华为最新AI论文:昇腾910C集群实战DeepSeek-R1,和英伟达比怎么样?
智东西6月18日报道,6月15日,华为联合硅基流动发布论文《在华为CloudMatrix384上提供大语言模型(Serving Large Language Models on Huawei CloudMatrix384)》。据论文报告,在DeepSeek-R1模型的评估中,应用于华为AI超级节点CloudMatrix384的昇腾910C NPU可实现赶超英伟达H800 GPU的计算效率。
▲论文截图
https://arxiv.org/pdf/2506.12708
CloudMatrix384是华为于2025年4月发布的AI超级节点,是其下一代AI数据中心架构CloudMatrix的首次生产级落地。CloudMatrix384集成384颗昇腾910C NPU和192个鲲鹏CPU,通过超高带宽、低延迟的统一总线(UB)网络互连,从而有效解决传统数据中心架构中常见的可扩展性和效率挑战。
基于CloudMatrix384,华为推出了CloudMatrix-Infer服务解决方案。对DeepSeek-R1模型的广泛评估表明,华为CloudMatrix-Infer的计算效率可超过英伟达H800的表现。
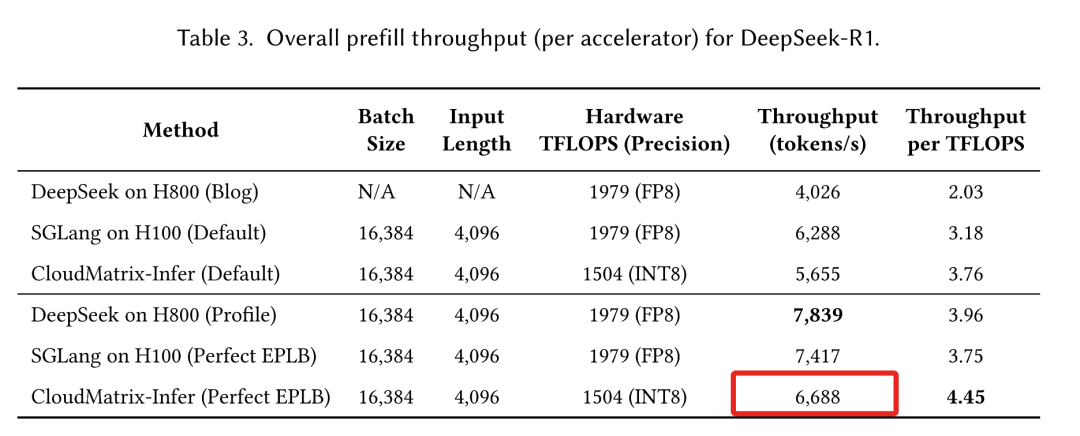
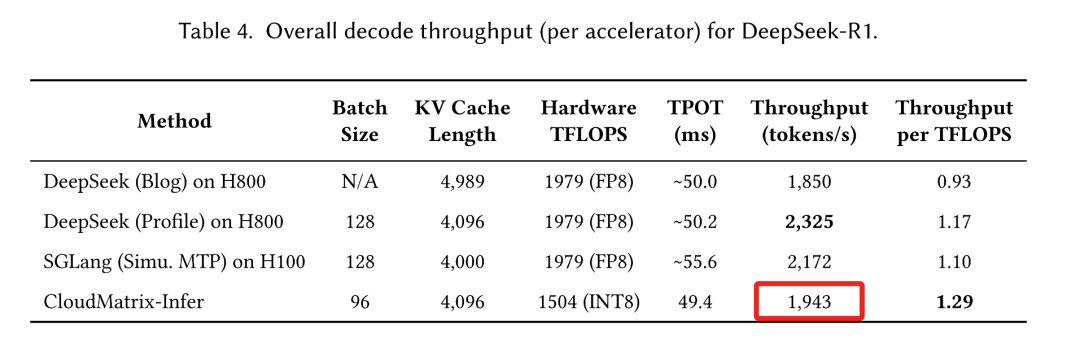
CloudMatrix-Infer在预填充阶段为每颗NPU提供6688tokens/s吞吐,在解码期间为每颗NPU提供1943tokens/s吞吐,同时始终保持每个输出token低于50ms的低延迟。对应的预填充阶段计算效率达4.45 tokens/s/TFLOPS,解码阶段1.29 tokens/s/TFLOPS,这超过了NVIDIA H100上的SGLang和H800上的DeepSeek等领先框架的公布效率。
这样的成绩,也印证了前不久英伟达CEO黄仁勋的判断:虽然(如任正非所说)美国芯片技术比华为领先一代,但人工智能是一个并行问题,如果每台计算机的性能不够强,那就用更多的计算机,华为可以满足中国乃至更多市场的大模型需求。
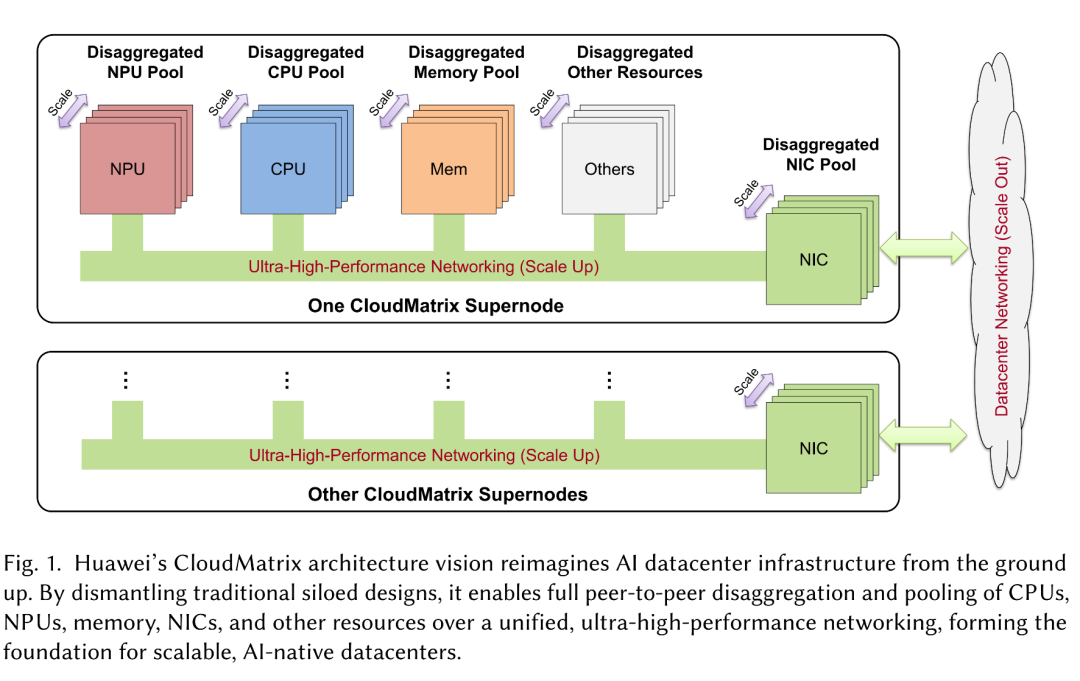
华为的CloudMatrix架构愿景从零开始重新构想AI数据中心基础设施。通过拆除传统的孤立设计,它支持通过统一的超高性能网络实现CPU、NPU、内存、NIC和其他资源的完全点对点分解和池化,从而为可扩展的AI原生数据中心奠定基础。
▲华为CloudMatrix架构愿景概述
当下,传统的AI集群越来越受到计算强度、内存带宽限制、芯片间通信开销和严格的延迟要求的限制。在实际部署中,人们需要处理各种突发工作负载、可变长度输入和不平衡的专家激活,同时满足严格的服务级别目标,从而进一步加剧了这些挑战。
克服这些限制需要从根本上重新架构、共同设计的硬件和软件堆栈。华为推出了下一代AI数据中心架构CloudMatrix为应对这些挑战提供了解法。
CloudMatrix超越传统的以CPU为中心的分层设计。它促进了所有异构系统组件之间的直接、高性能通信,包括NPU、CPU、DR、SDS、NIC和特定于域的加速器,特别是不需CPU中介。
此架构的核心是超高带宽、低延迟的统一总线(UB)网络,它促进了高效的系统范围数据迁移和协调。CloudMatrix基于此互连基板构建,提供TP/EP的可扩展通信、适用于异构工作负载的灵活资源组合、适用于融合工作负载的统一基础设施、通过分解内存池实现内存类存储四项基本功能,共同定义了AI原生基础设施的新范式。
▲CloudMatrix384超级节点的点对点硬件架构
CloudMatrix384将384颗昇腾910C NPU、192个鲲鹏CPU和其他硬件组件集成到一个统一的超级节点中,通过超高带宽、低延迟的统一总线(UB)网络互连,从而实现接近节点内水平的节点间通信性能。
与传统的分层设计不同,这种架构支持通过UB进行直接的多对多通信,从而允许计算、内存和网络资源动态池化、统一访问和独立扩展。这些架构特性特别有利于通信密集型作,例如大规模MoE专家并行和分布式键值(KV)缓存访问,使CloudMatrix384成为下一代大语言模型服务的可扩展和高性能基础。
为了支持不同的流量模式并保持与传统数据中心网络的兼容性,CloudMatrix384整合了三个不同但互补的网络平面:UB平面、RDMA平面和VPC(虚拟私有云)平面。
但CloudMatrix的长期愿景是将RDMA和VPC平面融合到一个统一的平面中。当前的CloudMatrix384将它们分开,是为了确保与传统数据中心基础设施的向后兼容性。
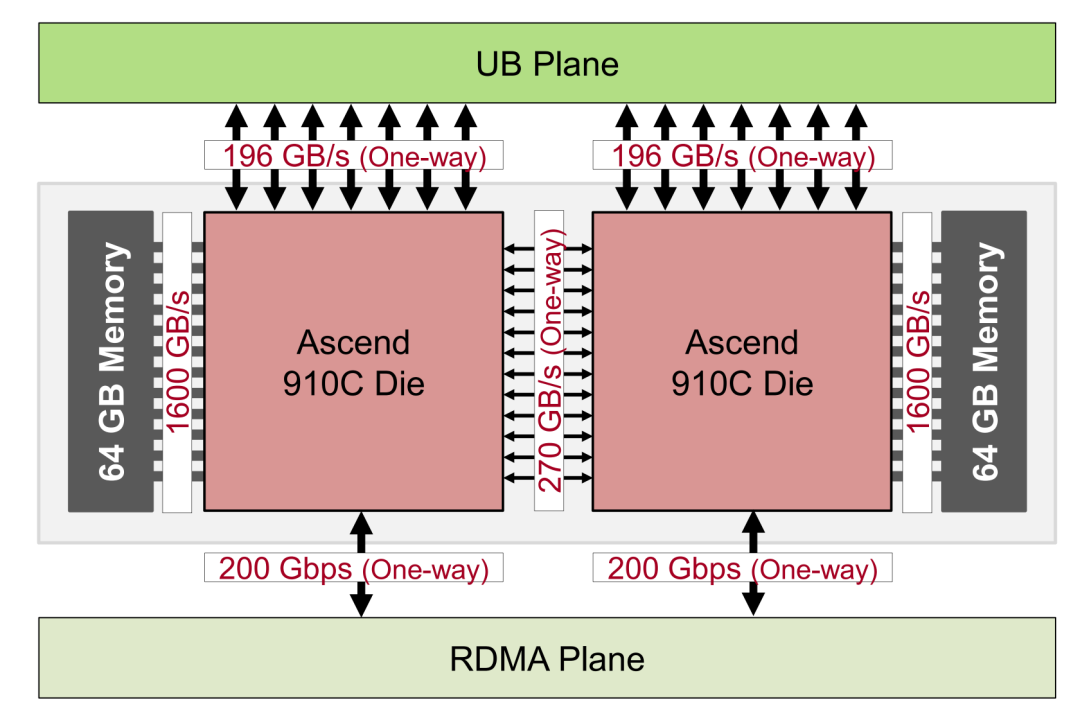
在硬件组件方面,CloudMatrix384的核心是海思昇腾910C NPU。作为昇腾910B的后续产品,昇腾910C是一种双die封装:两个相同的计算die被共同封装,共享8个封装上的内存堆栈,并通过高带宽交叉die结构连接。
▲昇腾910C芯片的逻辑概述突出双die架构
计算方面,每颗芯片可维持大约376TFLOPS的密集BF16/FP16吞吐量,每个封装的总吞吐量为752TFLOPS;存储方面,昇腾910C封装集成了8个内存堆栈(每个堆栈16GB),提供总共128GB的封装内存(每个芯片64GB)。网络接口方面,每颗昇腾910C裸片与UB平面和DMA平面两个不同的网络平面接口。
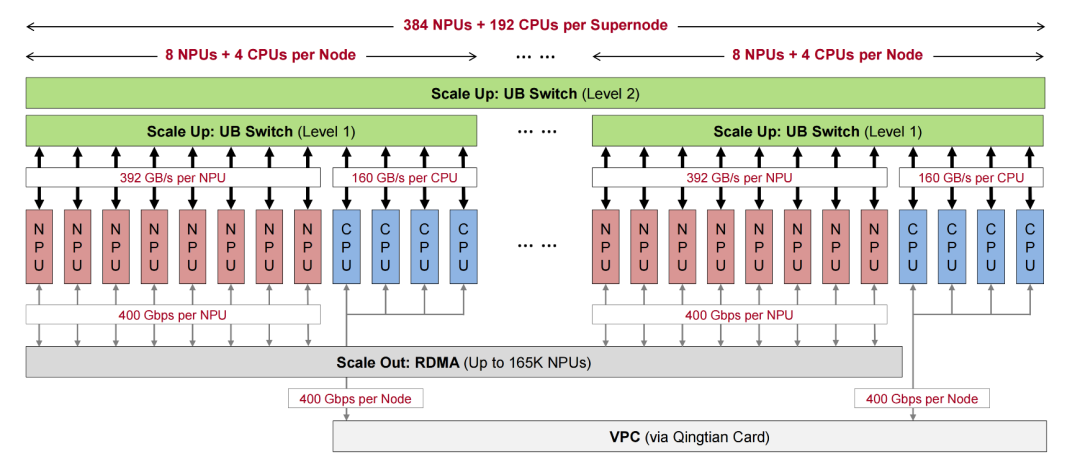
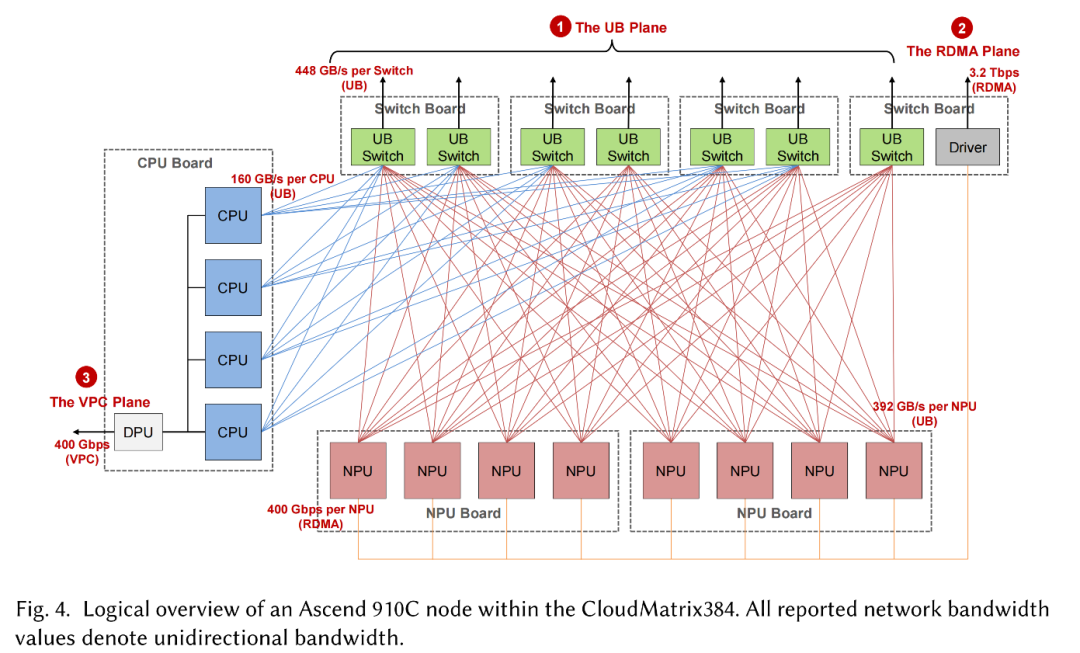
聚焦计算节点,CloudMatrix384中的每个计算节点都集成了8个昇腾910C NPU、4个鲲鹏CPU和7个UB交换芯片。
如下图所示,12个处理器(8个NPU和4个CPU)通过UB链路连接到这些板载交换机,在节点内创建一个单层UB平面。每个NPU配置高达392GB/s的单向UB带宽,而每个鲲鹏CPU插槽提供大约160GB/s的单向UB带宽。板载单个UB交换机芯片为超级节点结构中的下一个交换层提供448GB/s的上行链路容量。
▲CloudMatrix384中昇腾910C节点的逻辑概述
只有NPU参与辅助RDMA平面。每个NPU设备为横向扩展RDMA流量提供额外的400Gbps单向链路,每个节点总共产生3.2Tbps的RDMA带宽。
在CPU复合体中,四个鲲鹏CPU插槽通过全网状NUMA拓扑互连,从而在所有CPU连接的DRAM上实现统一的内存访问。其中一个CPU托管节点的擎天卡,这是一个专用的数据处理单元(DPU),不仅集成了高速网络接口,还执行基本的节点级资源管理功能。此擎天卡用作节点的主要南北向出口点,与第三个不同的网络平面(数据中心的VPC平面)接口。
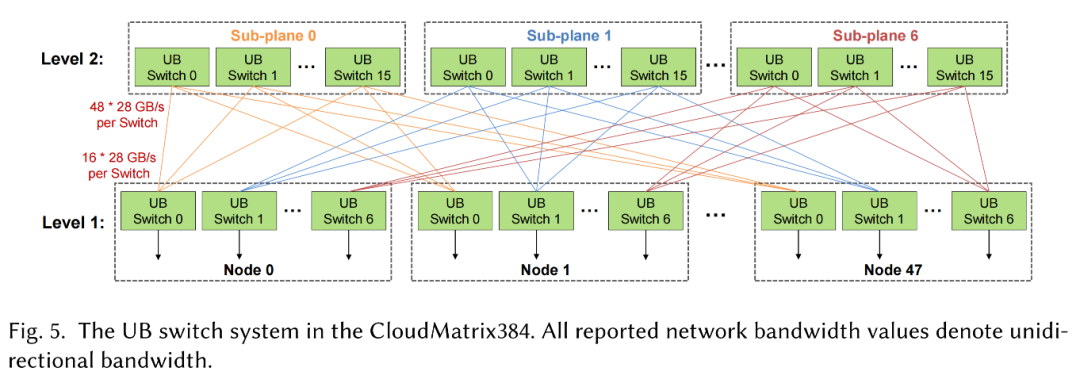
再来看UB交换机系统,CloudMatrix384超级节点跨越16个机架:12个计算机机架,共同托管48个昇腾910C节点(共384个NPU)和4个通信机架。这些通信机架容纳了第二层(L2)UB交换机,用于互连超级节点内的所有节点。
下图说明了板载第一层(L1)UB交换机和机架级L2 UB交换机之间的拓扑结构。该网络设计为无阻塞网络,这意味着在L2交换层没有带宽超额订阅。L2交换机分为7个独立的子平面。每个子平面包含16个L2 UB交换机芯片,每个L2交换机芯片提供48×28GB/s端口。
▲CloudMatrix384中的UB交换机系统
在每个节点内部,7个板载L1 UB交换机芯片一对一映射到这7个L2子平面上。每个L1交换机芯片通过16个链路扇出(一个链路连接到其相应子平面中的每个L2交换机芯片)。此配置可确保节点到L2交换矩阵的聚合上行链路带宽与其内部UB容量精确匹配,从而保持整个超级节点的无阻塞特性。
在软件堆栈方面,华为为昇腾NPU开发了一个全面的软件生态系统,称为神经网络计算架构(CANN)。CANN作为中间软件层,实现了高级AI框架(如PyTorch和TensorFlow)与昇腾NPU的底层硬件接口之间的高效集成。通过将这些框架生成的抽象计算图转换为优化的硬件可执行指令,CANN简化了开发人员与昇腾硬件的交互,促进了软硬件协同设计,并旨在最大限度地提高昇腾架构上的应用程序性能。
CANN软件堆栈由三个主要层组成:驱动程序、运行时和库,这种架构类似于NVIDIA的CUDA生态系统。
▲华为昇腾NPU的CANN软件栈
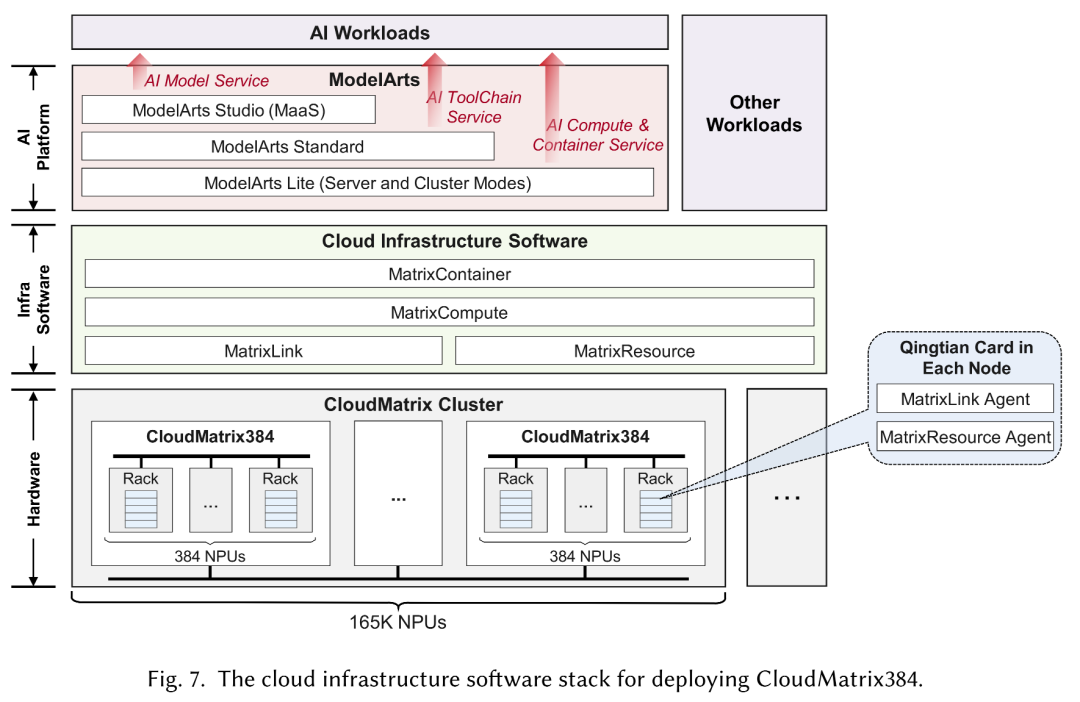
为了实现云环境中的CloudMatrix384部署,华为云提供了一套复杂的基础设施软件,包括MatrixResource、MatrixLink、MatrixCompute和MatrixContainer,旨在通过标准的云API抽象出硬件复杂性并实现无缝的资源编排。
▲用于部署CloudMatrix384的云基础设施软件堆栈
总之,CloudMatrix384专为提高互连带宽和通信效率而构建,这是扩展大型训练和推理工作负载所必需的核心功能。DeepSeek-R1等大规模MoE模型的出现验证了这一点。
论文展示了DeepSeek模型的适用性分析,主要关注MoE通信、内存可扩展性、高速缓存重用和量化支持四个关键维度。
分析可得,CloudMatrix384的架构,包括其大规模NPU计算、广泛的内存容量、高带宽UB互连和基于DRAM池的缓存,与DeepSeek这样的大语言模型服务的需求紧密结合。这些协同作用为后续部分中介绍的优化推理架构提供了坚实的基础。
为了充分利用CloudMatrix384的能力,华为提出了CloudMatrix-Infer,这是一个全面的大语言模型服务解决方案,为部署DeepSeek-R1等大规模MoE模型建立了实践参考。
▲跨AI软件堆栈的多个层提出的优化技术
CloudMatrix-Infer包含三项核心创新:
首先,华为设计了一个点对点服务架构,将预填充、解码和缓存分解到独立可扩展的资源池中。与现有的以KV cacheCentric架构不同,这种设计支持通过UB网络对缓存数据进行高带宽、统一访问,从而减少数据局部性限制,简化任务调度,并提高缓存效率。
其次,华为设计了一个大规模的专家并行(LEP)策略,利用UB网络实现高效的token调度和专家输出组合。该策略支持非常大的EP度数,例如EP320,使每个NPU芯片能够只托管一名专家,从而实现低解码延迟。
最后,华为提出了一套为CloudMatrix384量身定制的硬件感知优化,包括高度优化的算子、基于微批处理的流水线和INT8量化,以提高执行效率和资源利用率。
对DeepSeek-R1模型的广泛评估表明,CloudMatrix-Infer实现了卓越的吞吐量。
其在预填充阶段为每个NPU提供6688tokens/s,在解码期间为每个NPU提供1943tokens/s,同时始终保持每个输出token低于50ms的低延迟。这些结果对应的计算效率为:预填充阶段计算效率达4.45 tokens/s/TFLOPS,解码阶段1.29 tokens/s/TFLOPS,这两者都超过了NVIDIA H100上的SGLang和H800上的DeepSeek等领先框架的公布效率。
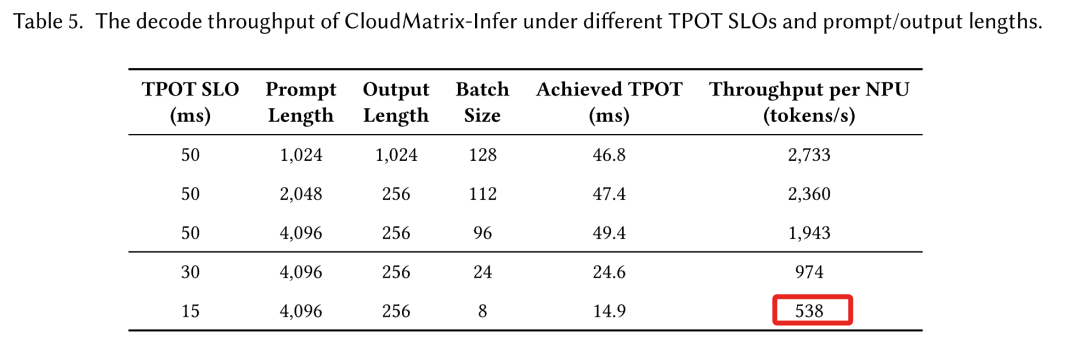
此外,CloudMatrix-Infer有效地管理了吞吐量-延迟的权衡,即使在更严格的低于15ms的TPOT约束下,也能够维持538tokens/s的吞吐量。
INT8量化策略在各种基准测试中进一步保持了与DeepSeek的官方API相当的准确性。
在参数规模增加、混合专家(MoE)架构采用和上下文长度扩展的推动下,大语言模型的快速发展对AI基础设施提出了前所未有的要求。
作为一个高效、可扩展且性能优化的平台,华为CloudMatrix可用于部署大规模AI工作负载。CloudMatrix384的一个根本性特征是其点对点、完全互连、超高带宽网络,通过UB协议连接所有NPU和CPU,为未来的AI数据中心基础设施树立了标杆。
展望未来,CloudMatrix384有几个令人兴奋的增强方向。未来的工作包括集成和统一VPC和RDMA网络平面以实现更简化的互连、扩展到更大的超级节点配置,以及追求更深入的CPU资源分解和池化。
此外,更精细的组件级分解和自适应部署策略为在AI数据中心基础设施中实现更高的灵活性、效率和可扩展性提供了有前途的途径。
(文:智东西)