

LinGn团队 投稿
量子位 | 公众号 QbitAI
视频生成模型太贵太慢怎么办?
普林斯顿大学和Meta联合推出的新框架LinGen,以MATE线性复杂度块取代传统自注意力,将视频生成从像素数的平方复杂度压到线性复杂度,使单张GPU就能在分钟级长度下生成高质量视频,大幅提高了模型的可扩展性和生成效率。

实验结果表明,LinGen在视频质量上优于DiT(胜率达75.6%),并且最高可减少15×(11.5×)FLOPs(延迟)。此外,自动指标和人工评估均显示,LinGen-4B在视频质量上与最先进模型相当(分别以50.5%、52.1%、49.1%的胜率优于Gen-3、Luma Labs和Kling)。

方法:线性复杂度的MATE模块
LinGen维持Diffusion Transformer(DiT)中的其他结构不变,而将其计算瓶颈——平方复杂度的自注意力模块替换为线性复杂度的MATE模块,它由MA分支和TE分支组成。
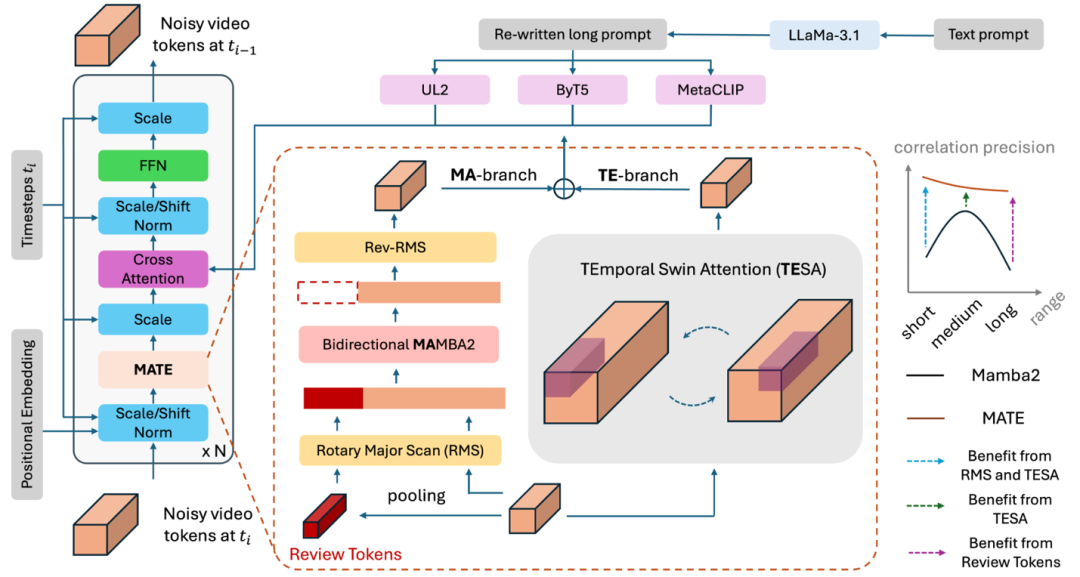
其中,MA分支包含一个双向的Mamba2模块。
Mamba2作为State Space Model(SSM)的变体,善于处理超长的token序列,同时又对硬件非常友好,可以使用attention的各种硬件加速核,如xformers,FlashAttention等。但是Mamba系列模型在语言任务上的优秀表现难以直接迁移到大型视觉任务上,生成的高分辨率视频往往一致性很差、质量不高。
一些特殊的scan方法尝试解决这一问题,如Zigzag scan,Hilbert scan,但它们都要求对序列做复杂的顺序变换,而这个操作对硬件极其不友好。在处理高分辨率、长视频时,会带来显著的额外延迟。
针对于此,LinGen提出Rotary Major Scan(RMS),相邻层中四种scan方式交替切换。
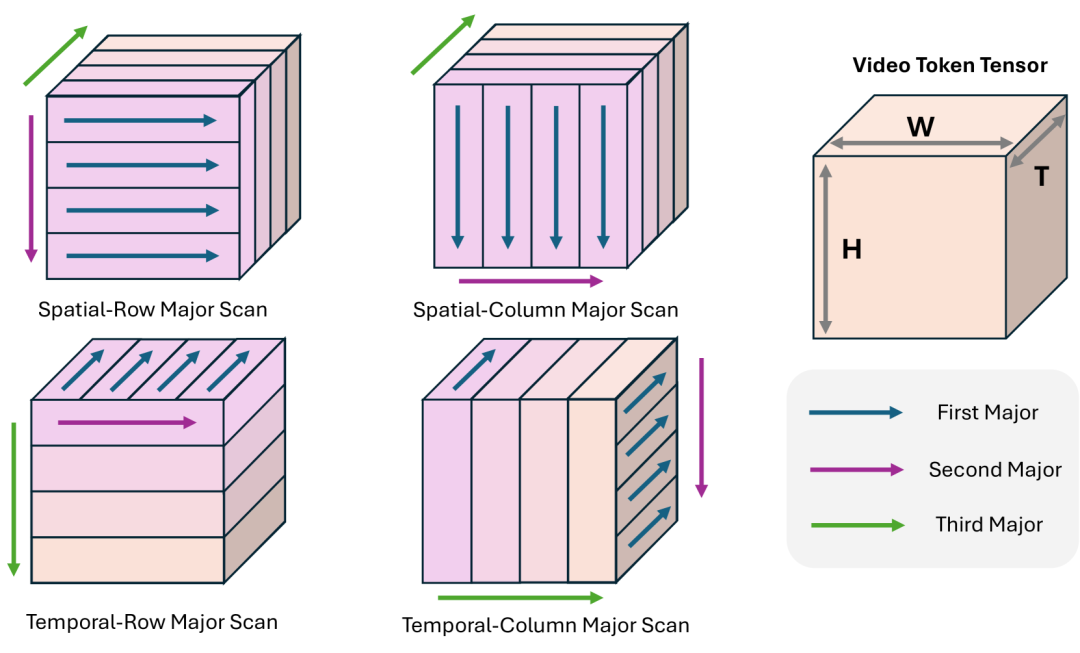
以上图的方式为例,W,H和T分别在展开时有第一、第二和第三优先级,通过交换展开的优先级,就可以实现不同的scan方式。
相比于已有方法,该方法最大的好处是对硬件非常友好、可以通过简单的tensor reshaping实现,因此也几乎没有额外开销,同时还把scan后原相邻token的平均距离降到了和已有特殊scan方式相同的水平。
然而,所有这些特殊的scan方式仍然不足以完全解决Mamba的临近信息丢失问题,因为在模型的任意一层中,只会有一种scan方式被应用,如果不考虑跨层交流,大量临近信息在单层中依旧有损失。
针对于此,LinGen在TE分支中应用了TEmporal Swin Attention(TESA):它是一种特殊的3D window attention,窗口范围在不同层中会滑动,每一个窗口都很小,并且窗口大小不随视频分辨率和长度(即3D tensor的大小)的变化而变化。
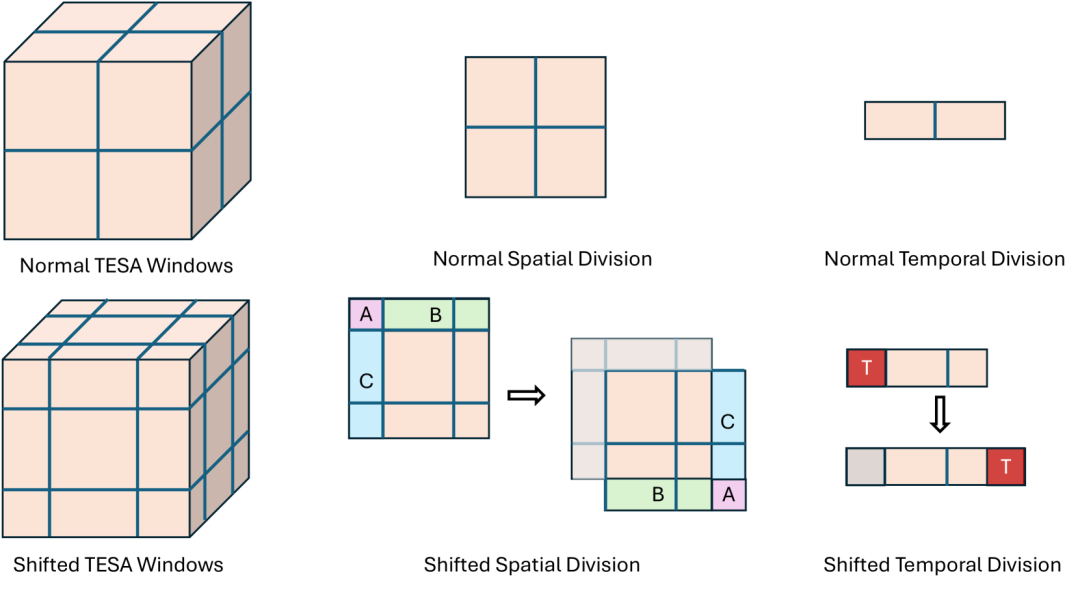
这是因为TESA仅用来处理最临近的信息,这一固定的窗口大小也使得TESA实现了相对3D tensor中token数的线性复杂度。
作为额外的补充,LinGen还在MA分支中引入了review tokens。它被用以增强视频中极长程的一致性,例如在60秒视频的结尾复现视频前几秒消失的人。它把待处理video tensor的概览提前写入Mamba的hidden state memory中,为后续的视频处理提供帮助。
评估:远超基线,对标SOTA
从人类评测和模型自动评测两个角度将LinGen与已有的先进视频生成模型、以及DiT baseline进行比较。
无论是人类评测的结果,还是在VBench上的自动评测的结果,都显示LinGen与先进的商业模型Kling、Runway Gen-3生成的视频质量接近,并且远胜于OpenSora v1.2。
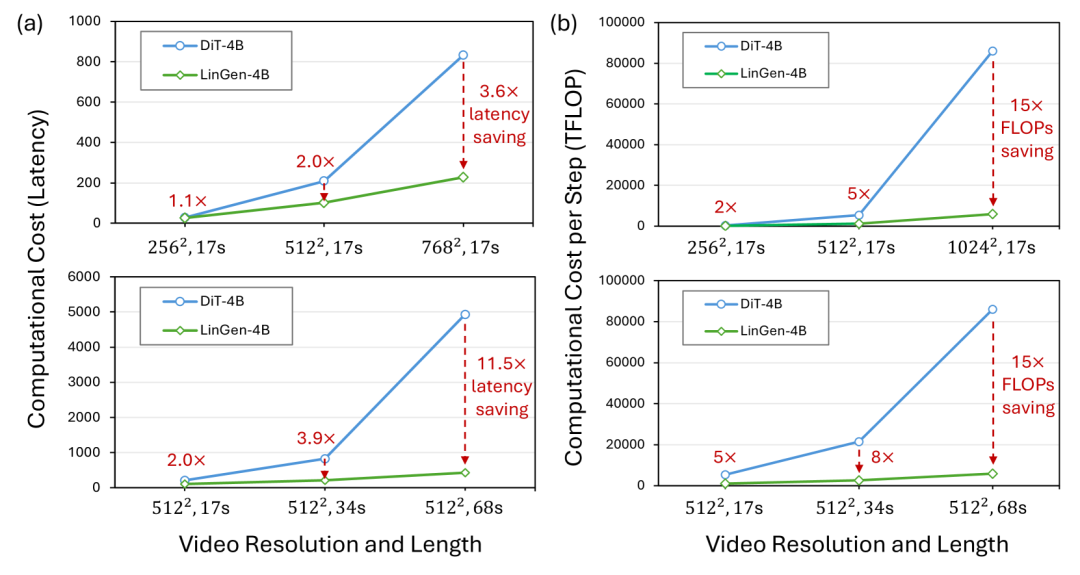
可以看到,在FLOPs方面,当生成17秒、34秒和68秒长度的512p视频时,LinGen-4B相对于DiT-4B分别实现了5×、8×和15×的加速;
在延迟方面,当在单个H100上生成512p和768p的17秒视频时,LinGen-4B相对于DiT-4B分别实现了2.0×和3.6×的加速;
当生成17秒、34秒和68秒长度的512p视频时,LinGen-4B相对于DiT-4B分别实现了2.0×、3.9×和11.5×的延迟加速。
这说明LinGen具有线性复杂度,可以在单卡上实现分钟级视频生成,速度远快于DiT。与相同大小的DiT相比,LinGen可实现推理速度11倍以上的提升。
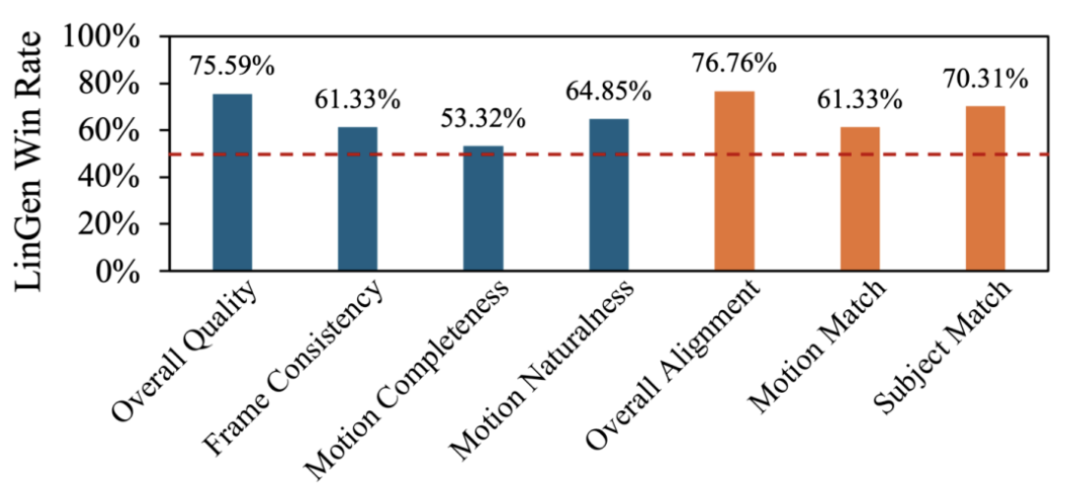
另外,LinGen和相同大小、在相同数据集上以相同training recipe训练的DiT baseline相比,在视频质量和文字-视频一致性上取得全面领先。相比起DiT,LinGen可以更快地适应更长的token序列。
通常认为自注意力模块的线性替代是对完整自注意力的近似,虽然在速度上有显著优势,但在模型性能上往往略逊一筹,而LinGen打破了这个惯有的看法。
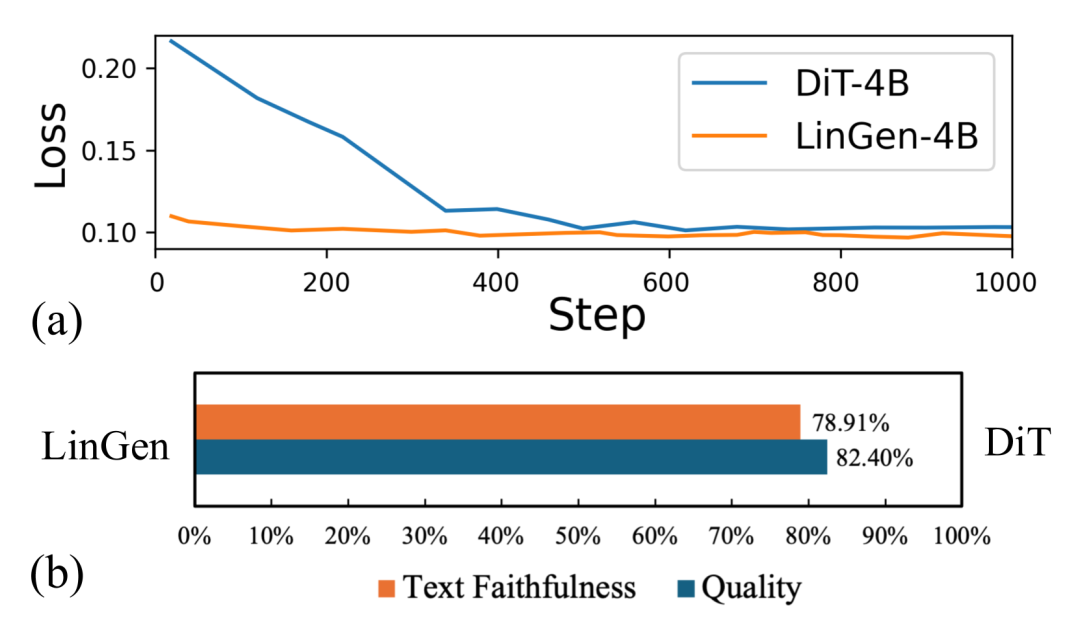
在整个预训练过程中,模型从低分辨率图像生成开始,学习低分辨率视频生成,再不断增加所生成视频的分辨率和长度,所处理的token数增长了上千倍。
而在从少token数的任务迁移到多token数的任务时,LinGen的适应性远强于DiT(a图中是从256×256分辨率视频生成迁移到512×512分辨率视频生成任务时的loss curve),这可能是受益于Mamba对于长序列的高适应性,这一特征已经在语言任务上被观察到。
为了进一步验证这里推理,选取这一预训练阶段的早期checkpoint进行比较,发现LinGen比DiT的win rate优势变得更加显著。这暗示了虽然LinGen在任务迁移的早期能大幅领先DiT,但是这种优势随着预训练的进行,在不断减小。
尽管如此,在训练资源有限的情况下,LinGen在预训练的极长一段时间内仍旧能对DiT保持优势。
项目主页:https://lineargen.github.io/
论文链接:https://arxiv.org/abs/2412.09856
项目代码:https://github.com/jha-lab/LinGen
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)