



论文标题:
TIIF-Bench: How Does Your T2I Model Follow Your Instructions?
作者单位:
北京大学、清华大学、中山大学、香港理工大学、OPPO Y-Lab
项目主页 & Leaderboard:
https://a113n-w3i.github.io/TIIF_Bench/
Arxiv 链接:
https://www.arxiv.org/abs/2506.02161
指导教师:
港理工 Chair Professor 张磊教授,IEEE Fellow,TIP、TPAMI 高级主编,Google scholar 引用量 11w+,总引用亚洲前五、low-level 重建生成领域引用亚洲第一。

背景
随着 GPT-4o 在图像生成任务上的横空出世,以及越来越多采用自回归架构(auto-regressive architecture)的文本到图像(T2I)模型迅速发展,当前一代的生成模型在理解与执行用户复杂指令(prompts)方面,已经实现了飞跃式突破。
如今的 T2I 模型不仅能识别多个属性(如颜色、材质、风格等),还能处理带有逻辑推理结构甚至复杂修辞的超长自然语言指令。

A square image containing a 4 row by 4 column grid containing 16 objects on a white background. Go from left to right, top to bottom. Here’s the list:
1. a blue star
2. red triangle
3. green square
4. pink circle
5. orange hourglass
6. purple infinity sign
7. black and white polka dot bowtie
8. tiedye “42”
9. an orange cat wearing a black baseball cap
10. a map with a treasure chest
11. a pair of googly eyes
12. a thumbs up emoji
13. a pair of scissors
14. a blue and white giraffe
15. the word “OpenAI” written in cursive
16. a rainbow-colored lightning bolt
▲ 例如:GPT-4o 生图的官方例子,prompt 涉及数百个单词,以及非常复杂的属性与位置关系组合
然而问题也随之暴露:现有主流的 T2I Benchmark 明显滞后,无法有效衡量这些强模型的真实能力。
我们总结出当前 T2I 评测基准面临的四大问题:
Prompt 设计简化、结构单一:许多 benchmark 中的大多数 prompt 长度极短,而且大多为模板化句式(如 “a photo of a [object] with [attribute]”),难以反映真实使用场景中复杂需求的处理能力。
语义多样性严重不足:以 GenAI Bench 为例,其 prompt 集中度极高,只有不到 30% 的 prompts 是语义独立的(semantic unique),导致模型评测分数逐渐“内卷收敛”,难以区分强模型和弱模型的能力差异。
缺乏真实场景长指令:现实中,用户往往会输入多属性、带有条件关系和上下文逻辑的自然语言描述。而现有 benchmark 极少覆盖这类“设计师风格”或“专业用户需求”指令,导致模型训练和评测脱节。
评测方法粗糙且与人类直觉不符:目前大多数 benchmark 仍依赖 CLIP 相似度(CLIPScore 或类似变体)进行自动评测。这类评测手段仅能判断“是否与文本概念大致对齐”,却无法评估图像中每个细节是否精准反映用户意图(例如无法区分 “a boy under a bee” 和 “a bee under a boy”),也无法体现人类真实偏好。

现有Bench的不足之处
Prompt 设计的不足:简化、结构单一,语义多样性与文法多样性不足,且缺乏真实场景长指令:
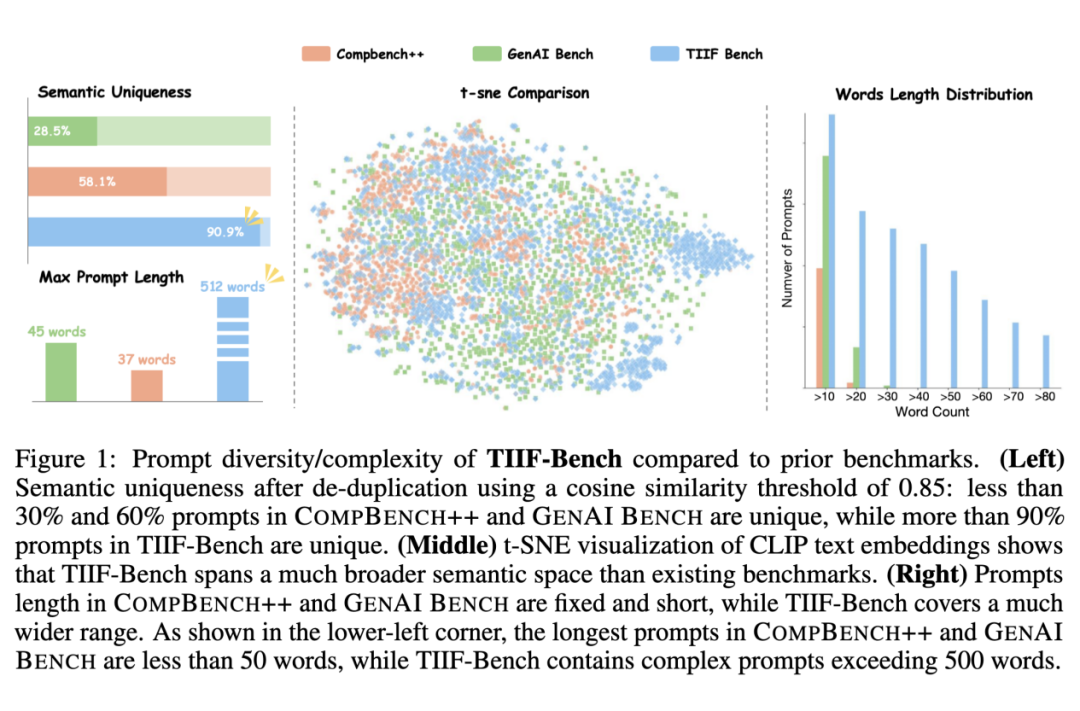
长度偏短且固定(右图):常见 bench 中的绝大多数 prompt 都不大于 30 个单词,这和现实场景中 T2I 模型所面对的 prompt 长度 gap 很大;
缺乏真实使用场景下的长指令(左下图):常见 Bench 的最长 prompt 也是较为简单的句子,TIIF-Bench 包含了许多从 AIGC 论坛上手工收集的复杂、真实用户 prompt;
语义重复性高(左上图):我们使用 CLIP 提取了不同 Bench 中所有 prompts 的文本语义特征并计算了 consine 相似度,以 0.85 为 threshold,发现 GenAI Bench 中只有不到 30% 的 prompt 是 semantic unique 的,Compbench++ 中只有不到 60%,而 TIIF-Bench 中 semantic unique prompts 大于 90%;
文法复杂度低(中间图):我们将不同 Bench 的所有 prompts 的 CLIP 文本语义特征进行了 t-SNE 降维,TIIF-Bench 的 range 范围最大;
然而实验表明:即使核心语义相同,不同长度的 prompt 对 T2I model 有很大影响:

现有的 bench 完全缺乏这一维度的考量!
评测方法的不足:粗糙且与人类直觉不符
目前大多数 benchmark 仍依赖 CLIP 相似度(CLIPScore 或类似变体)和其它一些专家模型进行自动评测:

然而 CLIP 无法评估图像中每个细节是否精准反映用户意图(例如无法区分 “a boy under a bee” 和 “a bee under a boy”),也无法体现人类真实偏好 ⚠️。UNIDet 等开集检测模型则无法对现代 T2I model 生成的复杂图像进行有效检测。

TIIF-Bench 的构建
我们设计了一个多阶段的 prompt 生成流程:
概念池构建(Concept Pool Construction)
-
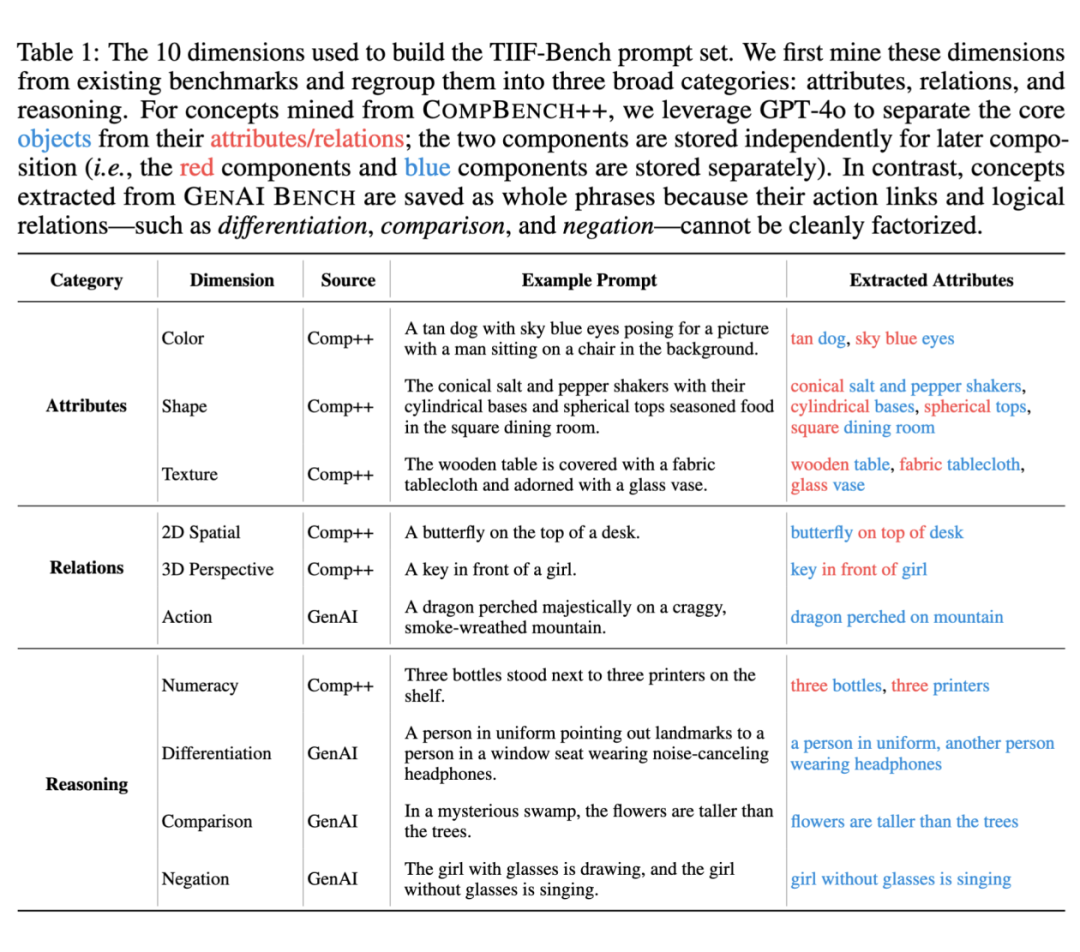
首先对现有 benchmark 的 prompt 进行语义分组,借助 GPT-4o 自动提取核心的“物体–属性/关系”结构。
-
最终我们构建了 10 个概念维度,并将其划分为三大类:属性类(Attribute)、关系类(Relation)和推理类(Reasoning),详见:
属性组合(Attribute Composition)
-
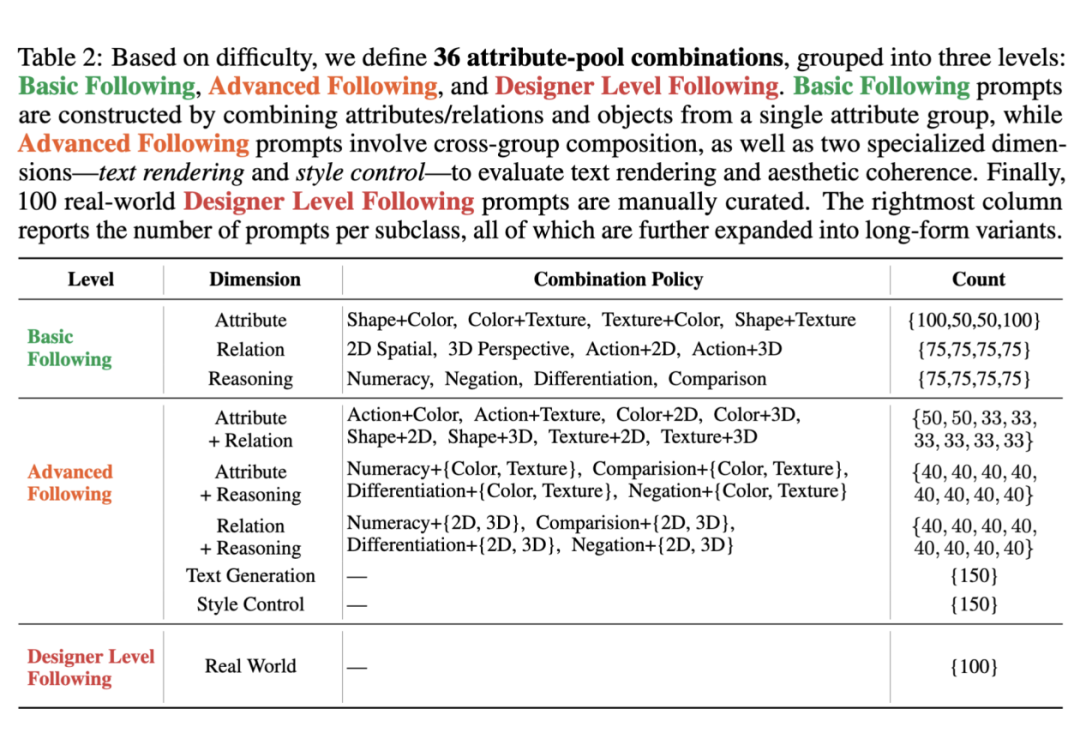
从上述概念池中采样属性组合,使用 GPT-4o 自动生成自然语言指令。我们设计了 36 个不同的组合模式,并为每种组合搭配了专属的 meta-prompt 引导生成。
-
组合策略分为:
-
Basic Following:只涉及同一类属性的组合;
-
Advanced Following:跨类别组合,内容更复杂;
新评测维度
-
Text Rendering:衡量 T2I 模型生成复杂非自然纹理的能力!我们专门设计了新指标 GNED 来对其进行评测,难度归类为 Advanced Following;
-
Style Control:衡量 T2I 模型整体的内容理解与控制能力!我们从手动 AIGC 社区挑选了 10 个最常用的风格,难度归类为 Advanced Following;
-
Real World:衡量 T2I 模型的综合能力!我们手动从 AIGC社 区筛选了 100 个受欢迎、内容复杂、有趣的设计师级别 prompt,难度单独归类为 Designer Level Following;
长度扩展(Length Augmentation)
-
为每条 prompt 自动生成一个长文本版本,通过 GPT-4o 进行语言丰富化和风格润色,测试模型对不同语言复杂度指令的适应能力。

TIIF-Bench的评测流程
我们提出了一种基于属性级问答匹配(Attribute-Specific QA Matching)的评测框架:
核心步骤:
1. 概念抽取:
从生成指令中提取出 N 个核心语义概念(如物体属性、物体间关系、逻辑关系等);
2. 问题生成:
由 GPT-4o 为每个概念自动生成一个二选一问句(Yes/No Question),如“这张图中有红色汽车吗?”、“人是在汽车的左边吗?”;
3. 答案匹配:
将生成图像和所有问题一起输入到多模态大模型(如 GPT-4o 或 QwenVL),获取预测答案,并与标准答案进行比较;
4. 评分计算:
通过平均匹配准确率得出最终分数,避免了使用全 prompt 的语言偏见与幻觉。
特殊维度评测:
• Designer-Level Prompt:每条指令搭配人工制定的专属问句,确保高可靠性。
• Text Rendering:使用 OCR Recall 和全新提出的指标 GNED(Global Normalized Edit Distance):
-
用于衡量图中文字与目标文本在字符层面的匹配度;
-
同时惩罚遗漏、冗余、错误字形等问题;
-
相比 PNED 更稳定、鲁棒,适用于任意文本长度与格式。


一些有趣的 insights
我们将模型分为三类进行分析:
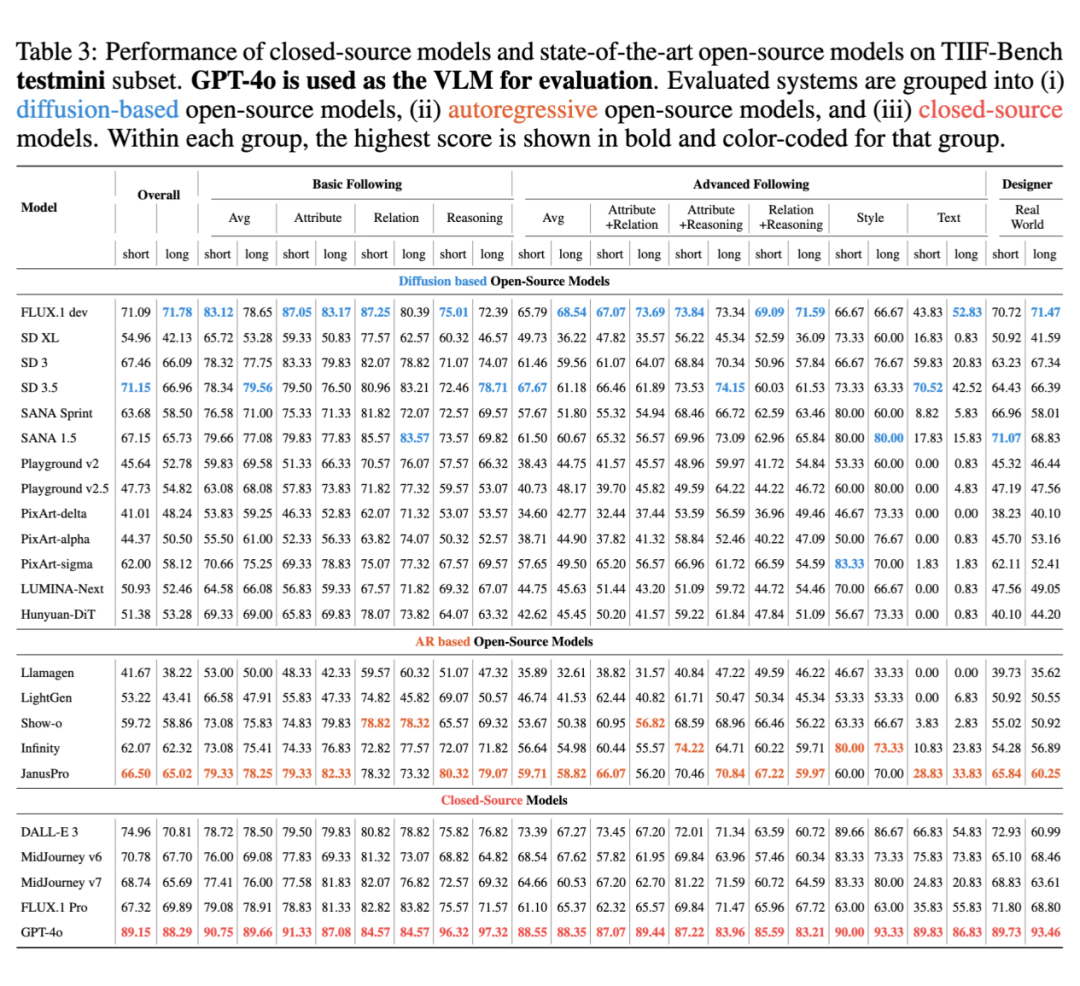
Diffusion架构的开源模型
代表模型包括:SD 系列、FLUX.1 Dev、SANA 系列、PixArt 系列、Playground 系列等。
-
整体表现:SD 3.5 在短指令上得分最高;而 FLUX.1 Dev 在长指令场景中表现最强,得益于其 MMDiT 架构和更大模型规模。
-
文字生成(Text Rendering):仅有 FLUX.1 Dev、SANA 系列、SD 系列部分版本支持文本生成。其中 FLUX.1 Dev 在短长指令下均表现稳定。
-
风格控制(Style Control):部分模型(如 Playground)在长 prompt 下风格生成质量反而更好,因为长指令提供了更多语义上下文;而 SD 3.5、PixArt-Sigma 等模型更依赖短标签提示,长 prompt 会稀释风格信号。
-
设计师级指令:这类 prompts 是最具挑战性的维度,模型在该维度的排名通常也代表其综合实力。
-
对 prompt 长度的鲁棒性:如 FLUX.1 Dev、SD 3.5、PixArt-Sigma 等表现稳定;而弱模型(如 SDXL、PixArt-Alpha)在长指令下明显退化。T2I 模型的指令理解能力与其综合生成能力呈正相关!
自回归(AR)架构的开源模型
代表模型包括:Janus-Pro、Infinity、Show-o 等
-
整体表现:Janus-Pro 表现最佳,得益于其融合生成与理解的训练策略。
-
文字生成能力较弱,但 Janus-Pro 和 Show-o 可生成基本文字。
-
风格控制能力强,对复杂风格语义理解更到位。
-
视觉保真度略逊一筹,但在复杂逻辑理解、长 prompt 指令跟随方面表现亮眼。

▲ 自回归 T2I 模型虽然在生成图像画质方面表现一般,但是在理解指令方面表现优异
闭源模型
包括:GPT-4o、DALL·E 3、MidJourney V6/V7、Flux.1 Pro 等
-
GPT-4o 在所有维度遥遥领先,不仅图像质量极高,指令理解也最强,是唯一在复杂逻辑推理(如否定、比较等)任务上始终保持稳定的模型。
-
文字渲染上,GPT-4o 成功率远高于其他模型。
-
风格控制与设计师指令执行能力方面也显著优于所有闭源/开源对手。
-
值得注意的是,Flux.1 Pro 的表现竟不如开源的 Flux.1 Dev,尤其是在长 prompt 情境下,闭源不一定优于开源!
与其他Benchmark对比
我们选取了四个开源模型(SD 3.5、SANA 1.5、PixArt-Sigma、Janus-Pro)和四个闭源模型(GPT-4o、DALL·E 3、MidJourney V6、Flux.1 Pro),在三个 Benchmark 上进行横向评测:TIIF-Bench、CompBench++、GenAI Bench。
对比发现
-
GenAI Bench 和 CompBench++ 中存在评分收敛、模型难以区分的问题,例如多个模型得分完全一样。
-
CompBench++ 中,专家模型打分与 GPT 打分存在显著偏差。
-
TIIF-Bench 在评测维度细致度、模型区分能力方面更强,能够稳定给出符合模型能力的排序。
(文:PaperWeekly)