
编辑:Panda
在建模复杂的数据分布方面,扩散生成模型表现出色,不过它的成果大体上与表征学习(representation learning)领域关联不大。
通常来说,扩散模型的训练目标包含一个专注于重构(例如去噪)的回归项,但缺乏为生成学习到的表征的显式正则化项。这种图像生成范式与图像识别范式差异明显 —— 过去十年来,图像识别领域的核心主题和驱动力一直是表征学习。
在表征学习领域,自监督学习常被用于学习适用于各种下游任务的通用表征。在这些方法中,对比学习提供了一个概念简单但有效的框架,可从样本对中学习表征。
直观地讲,这些方法会鼓励相似的样本对(正例对)之间相互吸引,而相异的样本对(负例对)之间相互排斥。研究已经证明,通过对比学习进行表征学习,可以有效地解决多种识别任务,包括分类、检测和分割。然而,还没有人探索过这些学习范式在生成模型中的有效性。
鉴于表征学习在生成模型中的潜力,谢赛宁团队提出了表征对齐 (REPA) 。该方法可以利用预训练得到的现成表征模型的能力。在训练生成模型的同时,该方法会鼓励其内部表征与外部预训练表征之间对齐。有关 REPA 的更多介绍可阅读我们之前的报道《扩散模型训练方法一直错了!谢赛宁:Representation matters》。
REPA 这项开创性的成果揭示了表征学习在生成模型中的重要性;然而,它的已有实例依赖于额外的预训练、额外的模型参数以及对外部数据的访问。
简而言之,REPA 比较麻烦,要真正让基于表征的生成模型实用,必需一种独立且极简的方法。
这一次,MIT 本科生 Runqian Wang 与超 70 万引用的何恺明出手了。他们共同提出了 Dispersive Loss,可译为「分散损失」。这是一种灵活且通用的即插即用正则化器,可将自监督学习集成到基于扩散的生成模型中。

-
论文标题:Diffuse and Disperse: Image Generation with Representation Regularization
-
论文链接:https://arxiv.org/abs/2506.09027v1
分散损失的核心思想其实很简单:除了模型输出的标准回归损失之外,再引入了一个用于正则化模型的内部表征的目标(图 1)。
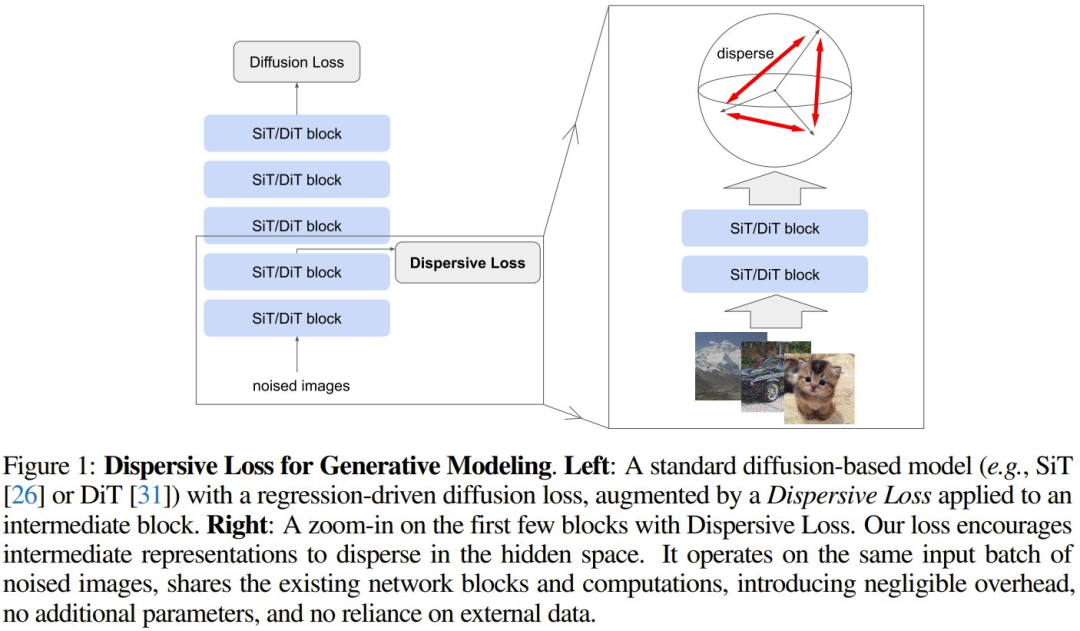
直觉上看,分散损失会鼓励内部表征在隐藏空间中散开,类似于对比学习中的排斥效应。同时,原始的回归损失(去噪)则自然地充当了对齐机制,从而无需像对比学习那样手动定义正例对。
一言以蔽之:分散损失的行为类似于「没有正例对的对比损失」。
因此,与对比学习不同,它既不需要双视图采样、专门的数据增强,也不需要额外的编码器。训练流程完全可以遵循基于扩散的模型(及基于流的对应模型)中使用的标准做法,唯一的区别在于增加了一个开销可忽略不计的正则化损失。
与 REPA 机制相比,这种新方法无需预训练、无需额外的模型参数,也无需外部数据。凭借其独立且极简的设计,该方法清晰地证明:表征学习无需依赖外部信息源也可助益生成式建模。
带点数学的方法详解
分散损失
新方法的核心是通过鼓励生成模型的内部表征在隐藏空间中的分散来对其进行正则化。这里,将基于扩散的模型中的原始回归损失称为扩散损失(diffusion loss),将新引入的正则化项称为分散损失(Dispersive Loss)。
如果令 X = {x_i} 为有噪声图像 x_i 构成的一批数据,则该数据批次的目标函数为:
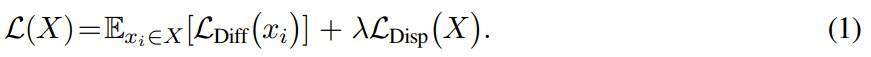
其中,L_Diff (x_i) 是一个样本的标准扩散损失,L_Disp (X) 则是依赖于整个批次的分散损失项,λ 是其加权项。
在实践中,该团队没有应用任何额外的层(如,投射头),而是直接将分散损失应用于中间表示,不增加额外的可学习参数。
该方法是自成一体且极简的。具体而言,它不会改变原始 L_Diff 项的实现:它不引入额外的采样视图,也不引入额外的数据增强,并且当 λ 为零时,它刚好就能约简为基线扩散模型。
这种设计之所以可行,是因为引入的分散损失 L_Disp (X) 仅依赖于同一输入批次中已经计算出的中间表示。这不同于标准对比学习 —— 在标准对比学习中,额外的增强和视图可能会干扰每个样本的回归目标。
前面也说过,分散损失的行为类似于「没有正例对的对比损失」。在生成模型的背景下,这个公式是合理的,因为回归项提供了预先定义的训练目标,从而无需使用「正例对」。这与先前关于自监督学习的研究《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》一致,其中正例项被解释为对齐目标,而负例项则被解释为正则化的形式。通过消除对正例对的需求,损失项可以定义在任何标准批次的(独立)图像上。
从概念上讲,可以通过适当移除正例项,从任何现有的对比损失中推导出分散损失。就此而言,「分散损失」一词并非指特定的实现,而是指一类鼓励实现分散的通用目标。下文将介绍分散损失函数的几种变体。
基于 InfoNCE 的分散损失变体
在自监督学习中,InfoNCE 是被广泛使用且有效的对比损失变体。作为案例研究,该团队提出了与 InfoNCE 损失相对应的分散损失。
数学形式上,令 z_i = f (x_i) 表示输入样本 x_i 的生成模型的中间表示,其中 f 表示用于计算中间表示的层的子集。原始 InfoNCE 损失可以被解读为分类交叉熵目标,它会鼓励让正例对之间具有高相似度,而负样本对之间具有低相似度:
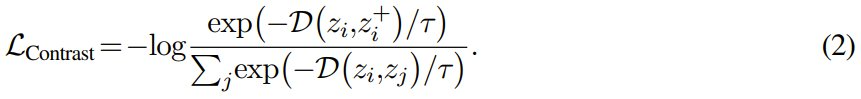
其中,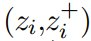 表示一对正例(例如,通过对同一幅图像进行数据增强获得的数据),(z_i,z_j) 表示包含正例对和所有负例对(即 i ≠ j)的任意一对样本。D 表示相异度函数(例如,距离),τ 是一个称为温度的超参数。 D 的一个常用形式是负余弦相似度:
表示一对正例(例如,通过对同一幅图像进行数据增强获得的数据),(z_i,z_j) 表示包含正例对和所有负例对(即 i ≠ j)的任意一对样本。D 表示相异度函数(例如,距离),τ 是一个称为温度的超参数。 D 的一个常用形式是负余弦相似度: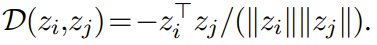
在 (2) 式的对数中,分子仅涉及正例对,而分母包含批次中的所有样本对。根据之前的一些研究,可以将公式 (2) 等效地重写为:

其中,第一项类似于回归目标,它最小化 z_i 与其目标 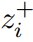 之间的距离。另一方面,第二项则会鼓励任何一对 (z_i,z_j) 尽可能距离拉远。
之间的距离。另一方面,第二项则会鼓励任何一对 (z_i,z_j) 尽可能距离拉远。
为了构造对应的分散损失,这里只保留第二项:
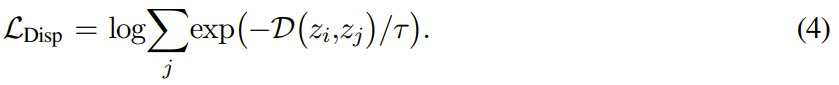
该公式也可以被视为一种对比损失(公式 (3)),其中每个正例对由两个相同的视图 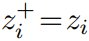 组成,使得
组成,使得 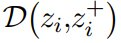 为一个常数。等式 (4) 就等价于
为一个常数。等式 (4) 就等价于
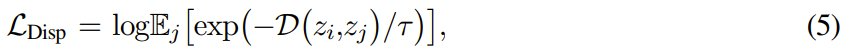
只差一个常数项 log(batch size),而这个常数项不会影响优化过程。 从概念上讲,此损失定义基于参考样本 z_i。为了得到定义在一批样本 Z = {z_i} 上的形式,这里按照之前的研究可将其重新定义为:
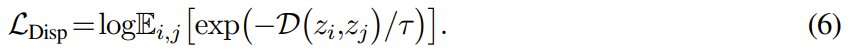
此损失函数对于批次内的所有样本具有相同的值,并且每个批次仅计算一次。在该团队的实验中,除了余弦相异度之外,我们还研究了平方ℓ₂ 距离: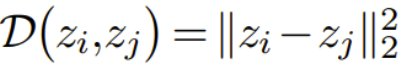 。使用这种 ℓ₂ 形式时,只需几行代码即可轻松计算出分散损失,如算法 1 所示。
。使用这种 ℓ₂ 形式时,只需几行代码即可轻松计算出分散损失,如算法 1 所示。

等式 (6) 中定义的基于 InfoNCE 的分散损失类似于前述先前关于自监督学习的论文中的均匀性损失(尽管这里没有对表示进行 ℓ₂ 正则化)。在那篇论文中的对比表示学习,均匀性损失被应用于输出表示,并且必须与对齐损失(即正则项)配对。而这里的新公式则更进一步,移除了中间表示上的对齐项,从而仅关注正则化视角。
该团队注意到,当 j = i 时,就不需要明确排除项 D (z_i,z_j)。由于不会在一个批次中使用同一图像的多个视图,因此该项始终对应于一个恒定且最小的差异度,例如在ℓ₂ 的情况下为 0,在余弦情况下为 -1。因此,当批次大小足够大时,这个项在那个对数中的作用是充当一个常数偏差,其贡献会变小。在实践中,无需排除该项,这也简化了实现。
分散损失的其他变体
分散损失的概念可以自然延伸到 InfoNCE 之外的一类对比损失函数。
任何鼓励排斥负例的目标都可以被视为分散目标,并实例化为分散损失的一种变体。基于其他类型的对比损失函数,该团队构建了另外两种变体。表 1 总结了所有三种变体,并比较了对比损失函数和分散损失函数。

铰链损失(Hinge Loss)
在对比学习的经典公式中,损失函数定义为独立损失项之和,每个损失项对应一个正例对或负例对。正例对的损失项为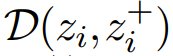 ;负例对的损失项公式化为平方铰链损失,即
;负例对的损失项公式化为平方铰链损失,即  ,其中 ε>0 为边界值。为了构造分散损失函数,只需舍弃正例对的损失项,仅计算负例对的损失项即可。见表 1 第 2 行。
,其中 ε>0 为边界值。为了构造分散损失函数,只需舍弃正例对的损失项,仅计算负例对的损失项即可。见表 1 第 2 行。
协方差损失(Covariance Loss)
另一类(广义)对比损失函数作用于表征的互协方差矩阵。这类损失函数可鼓励互协方差矩阵接近单位矩阵。
举个例子,对于论文《Barlow twins: Self-supervised learning via redundancy reduction》中定义的损失(它计算一个批次中两个增强视图的归一化表征之间的互协方差矩阵),将 D×D 互协方差记为 Cov,其元素以 (m,n) 为索引。则该损失函数会使用损失项 (1 − Cov_mm)² 鼓励对角线元素 Cov_mm 为 1,使用损失项  鼓励非对角线元素 Cov_mn (∀m≠n) 为 0,,其中 w 为权重。
鼓励非对角线元素 Cov_mn (∀m≠n) 为 0,,其中 w 为权重。
在这里的分散损失中,该团队只考虑了非对角线元素 Cov_mn。由于不使用增强视图,因此互协方差就简化为基于单视图批次计算的协方差矩阵。在这种情况下,当表征经过ℓ₂正则化后,对角线元素 Cov_mm 自动等于 1,因此无需在损失函数中显式地处理。最终的分散损失为  。见表 1 第 3 行。
。见表 1 第 3 行。
使用分散损失的扩散模型
如表 1 所示,所有分散损失的变体都比其对应的分散损失更简洁。更重要的是,所有分散损失函数都适用于单视图批次,这样就无需进行多视图数据增强。因此,分散损失可以在现有的生成模型中充当即插即用的正则化器,而无需修改回归损失的实现。
在实践中,引入分散损失只需进行少量调整:
-
指定应用正则化器的中间层;
-
计算该层的分散损失并将其添加到原始扩散损失中。
算法 2 给出了训练伪代码,其中包含算法 1 中定义的分散损失的具体形式。

该团队表示:「我们相信,这种简化可极大地促进我们方法的实际应用,使其能够应用于各种生成模型。」
分散损失的实际表现如何?
表 2 比较了分散损失的不同变体及相应的对比损失。
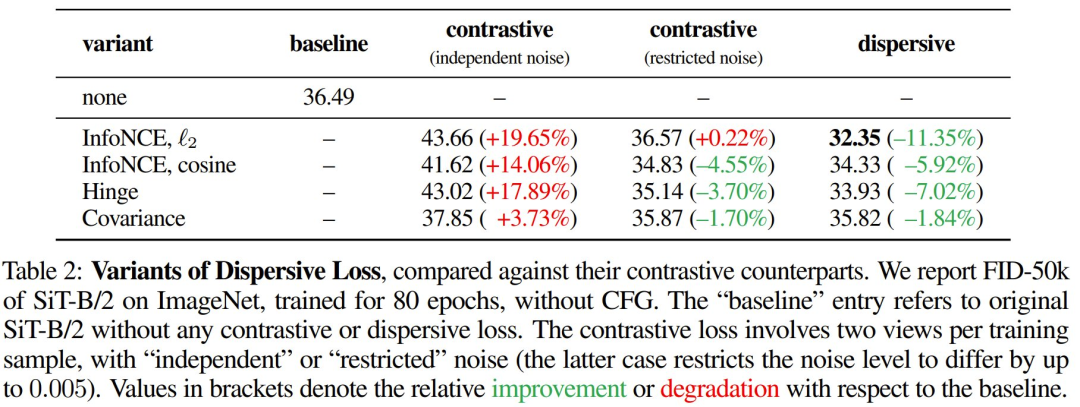
可以看到,在使用独立噪声时,对比损失在所有研究案例中均未能提高生成质量。该团队猜想对齐两个噪声水平差异很大的视图会损害学习效果。
而分散损失的表现总是比相应的对比损失好,而前者还避免了双视图采样带来的复杂性。
而在不同的变体中,采用 ℓ₂ 距离的 InfoNCE 表现最佳。因此,在其它实验中,该团队默认使用基于ℓ₂ 的 InfoNCE。
另外,该团队还研究了不同模块选择以及不同 λ(控制正则化强度)和 τ(InfoNCE 中的温度)值的影响。详见原论文。
另外,不管是在 DiT(Diffusion Transformer)还是 SiT(Scalable Interpolant Transformers)上,分散损失在所有场景下都比基线方法更好。有趣的是,他们还观察到,当基线性能更强时,相对改进甚至绝对改进往往还会更大。
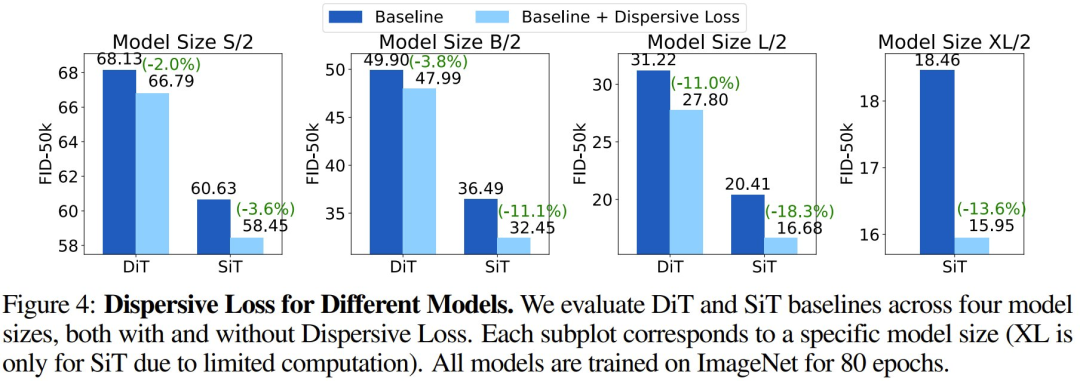
总体而言,这种趋势有力地证明了分散损失的主要作用在于正则化。由于规模更大、性能更强的模型更容易过拟合,因此有效的正则化往往会使它们受益更多。
图 5 展示了 SiT-XL/2 模型生成的一些示例图像。

当然,该团队也将新方法与 REPA 进行了比较。新方法的正则化器直接作用于模型的内部表示,而 REPA 会将其与外部模型的表示对齐。因此,为了公平起见,应同时考虑额外的计算开销和外部信息源,如表 6 所示。

REPA 依赖于一个预训练的 DINOv2 模型,该模型本身是从已在 1.42 亿张精选图像上训练过的 11B 参数主干网络中蒸馏出来的。
相比之下,新提出的方法完全不需要这些:无需预训练、外部数据和额外的模型参数。新方法在将训练扩展到更大的模型和数据集时非常适用,并且该团队预计在这种情况下正则化效果会非常好。
最后,新提出的方法可以直接泛化用于基于一步式扩散的生成模型。
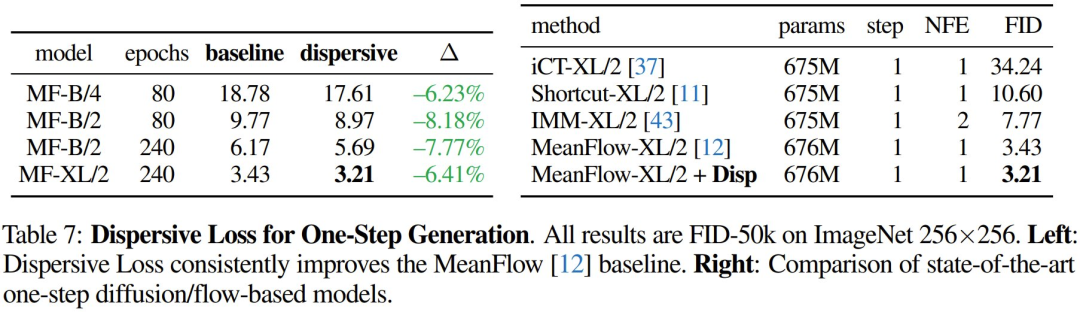
在表 7(左)中,该团队将分散损失应用于最新的 MeanFlow 模型,然后观察到了稳定持续的改进。表 7(右)将这些结果与最新的一步扩散 / 基于流的模型进行了比较,表明新方法可增强 MeanFlow 的性能并达到了新的 SOTA。
©
(文:机器之心)