂性和任务需求动态调整采样帧率和分辨率。这一策略不仅提高了处理效率,还确保了模型能够捕捉到视频中的关键信息。此外,为了增强模型对时间信息的感知能力,每帧图像前都引入了时间戳标记,进一步提升了视频理解的准确性。
三、主要功能
(一)2D 图像理解
Seed1.5-VL 能够对二维图像进行深入的理解和分析,能够精准识别出图像中的物体类别、位置以及它们之间的空间关系,并且可以对图像的场景、氛围、风格等进行细致的描述。无论是简单的日常物品图片,还是复杂的艺术作品或专业领域的图像资料,它都可以快速准确地提取图像内容的语义信息。
(二)3D 物体理解
该模型支持对三维物体的识别和理解,可应用于虚拟现实、增强现实等领域,为用户提供更丰富的交互体验,帮助模型更好地理解物体的空间关系和结构。它能够根据二维图像推断出物体的三维形状、尺寸和朝向,甚至可以对物体在三维空间中的运动轨迹进行预测。
(三)视频内容解析
Seed1.5-VL 可以分析视频中的动作、情感、场景等信息,为视频内容推荐、广告投放等提供依据,同时在视频摘要、视频问答等任务中表现出色。它能够实时理解视频中的动态变化,捕捉关键帧和重要情节,生成简洁而准确的视频摘要,帮助用户快速了解视频的核心内容。
(四)多模态推理
结合视觉和语言信息,Seed1.5-VL 能够进行复杂的推理任务,例如根据图像和文本描述判断场景或物体的属性,解决视觉谜题等,展现了强大的多模态推理能力。当给定一张包含多种食材的厨房图片和一段描述烹饪步骤的文字时,它可以推断出最终可能 dishes 的名称和口味特点;
(五)交互式代理任务
在以GUI 控制和游戏玩法为代表的交互式代理任务中,Seed1.5-VL 表现出色,能够更好地理解和响应用户的指令,为开发智能交互系统提供了有力支持。它可以精确识别和操作图形用户界面中的各种元素,如按钮、菜单、图标等,实现高效的人机交互。比如在智能办公软件中,它可以根据用户的语音或文字指令自动完成一系列复杂的操作,提高工作效率;在游戏领域,它可以作为智能游戏伙伴,理解游戏规则和玩家意图,与玩家进行实时互动和协作,增强游戏的趣味性和挑战性。
四、应用场景
(一)图像识别
在电子商务领域,Seed1.5-VL 能够对商品图片进行精准识别和分类,帮助用户快速找到所需商品,同时为商家提供更高效的图像管理方案。它还可以实现对商品瑕疵、真伪的鉴别,降低消费者购买到不合格产品的风险。在安防监控方面,该模型可以实时分析监控摄像头拍摄的图像,快速识别出可疑人员、车辆以及异常行为,及时发出警报并采取相应的安全措施,为社会安全保驾护航。
(二)视频内容分析
媒体和娱乐行业可以利用Seed1.5-VL 分析视频内容,实现精准的内容推荐和广告投放,提升用户体验和商业价值。通过对用户观看历史和视频内容特征的综合分析,它能够为每个用户提供更符合其兴趣和偏好的视频推荐列表,提高用户的观看时长和粘性。
(三)自动驾驶
Seed1.5-VL 能够识别和解析道路上的车辆、行人、交通标志等信息,为自动驾驶系统提供可靠的视觉支持,增强自动驾驶的安全性和可靠性。它可以实时感知车辆周围环境的变化,准确预测其他交通参与者的行动轨迹,为自动驾驶车辆的决策系统提供准确的数据输入,从而做出更加安全合理的驾驶决策。
例如,在复杂的城市交通环境中,Seed1.5-VL 可以有效识别出突然横穿马路的行人或非机动车,并及时发出预警信号,使自动驾驶车辆能够迅速采取制动或避让措施,避免交通事故的发生。此外,它还可以协助自动驾驶车辆进行高精度的地图定位和路径规划,提高自动驾驶的导航精度和效率。
(四)机器人视觉
为机器人和无人设备提供视觉识别和导航功能,帮助机器人更好地理解周围环境,实现自主导航和任务执行。在物流仓储领域,Seed1.5-VL 可以引导机器人进行货物的分拣、搬运和入库等操作,提高物流效率和准确性。在家庭服务机器人方面,它可以实现对家庭环境的智能感知,帮助机器人完成清洁、整理、照顾老人儿童等任务,为人们的生活提供更加便捷的服务。同时,在工业巡检、农业监测等领域的机器人应用中,Seed1.5-VL 也能够发挥重要作用,通过对现场环境的图像分析,及时发现问题并反馈给控制中心,实现智能化的无人值守作业。
五、测评表现
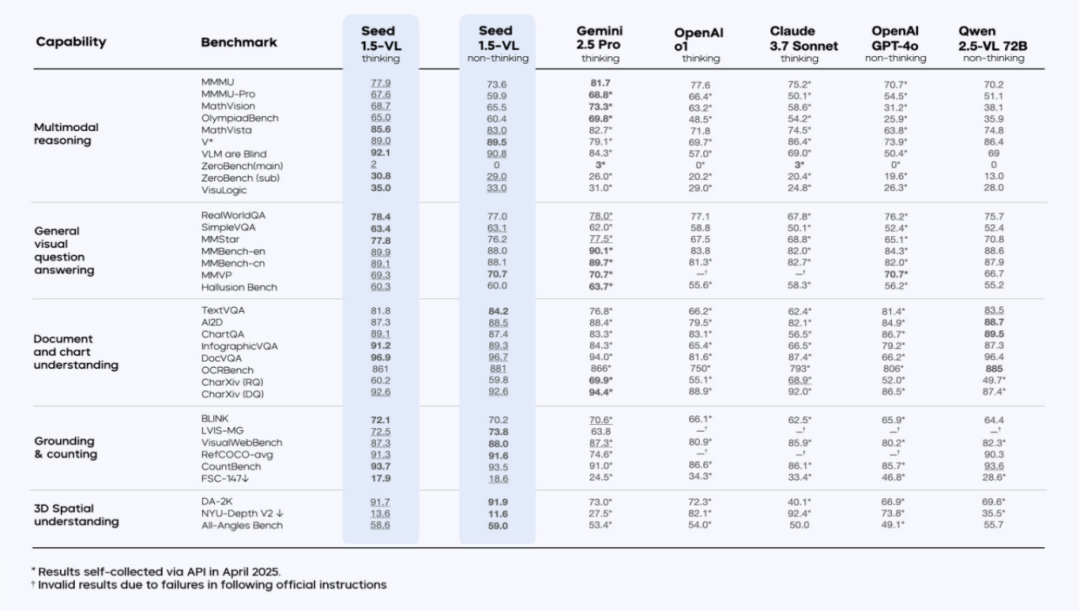
Seed1.5-VL在多个公开基准测试中取得了优异的成绩,展现了其强大的性能。在60个公开评测基准中的38个上取得了最佳表现,其中包括19项视频基准测试中的14项和7项GUI代理任务中的3项。
六、快速使用
(一)API调用
Seed1.5-VL已经部署在火山引擎上,用户可以通过API接口快速使用该模型。首先需要在火山引擎上申请API_KEY,然后通过以下代码示例进行调用:
import requestsapi_key = "your_api_key"url = "https://api.volcanoengine.com/seed1.5-vl"headers = {"Authorization": f"Bearer {api_key}"}data = {"image": "image_url", "text": "your_text"}response = requests.post(url, headers=headers, json=data)print(response.json())
(三)Gradio Demo
为了方便用户快速体验Seed1.5-VL的功能,项目还提供了Gradio Demo。用户可以通过以下链接访问在线或离线的Gradio Demo:
在线Gradio Demo:
https://huggingface.co/spaces/seed1.5-vl
离线Gradio Demo
# 克隆代码git clone https://github.com/ByteDance-Seed/Seed1.5-VL.gitcd Seed1.5-VL/GradioDemo# 安装依赖pip install gradio decord torchvisionpip install httpx==0.23.3# 启动APPAPI_KEY="..." python app.py
通过Gradio Demo,用户可以上传图像和文本,快速查看模型的输出结果,感受Seed1.5-VL的强大功能。
七、结语
Seed1.5-VL作为字节跳动Seed团队推出的一款高效多模态视觉语言大模型,在视觉理解、语言处理以及多模态任务中展现了卓越的性能。其创新的技术架构、强大的功能和广泛的应用场景使其成为多模态领域的一个重要里程碑。期待未来Seed1.5-VL在更多领域发挥更大的作用,推动多模态技术的发展和应用。
八、项目地址
官方网站:https://seed.bytedance.com/zh/tech/seed1_5_vl
GitHub仓库:https://github.com/ByteDance-Seed/Seed1.5-VL
技术报告:https://arxiv.org/pdf/2505.07062
(文:小兵的AI视界)