





昇腾NPU芯片是华为旗下的高性能AI处理器,专为大规模AI训练、高性能AI推理等任务设计。
其中,Atlas 800I A2推理服务器一个节点包含8张NPU芯片,形成多机组网架构。
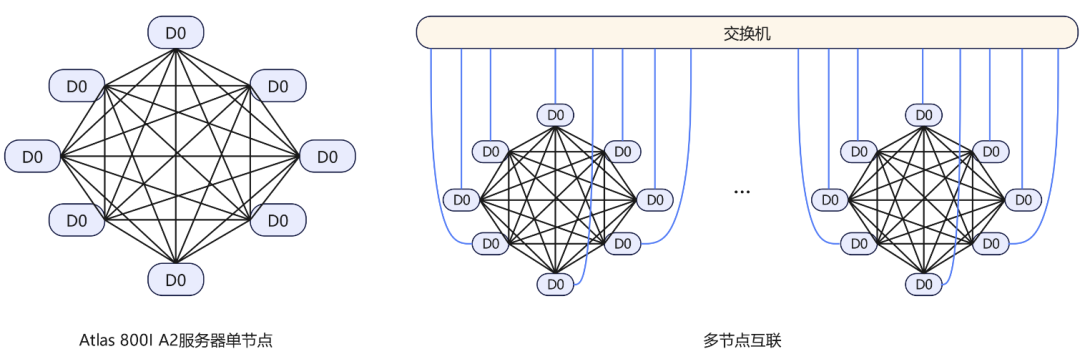
A2单节点内8卡NPU通过Fullmesh形成全互联结构,通信总带宽392GB/s,不同节点间则通过网络交换机进行互联,形成Stars结构,通信总带宽50GB/s,每张Atlas 800I A2昇腾卡的内存大小是64GB。

CloudMatrix 384超节点则是进一步采用多卡紧耦合互联,统一内存编址,统一标识,统一通信等技术实现在算力、互联带宽、内存带宽的方面的的性能提升。
因为DeepSeek模型是在英伟达芯片上训练出来的,为适配昇腾芯片保证推理性能,华为团队采用SmoothQuant技术,对模型进行A8W8动态量化,计算过程的中间变量采用BF16。
大模型推理过程主要分Prefill和Decode两个阶段,Prefill阶段通常是计算瓶颈,而Decode阶段通常是带宽瓶颈和通信瓶颈,华为团队采用了Prefill和Decode分离的方式,在流行的vLLM服务框架基础上进行模型部署。
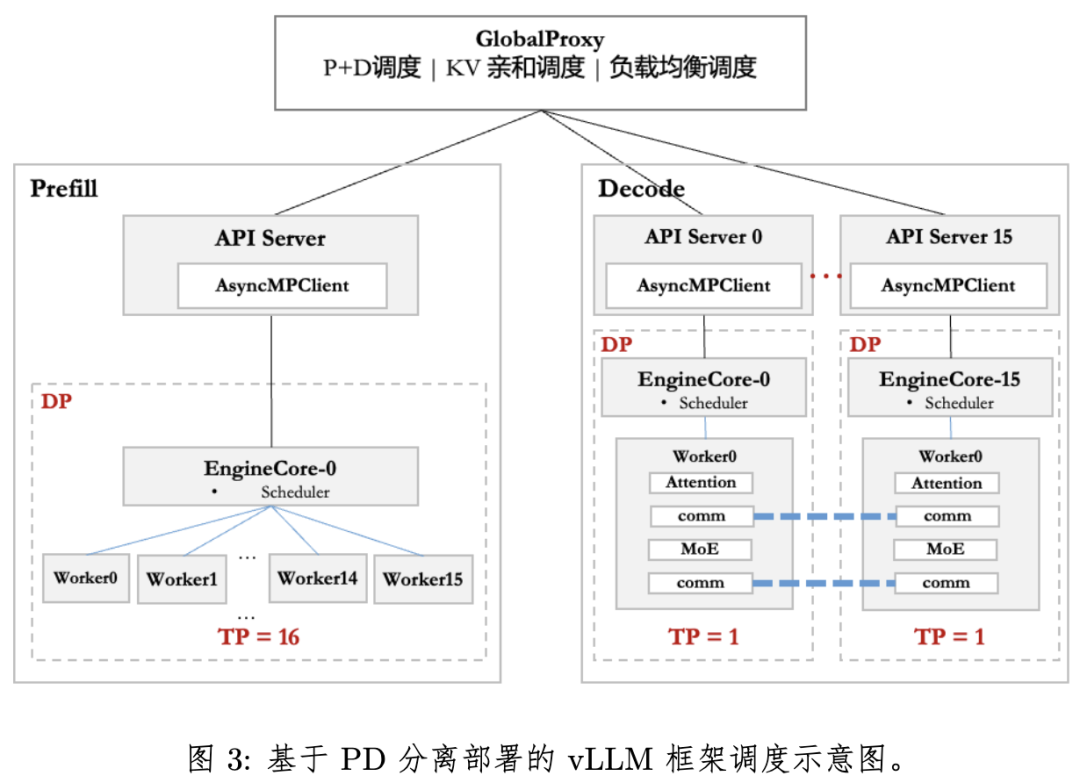
在Atlas 800I A2的部署上,Decode阶段仅使用32卡进行部署,Prefill阶段仅使用16卡部署,想要实现更高性能则意味着高内存占用,所以具体的部署策略上开发者要特别注意内存的占用。
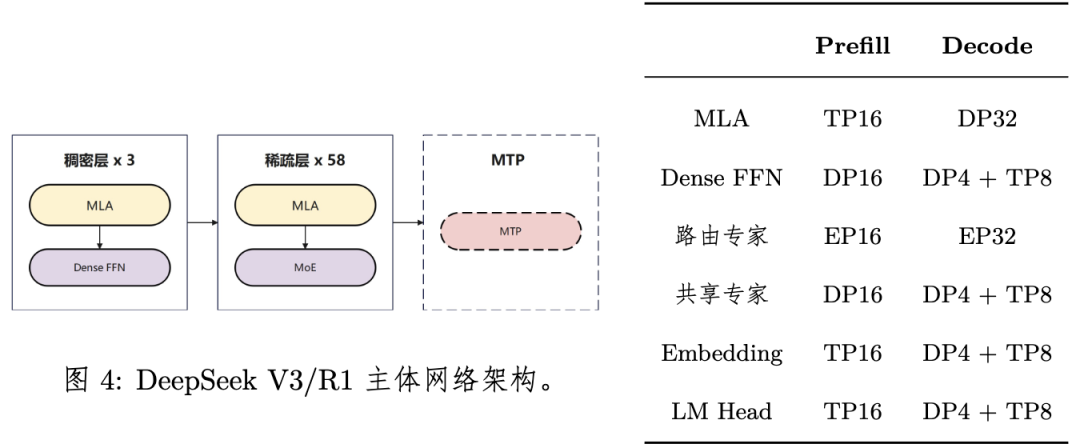
DeepSeek V3/R1模型共3个稠密层、58个稀疏层以及一个MTP层,每层包括MLA模块和Dense FFN/MoE模块。
关于多头潜在注意力(MLA)的部署,Prefill阶段采用Attention前序计算DP16,Attention TP16,Attention后序计算DP8+TP2的混合部署策略,Decode阶段则采用业界主流的DP32与权重吸收的部署方式。
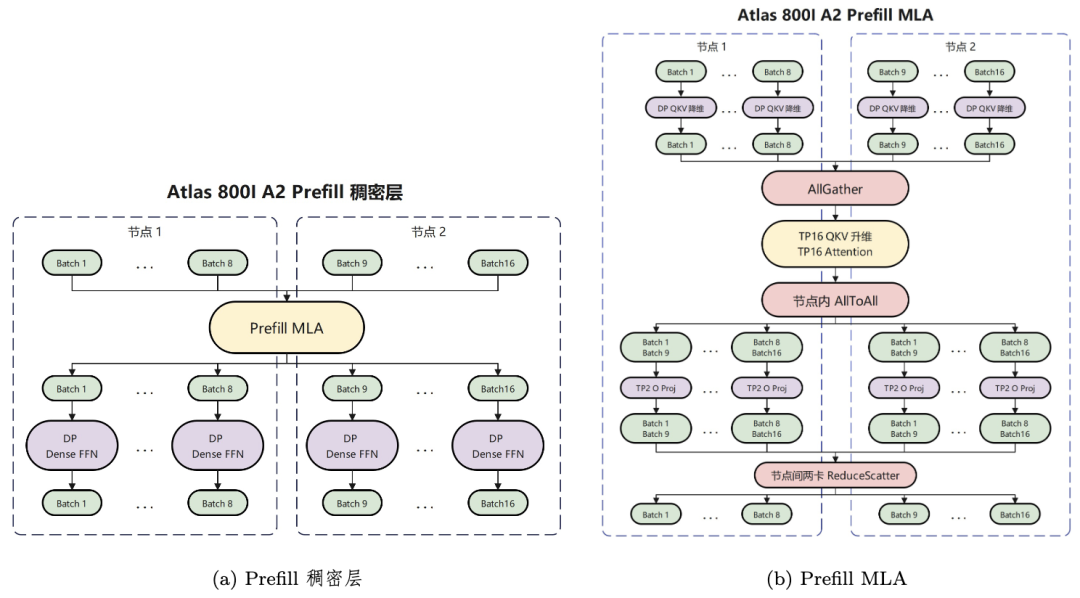
Dense FFN部署在Prefill阶段采用全DP的部署方式,Decode阶段综合考虑FFN性能和通信耗时,以及权重所需内存,选择采取DP4+TP8的部署策略。
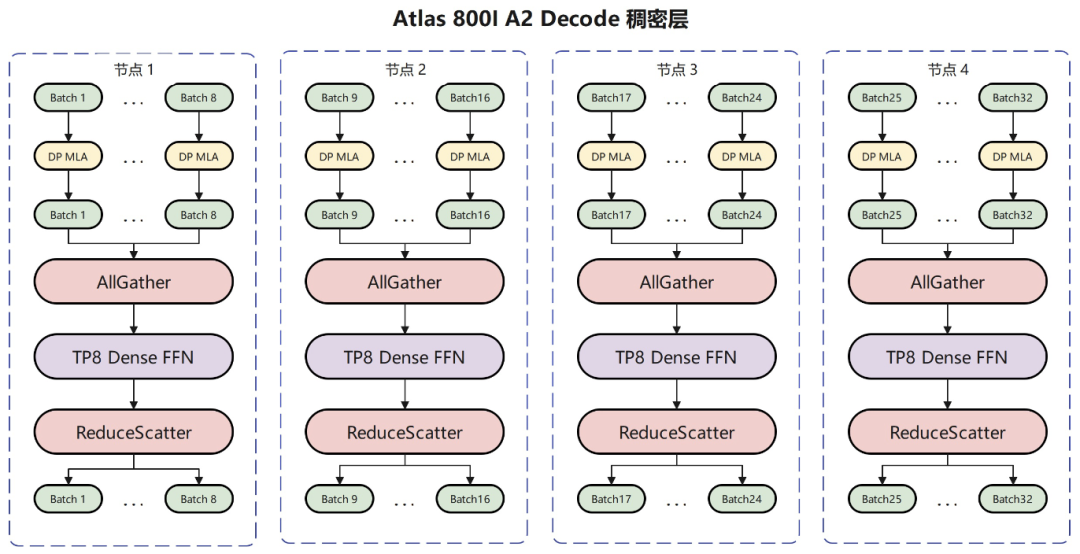
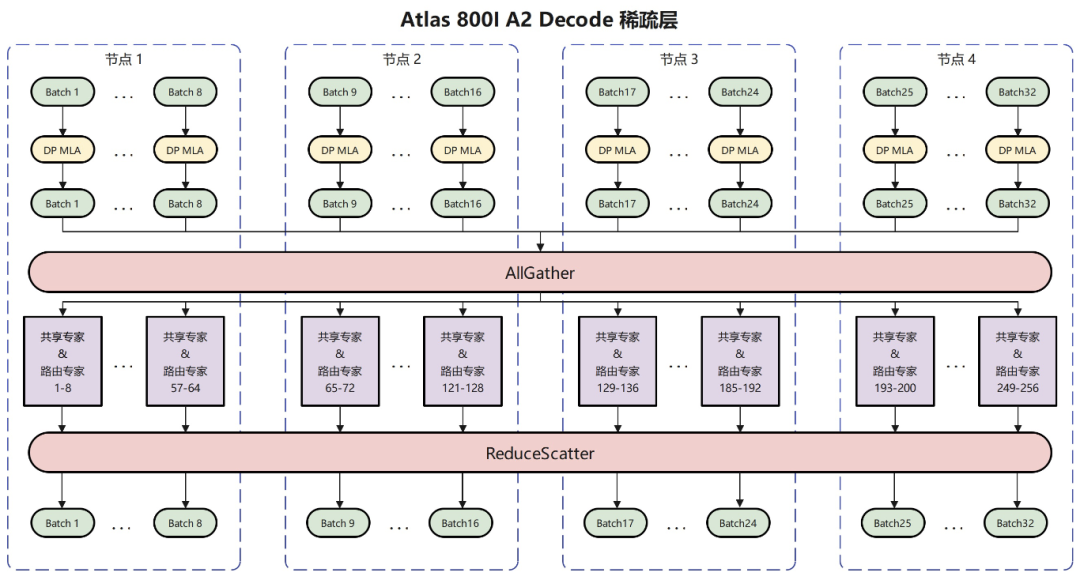
混合专家(MoE)在Prefill和Decode阶段都采用了业界主流的EP并行部署策略,即将256个路由专家平均地部署到所有昇腾卡上。
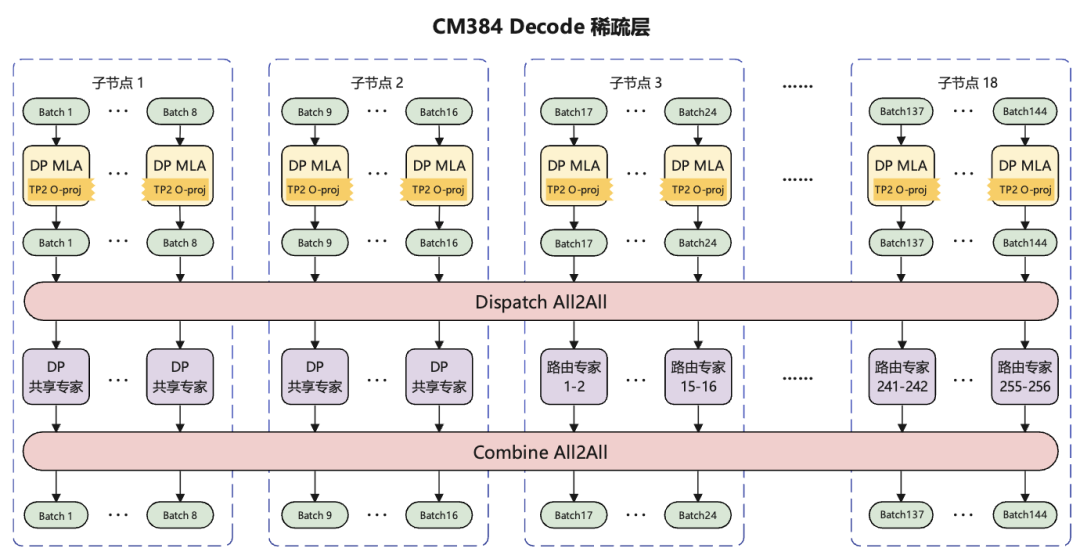
CloudMatrix 384超节点部署方案在Prefill阶段的部署方案与Atlas 800I A2基本相同,主要差异是在CM384上MoE模块的通信方式为All2All,在Decode阶段,MoE模块的主要性能瓶颈为权重搬运。
但在CM384上,子节点间的互联带宽相比Atlas 800I A2大大提高,这使得大规模的EP部署成为可能。

技术报告提到,华为团队对框架侧性能进行了很多优化,涉及vLLM的一些关键环节,例如支持下发水平扩展,采用请求长度感知与KVCache亲和等高级调度策略,简化系统通讯链路,多核全并行、全异步的高效前后处理,降低NPU闲置率等等,以及在API Server扩展技术、MoE模型负载均衡方面进行了一些技术改良。
同时也对模型侧性进行了通信优化。因为大模型多卡部署时,卡间并行方式包括数据并行(DP)、张量并行(TP)、专家并行(EP)等,不同的卡间并行方式对多卡间通信方式和通信算子有着不同的需求,从而影响模型部署时的通信时延。
此外,昇腾芯片支持多种计算资源如张量计算单元、向量计算单元,以及通信资源的并发使用,这为尽可能发挥硬件的算力和带宽提供了支持。

还有对昇腾算子性能的优化,具体涉及对MLA场景的Attention算子进行计算过程的优化以及硬件亲和的性能优化,实现提升Attention算子性能接近1倍,非MTP场景算力利用率达到55%,使用一个MTP模块场景算力利用率达到60%。
以及对MoE通信算子优化,华为团队提出了两个通算融合算子,SMTurbo-CPP技术以及支持细粒度的分级流水算法等。
基于Altas 800I A2性能分析显示,Decode性能对于序列长度是2K输入+2K输出的测试情形,每卡平均并发数为72,此时端到端耗时为99.6ms,卡均吞吐为723 Tokens/s。
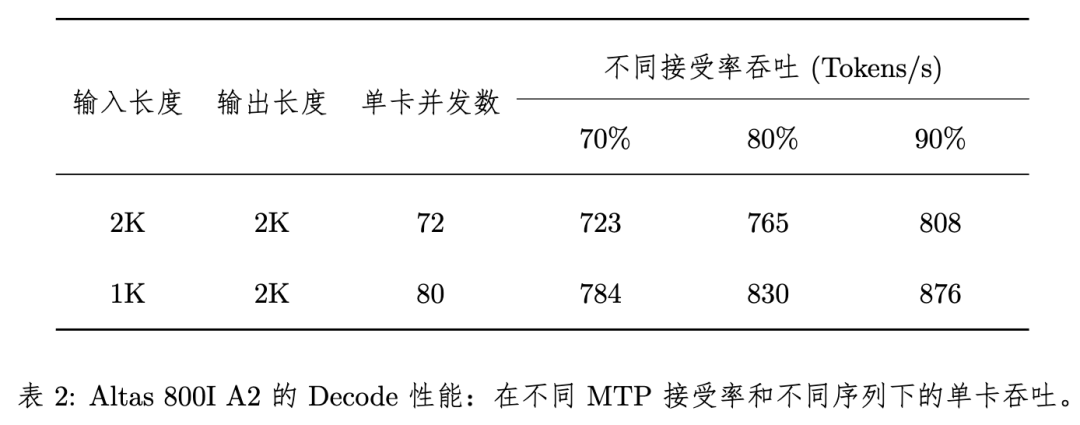
根据DeepSeek披露的数据,MTP接受率可达80%∼90%,如果按照90%的MTP接受率来估算,2K输入+2K输出的Decode单卡吞吐可达808 Tokens/s。
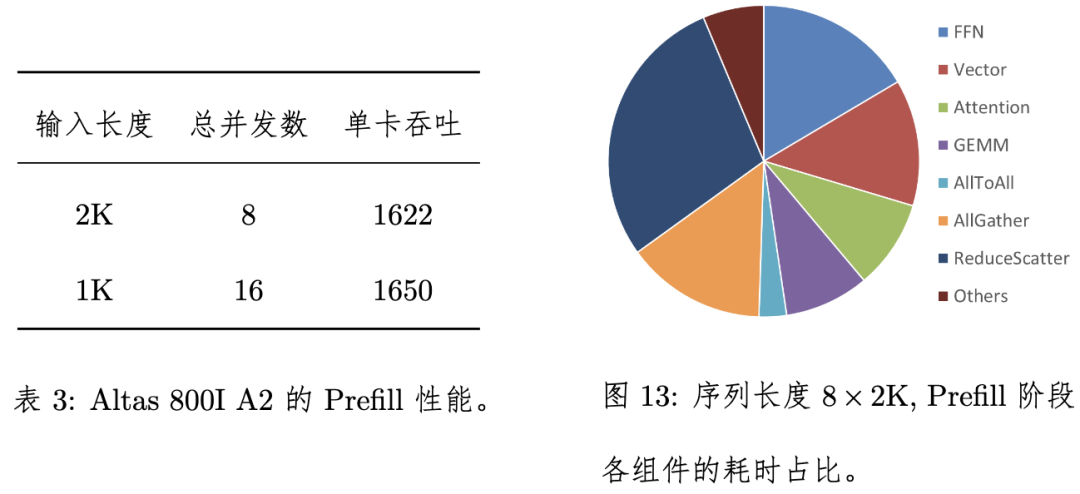
Prefill性能对于序列长度是2K,共8 batch拼成一共16K序列的测试场景,端到端耗时为631ms,卡均吞吐为1622 Tokens/s,大并发的Prefill阶段采用Micro-batch技术可以得到相当大的吞吐收益,据测算,Altas 800I A2在Prefill阶段可进一步达到卡均3095 Tokens/s的吞吐。
报告中提到,2025年4月,硅基流动联合华为云基于CloudMatrix 384超节点昇腾云服务,采用与本报告完全相同的大规模专家并行方案正式上线DeepSeek-R1,该服务在保证单用户20 TPS(等效50ms时延约束)水平前提下,单卡Decode吞吐突破1920 Tokens/s。
华为团队在技术报告最后表示,当前已经完成了完全在昇腾服务器上部署DeepSeek-V3/R1模型的方案,但后续还有一些工作需要完善,以进一步提升性能和支撑更多场景,例如对低时延场景的极致优化,Micro-batch优化方案,探索针对MoE部分INT4的量化技术,MLA层算子量化支持以及序列负载均衡优化方案等等。
根据外界分析和公开数据显示,用英伟达H20 GPU部署DeepSeek模型的单卡实际吞吐量可能在1600-2700 tokens/s范围内,华为可能会率先对H20占据的市场份额进行冲击。
近期,业内也传出华为正在加紧测试其最新、最强大的AI处理器昇腾910D,旨在取代英伟达的部分高端产品。据悉,华为已与一些中国科技公司接洽,商讨测试这款新芯片的技术可行性,预计最早将于5月底推出首批处理器样品,最新版本能与英伟达H100芯片性能比肩乃至超越。

-END-

(文:头部科技)