


大语言模型(LLM)已成为规划复杂任务的强大工具。虽然现有方法通常依赖于 “思考 – 行动 – 观察”(TAO)过程,但这些方法受限于 LLM 固有的知识局限性。检索增强生成 (RAG) 则利用外部数据库,将 LLM 生成与检索到的信息相结合。而将 RAG 应用于实际任务规划仍然面临着两个方面的挑战:
1. 可扩展性:通过遍历现有指令并将其组合成新的序列来扩展指令图的范围的能力,帮助 LLM 完成没有预定义路径的任务。
2. 可迁移性:开发能够快速适应新任务的技术,使模型能够从有限的示例中有效地学习。
针对大模型任务规划中的可扩展性与可迁移性挑战,华为2012中央软件院新加坡团队王政博士主导提出了InstructRAG方案,通过多智能体协同的元强化学习架构,实现了:1)基于强化学习的指令图拓扑扩展;2)元学习驱动的少样本任务迁移。在跨领域的复杂任务测试中(包括多跳推理、具身决策、在线购物和科学问答),相较现有最优方法取得19.2%的性能提升,并在50%噪声干扰下仅表现出11.1%的性能衰减,展现出较强的复杂场景适用性。

-
论文标题:InstructRAG: Leveraging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning
-
论文链接:https://arxiv.org/abs/2504.13032
InstructRAG 框架主要包含三个主要组件:
1. Instruction Graph:用于组织过去指令路径的图;
2. RL-Agent:通过强化学习扩展图覆盖范围的智能体;
3. ML-Agent:使用元学习提升任务泛化能力的智能体。
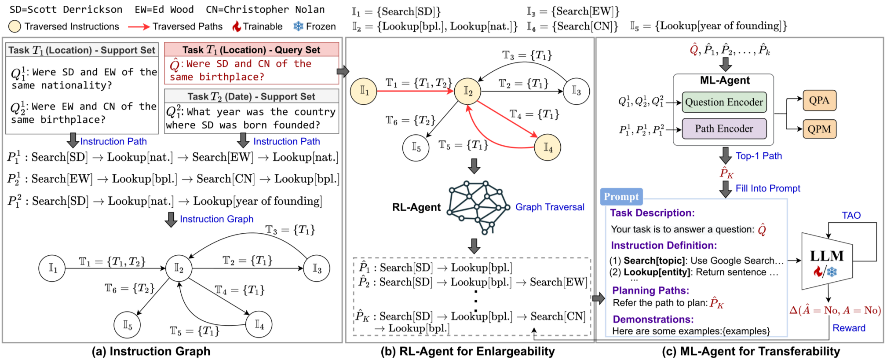
核心思路
指令图(Instruction Graph)
有向图 G (V, E) 组织过去的指令路径(正确动作的序列)。节点(V)表示图中指令集 I,对相似的指令进行聚类。边 (E)表示任务集 T,记录路径中涉及的任务和相关问题。该图是通过迭代插入来自过去成功路径的指令来构建的,使用近似最近邻 (AKNN) 搜索和阈值确定是否创建新节点或添加到现有节点。指令的组合能够创造出解决以前未曾见过的问题的新途径。
强化学习智能体(RL-Agent)
在指令图中选择节点的过程可以被看作马尔可夫决策过程(MDP),作者使用强化学习 (Reinforcement Learning) 训练的智能体,遍历指令图并识别给定任务的候选指令路径,可有效探索指令图的可扩展性。
1. 状态(state): 输入问题与各种图元素之间的余弦相似度。
2. 行动(action):将当前节点包含在路径中或排除它。
3. 奖励(reward):端到端性能指标(例如 F1 Score)。
4. 策略学习(policy learning):该智能体使用策略梯度方法进行优化,并使用历史数据进行热启动以加速训练。这种方法可以通过找到最优指令路径来实现有效的检索增强。
元学习智能体(ML-Agent)
ML-Agent 是使用元学习(Meta Learning)训练的智能体,用来增强可迁移性。它会从 RL-Agent 提供的候选路径中选择最相关的路径并为 LLM 生成提示。其模型架构包括:1. 共享自注意力层的问题编码器和路径编码器,2. 从 Transformer 激活中获取的特征表示。
ML-Agent 的训练包含着两个阶段:
1. 预训练:优化问题路径对齐(QPA)和问题路径匹配(QPM)两个任务。
2. 微调:端到端优化规划的性能。
这种方法允许模型通过仅使用几个示例进行更新来推广到新任务,从而增强检索增强生成的多智能体协作。
InstructRAG 整体框架
1. 训练阶段:使用来自可见训练任务的 support set 和 query set 协作迭代训练 RL-Agent 和 ML-Agent。
2. 少量样本学习阶段:使用来自支持集的少量样本示例,智能体的参数可以快速适应未见过的任务。
3. 测试阶段:使用未知任务上的 query set 来评估模型适应的有效性。
这个整体框架通过 RL-Agent 增强可扩展性,通过 ML-Agent 增强可迁移性。
实验结果
本文的实验在四个广泛使用的数据集上进行:
-
HotpotQA:多跳推理任务;
-
ALFWorld:模拟环境中的具体任务;
-
Webshop:网上购物网页导航任务;
-
ScienceWorld:基础科学推理任务。
使用了 GLM-4,GPT-4o mini 和 DeepSeek-V2 三个 LLM,baseline 包括 ReAct,WKM,Reflexion,GenGround 和 RAP。
评估指标分别为 HotPotQA 的 F1 Score,ALFWorld 的 Success Rate 以及 WebShop 和 ScienceWorld 的 Reward Score。
1. 对未见过任务的表现:
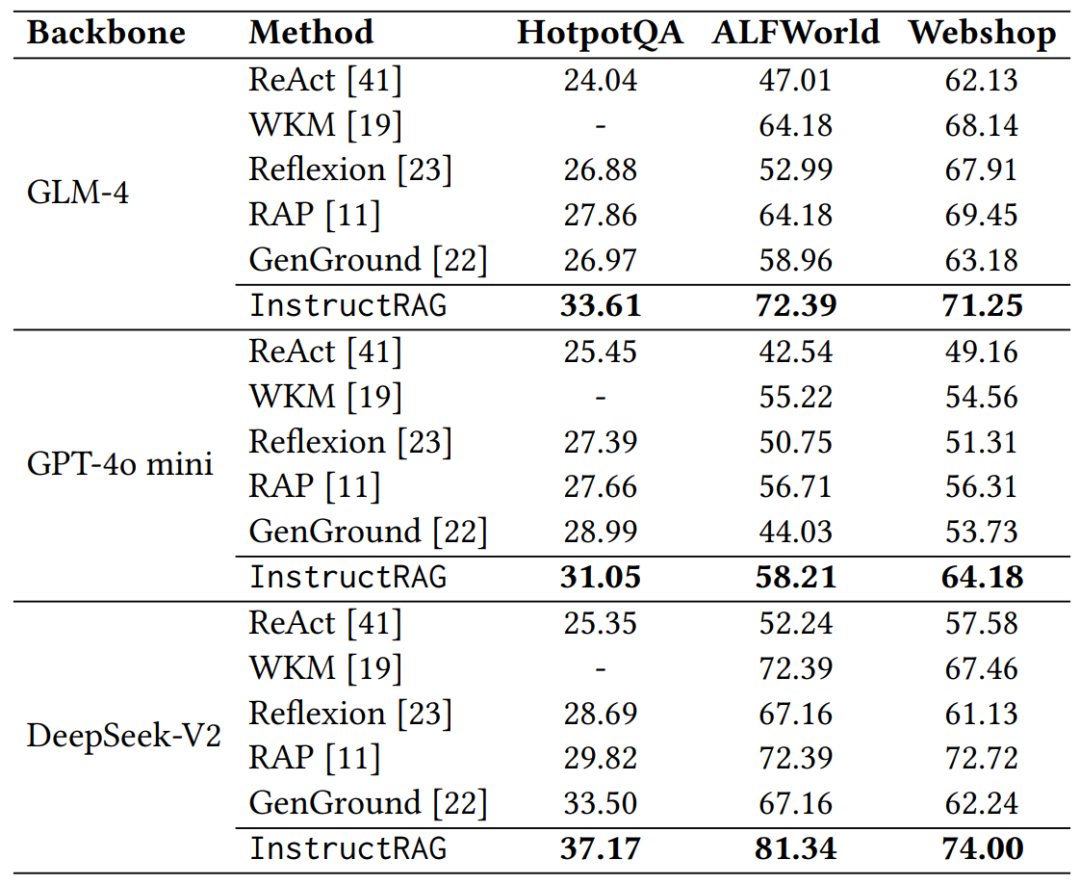
InstructRAG 在三个 LLM 上指标明显优于所有 baseline,相较于最佳 baseline RAP,分别在 HotpotQA,ALFWorld 和 Webshop 上提升了 19.2%,9.3% 和 6.1%。
2. 跨数据集泛化:

通过将训练好的模型从 HotpotQA 应用于 ScienceWorld 数据集中的全新任务,InstructRAG 也表现出了强大的泛化能力。
3. 对已见过任务的表现:

实验结果表明 InstructRAG 在可见的训练任务上的表现优于 RAP。
4. 抗噪声能力:

即使噪声率为 50%,InstructRAG 的性能仅下降了 11.1%,而 RAP 的性能下降了 27.2%。这表明 InstructRAG 具有强大的抗噪声能力。
5. 在 HotpotQA 上验证可扩展性和可迁移性的消融实验:
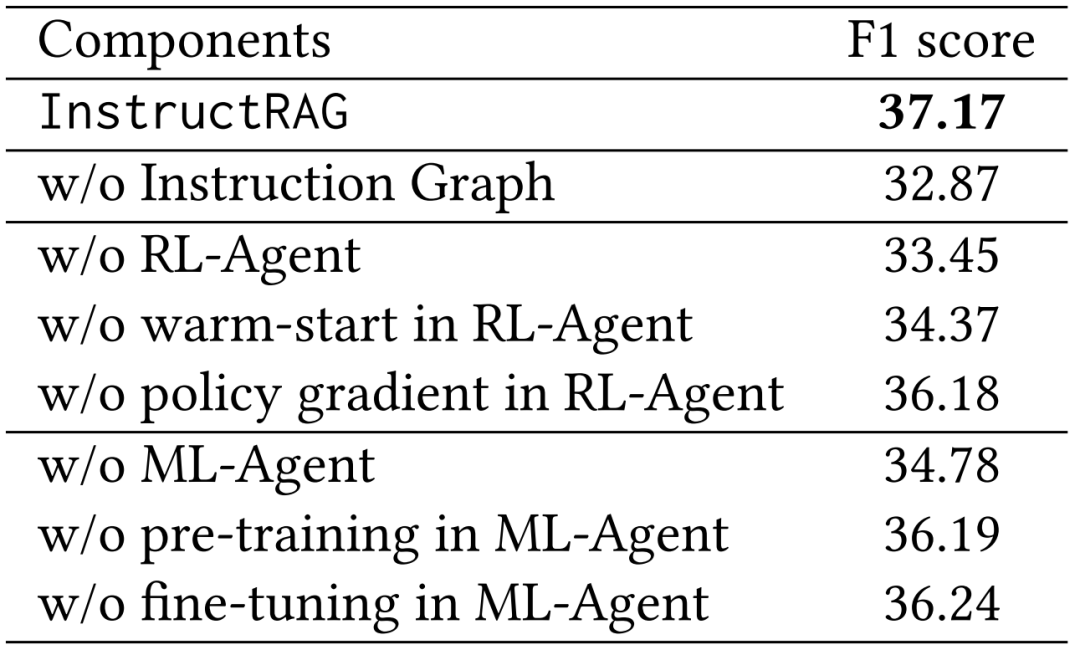
缺少了任何一个组件,InstructRAG 在 HotpotQA 上的 F1 score 都会有所下降,这表明每个组件的存在都对其性能有重大贡献。
6. 少样本学习的影响:
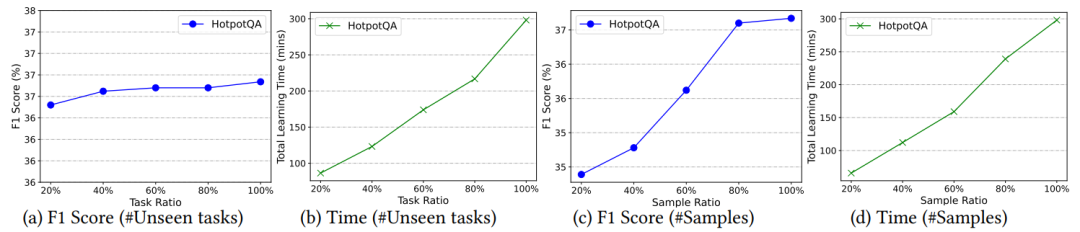
如图中 (a)-(b) 所示,任务比例从 0.2 变化到 1.0,随着任务数量增加,有效性保持稳定,这表明在不同任务之间具有较强的迁移性。由于包含了额外的训练数据,运行时间随着任务的增加而增加。此外,对于每个任务,样本比例从 0.2 变化到 1.0。如图中 (c) 和 (d) 所示,有效性改善,并在约 0.8 的样本比例处收敛,而随着更多样本用于训练,运行时间也在增加。
总结
综上,该工作提出了一种系统化的方法,利用 RAG 进行任务规划,解决了可扩展性和可迁移性的问题。InstructRAG 集成了指令图,RL-Agent 和 ML-Agent,优化端到端任务规划性能。在四个数据集上进行的大量实验表明,InstructRAG 的性能卓越,与现有的方法相比,提升高达 19.2%。该框架展现出卓越的抗噪鲁棒性,并能够使用少量样本快速适应新任务。未来的工作将集中于进一步增强 InstructRAG 的泛化能力。
团队介绍
该工作由华为新加坡中央软件院团队独立完成,团队以深耕 AI 基础软件作为目标,聚焦大模型基础软件技术创新研究,包括 RAG、AI Agent、多模态等前沿基础技术研究和能力构建,致力于构建基于强大算力和大模型的应用技术,以推动 AI 基础软件的发展。

©
(文:机器之心)