

传统强化学习的三大痛点!
想象教AI解数学题:答对给1分,答错给0分(数值反馈)。但研究者发现这套“打分制”存在致命缺陷:
-
成绩卡壳:题量翻8倍,分数纹丝不动 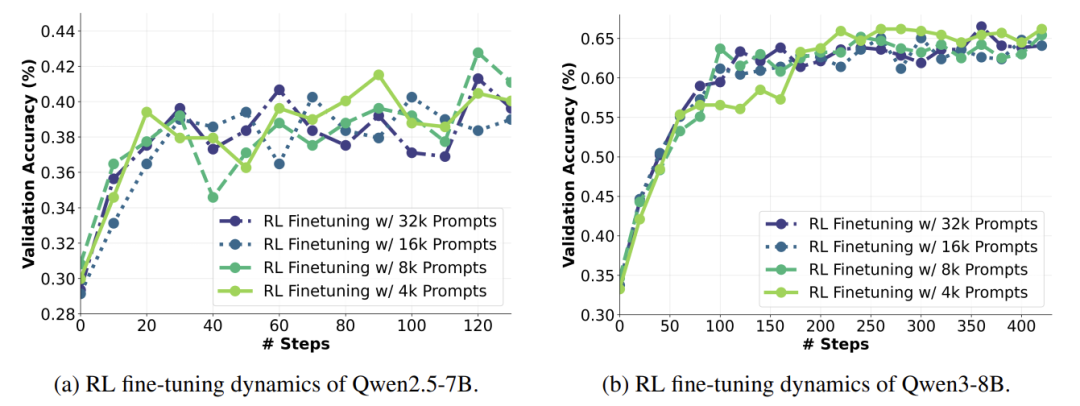
-
自我反思失效:模型的“灵光一闪”对解题帮助微乎其微 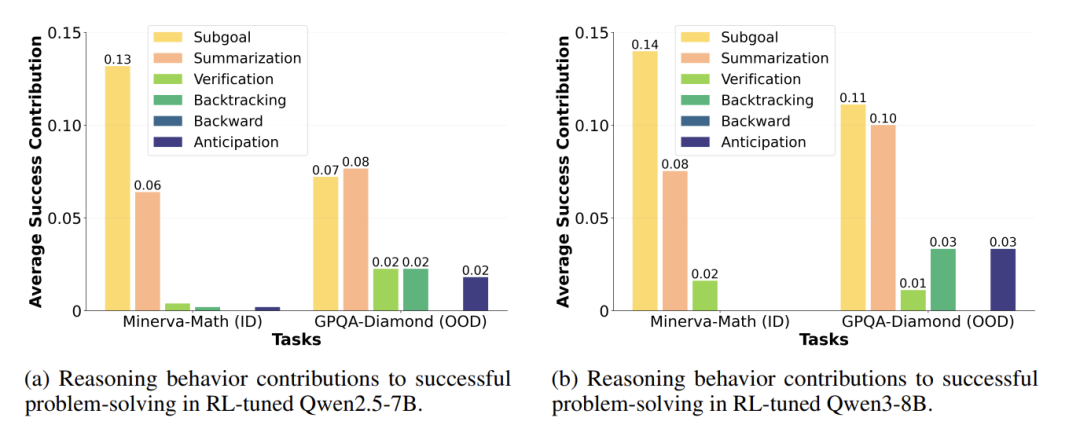
-
顽固错误:29%的题反复做错,堪称“学渣” 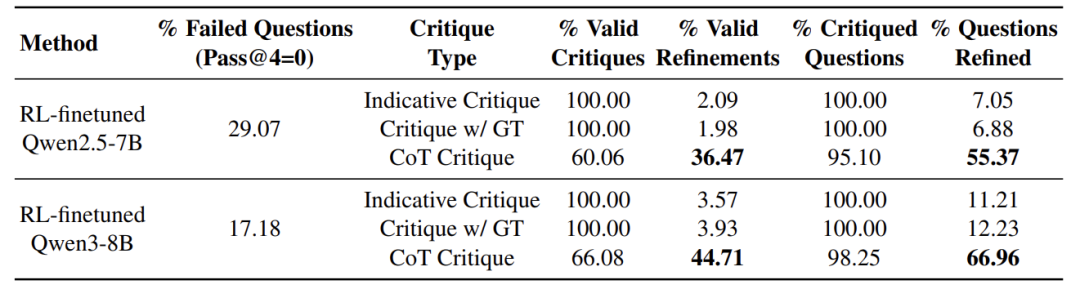
“数值反馈像考试分数,只告诉学生对错,却不解释错在哪、如何改。”

论文:Critique-GRPO: Advancing LLM Reasoning with Natural Language and Numerical Feedback
链接:https://www.arxiv.org/abs/2506.03106
破局:当数值反馈遇上“语言批评”
研究者给LLM请了位“批评家”(GPT-4o),针对错误答案写小作文(CoT Critique):
[错误分析示例]
Step 1:学生误用相似三角形公式
Step 4:正确推导出R=2r
Step 6:角度计算错误,正确解法应用内切圆公式…
结论:答案错误(正确答案cos2θ=7/25)
这种带步骤批注的反馈,让模型修正成功率暴涨3倍!相比简单说“错”或直接给答案,详细批改才是提分关键。
方法:Critique-GRPO双反馈引擎
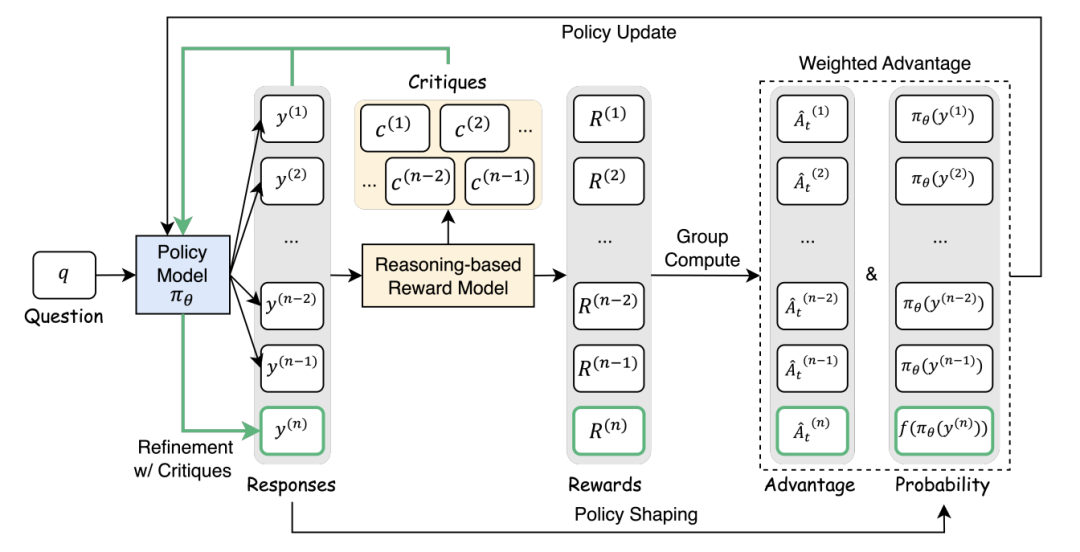
框架核心三步骤:
-
初稿生成:模型先写答案(如数学题解法) -
批评精修:GPT-4o写批注 → 模型根据批改重写答案 -
双轨学习:融合初稿和精修稿训练,强化有效修改,严惩失败修正
公式(通俗版):
优势值 = (当前答案得分 – 平均分)
通过对比组内表现,让AI认清“什么是真正的好答案”
实验:推理任务的全面突破
在数学竞赛(MATH/Olympiad)和科学推理(定理证明/化学生物)八大任务中:
-
平均准确率提升5% (Qwen3-8B模型达65.86%) -
碾压专家示范:比融合人类解题示例的LUFFY方法高4.5分 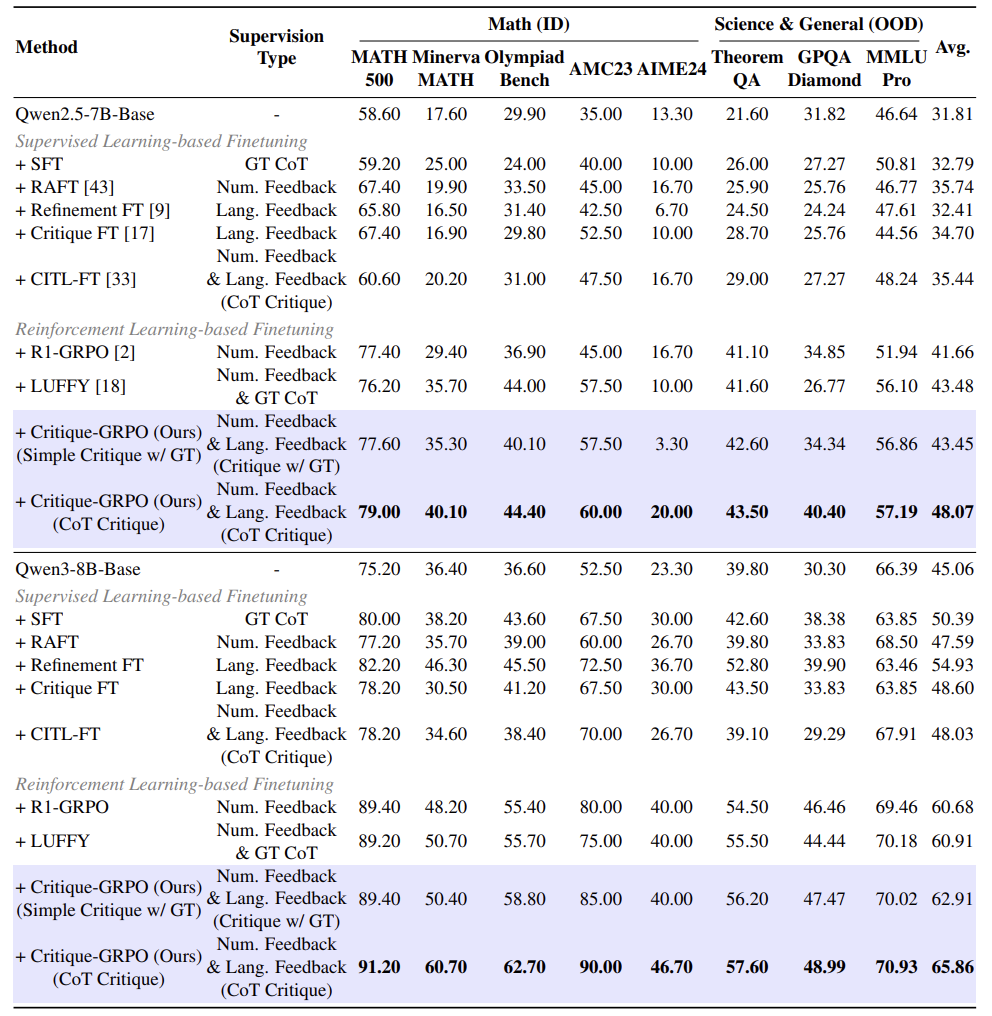
-
解题更简洁:答案长度缩减30%,无效反思减少
反常识发现
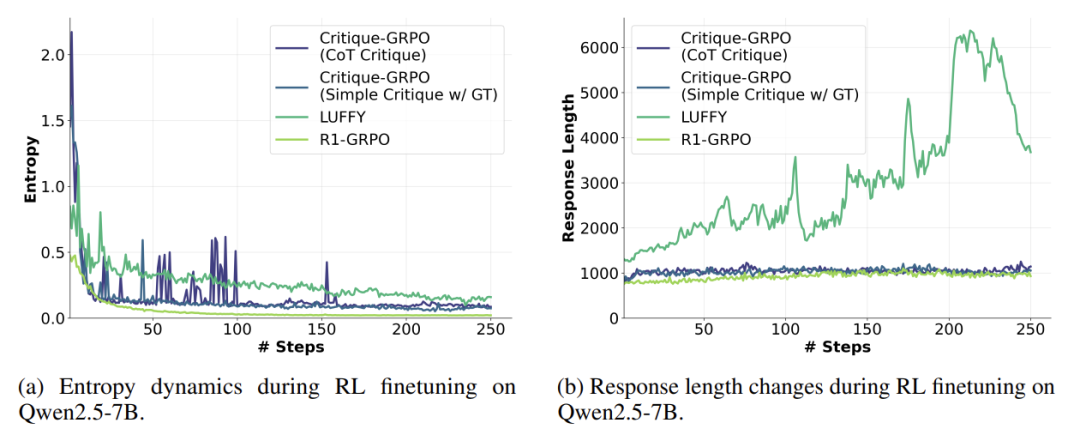
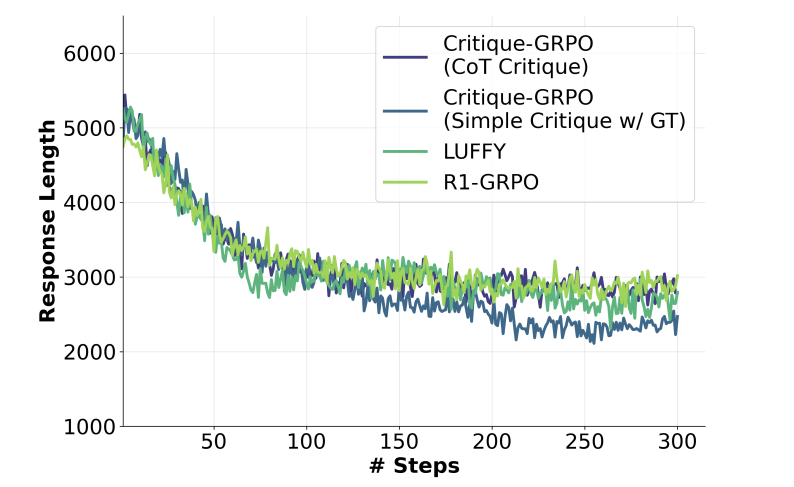
-
迷思1:“思维发散才能学好”(熵值越高越好) → 真相:高质量精修比盲目探索更重要 -
迷思2:“长篇大论=深入思考” → 真相:无效反思拖累效率,精准批评让答案更简洁
意义
这项研究揭示的“批评式学习”机制,对人类教育同样启发深刻:
-
优质反馈 > 题海战术(实验证实8倍题量无效) -
详细批改 > 单纯打分(CoT批注提效300%) -
精炼表达 > 冗长推导(删除无效反思提升速度)
研究者也对未来做了一些展望:
“未来或用于多模态推理——让AI看电路图解物理题,结合视觉与文本批评”
(文:机器学习算法与自然语言处理)