
软件产品正在面临一场生死考验!

Andrej Karpathy 刚刚抛出了一个尖锐观点:那些只有复杂UI界面、没有脚本支持、建立在不透明二进制格式上的软件产品,在人类与AI深度协作的时代将会被淘汰。

Karpathy 认为,如果大语言模型无法读取和操作软件的底层表示和相关设置,那么AI就无法与专业人士共同驾驭你的产品,也无法为更多有抱负的专业消费者提供「vibe coding」体验。

软件产品的生死榜单
Karpathy给出了一份详细的风险评估清单:

高风险产品(二进制对象/工件,没有文本DSL:所有Adobe产品、数字音频工作站(DAW)、CAD/3D软件。这些软件界面复杂,但底层数据格式封闭,AI根本无法理解和操作。
中高风险产品(部分支持文本脚本):Blender、Unity。虽然有一定的脚本能力,但核心功能仍然依赖复杂的UI操作。
中低风险产品(大部分已经是文本,有一定的自动化/插件生态):Excel。虽然有VBA等脚本支持,但仍有许多功能需要通过UI操作。
低风险产品(已经完全基于文本):VS Code、Figma、Jupyter、Obsidian等IDE和编辑器。这些产品天生就是为文本和代码而生,AI可以轻松理解和操作。

Karpathy警告说,虽然AI在理解人类UI方面会越来越强大(比如Operator等产品),但那些试图完全等待这个未来而不愿意主动适应当前技术的产品,将会面临困境。
开发者热议
AIwithAmirthan(@AIwithAmirthan)简洁地总结道:
没有UI = 新UI
Emiliano Negri提出了一个简单的解决方案:构建UI来创建内容,然后将设置导出为JSON格式。这样人类和经过适当指导的LLM都可以创建内容。
clem(@clementmiao)分享了自己的经历:
我很想在虚幻引擎或Godot中进行vibe coding,但除了UI问题,基础元素(如Godot中的引用ID)本身也不适合良好的vibe coding。结果,我最终用phaser.js制作了游戏。
他还展示了自己开发的一个AI原生应用,在各处都有上下文钩子:

Dominik Lukes(@techczech)毫不客气地指出:
Word、PowerPoint和其他微软产品中Copilot侧边栏的惨败就是完美的例子!它们只是一堆遗留的意大利面条代码,即使MCP也救不了它们!
这戳中了许多传统软件的痛点:表面上集成了AI功能,但由于底层架构的限制,AI根本无法真正理解和操作这些软件。
m_11(@instance_11)提出了一个更加激进的问题,直接质疑了传统应用程序存在的必要性:
为什么还需要应用程序?当AI系统可以制作定制解决方案时,为什么要通过预定义的操作来过滤动作?当你可以完全访问图像的RGB值并根据当前查询的需要操作它们时,为什么要调用Photoshop函数?
Larry Velez分享了实践经验:
我们发现LLM真的很喜欢高度结构化的格式,如CAD STEP和STL或DocBook。它们似乎喜欢在组织良好和结构受限的格式中工作。
他认为,虽然UX会改变,但结构良好的数据格式将继续存在并蓬勃发展,因为LLM可以更轻松地处理像DocBook这样的格式——它们有人类从未有过的耐心。
Bezi(@bezi_ai)展示了他们已经在用LLM加速Unity开发的成果:
我们已经在用LLM加速Unity开发了😊 + 很快将支持其他游戏引擎
UI的未来在哪里?
Pietro Casella(@PietroCasella)提出了「AI体验」的概念:
我一直称之为「AI-eXperience」,即AI看到和感受到的东西。大多数软件让AI失明,给它不公平的思考机会,降低带宽,没有记忆,所以它自然会困惑。
他认为,Operator AI的问题在于它受时间限制,使用为人类制作的功能,一次只能点击一下。这就像AI有「可访问性」问题。可远程控制的软件允许AI进行复合操作和更好的感知。
Garric G. Nahapetian(@garricn)总结道:
开源纯文本DSL将获胜,因为LLM可以更容易地理解和计算它们。一切都是纯文本。这并不意味着UI不会存在,但它们应该建立在文本之上。用户使用滑块做的任何事情都应该能够转换为纯文本,反之亦然。
Karpathy的AI 编程实战心法
在谈到产品需要为AI 开放接口的同时,Karpathy 还分享了他自己在AI 辅助编程中的实践经验。

他发现自己在进行AI辅助编程时(特别是那些他真正关心的专业代码,而非随意的vibe code),已经形成了一套特定的节奏:
第一步:把所有相关内容塞进上下文(在大项目中这可能需要很长时间。如果项目足够小,就把所有东西都塞进去,比如使用命令files-to-prompt . -e ts -e tsx -e css -e md --cxml --ignore node_modules -o prompt.xml)
第二步:描述下一个单一、具体的增量变化。不要直接要代码,而是先询问几种高层次的方法和优缺点。几乎总是有多种方式来做事情,而LLM的判断并不总是很好。
第三步:选择一种方法,要求初稿代码。
第四步:审查/学习阶段:手动在侧边浏览器中查找所有之前没调用过或不太熟悉的函数的API文档,要求解释、澄清、更改,或者退回去尝试不同的方法。
第五步:测试。
第六步:Git提交。
然后询问接下来可以实现什么的建议,重复这个过程。
Karpathy强调,重点是要对这个「过于热心的初级实习生天才」保持非常紧密的控制——它拥有软件的百科全书式知识,但也会经常胡说八道,过度自信,对好代码几乎没有品味。
重点是要慢、防守、小心、偏执,并且总是抓住内联学习的机会,而不是委托。
验证鸿沟:AI编程的真正瓶颈
Karpathy还深入探讨了AI编程中的一个核心问题——「验证鸿沟」。
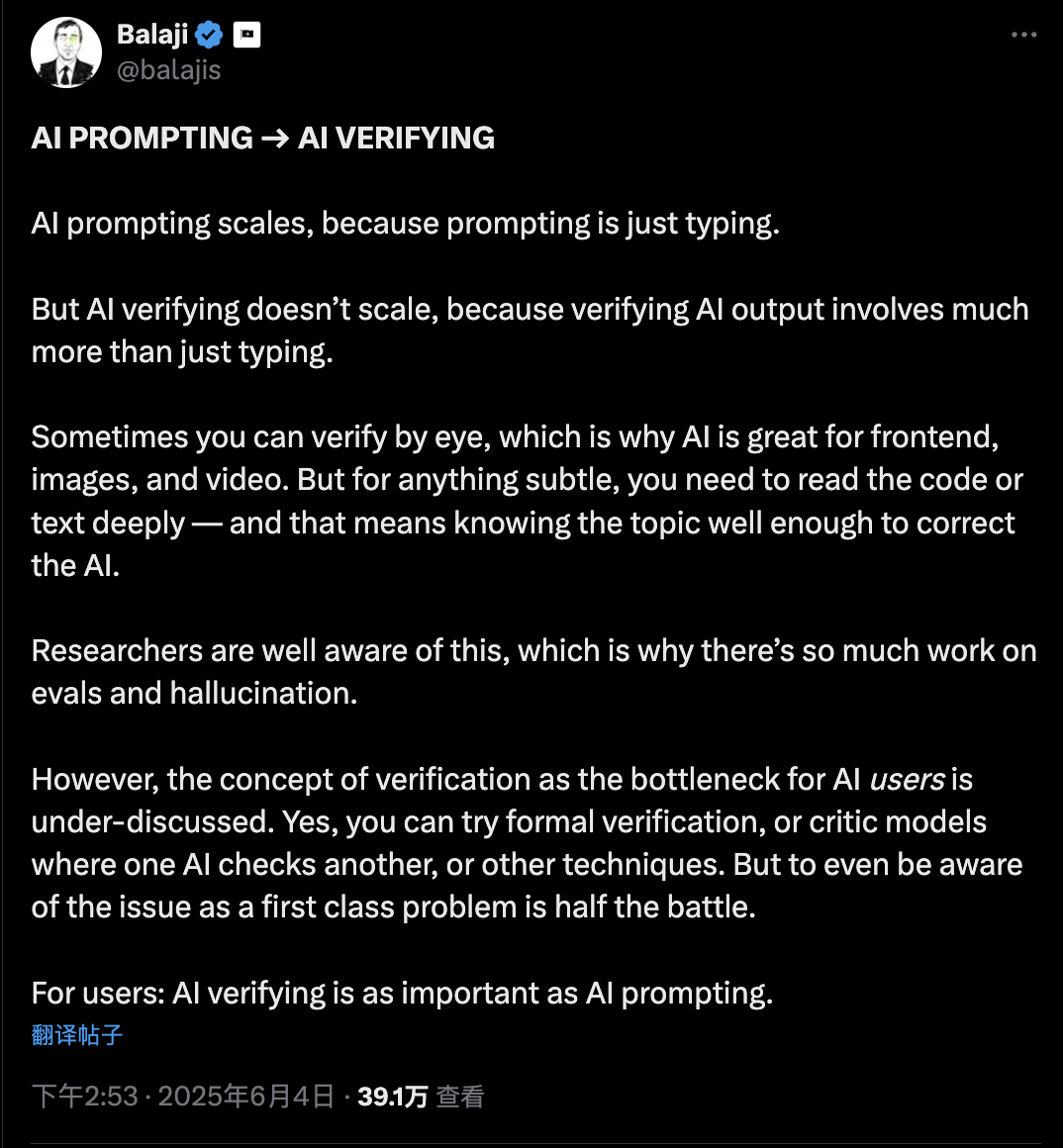
他引用了Balaji的观点,并用GAN的术语来解释创作中的两种模式:
生成和判别。

就像绘画一样——你画一笔(生成),然后看一会儿是否改善了画作(判别)。这两个阶段在几乎所有创造性工作中都是交替进行的。
关键是,判别在计算上可能非常困难:
-
图像是最容易的。图像生成团队可以创建巨大的结果网格来决定一张图像是否比另一张更好。感谢你大脑中用于快速处理图像的巨大GPU。
-
文本要困难得多。它是可浏览的,但你必须阅读,它是语义的、离散的和精确的,所以你还必须推理(特别是在代码中)。
-
音频可能更难,因为它强制有时间轴,所以甚至不能浏览。你被迫花费串行计算,根本无法并行化。

Karpathy指出,在编程中,LLM已经将生成阶段压缩到了几乎瞬时,但在解决判别阶段方面做得很少。一个人仍然必须盯着结果并判断它们是否好。这是他对LLM编程的主要批评——它们随意地在每个查询中吐出太多任意复杂度的代码,假装没有第二阶段。

获得那么多代码是糟糕和可怕的。
相反,LLM必须积极地与你合作,将问题分解成小的增量步骤,每个步骤都更容易验证。它必须预测判别阶段的计算工作并尽可能减少它。它必须真正关心。

这让Karpathy想到了非程序员对编程的最大误解。他们认为编程是关于编写代码的。
不是的。编程是关于盯着代码看的。
——将它全部加载到你的工作记忆中,来回踱步,思考所有的边缘情况。
如果你在他「编程」时随机抓住他,他可能只是在盯着屏幕,如果被打断,会非常生气,因为这在计算上太费力了。如果我们只是让生成变得更快,但不减少判别(这占了大部分时间!),那么显然编程的整体速度不会提高(参见阿姆达尔定律)。

软件产品和开发者都站在了AI时代的十字路口。
对于软件产品来说,选择已经很明确:要么为AI开放接口,要么被时代抛弃。
而对于开发者来说,真正的挑战不是学会使用AI生成代码,而是掌握AI辅助编程的正确节奏,理解验证比生成更重要——这才是真正提升编程效率的关键。
(文:AGI Hunt)