



豆包升级实时音视频体验
去年,豆包的实时语音通话功能很受好评,特工们也经常使用,用来练习英语口语、或者当作树洞闲聊吐槽。而就在最近,豆包又更新了实时视频通话功能,这下不仅可以和豆包打电话,还可以和豆包打视频。
有了实时音视频功能,用户就像真的有一个赛博 AI 好朋友一样,有什么需要解决的问题、或者想要分享的心情,都可以像与真人打视频一样联系豆包。
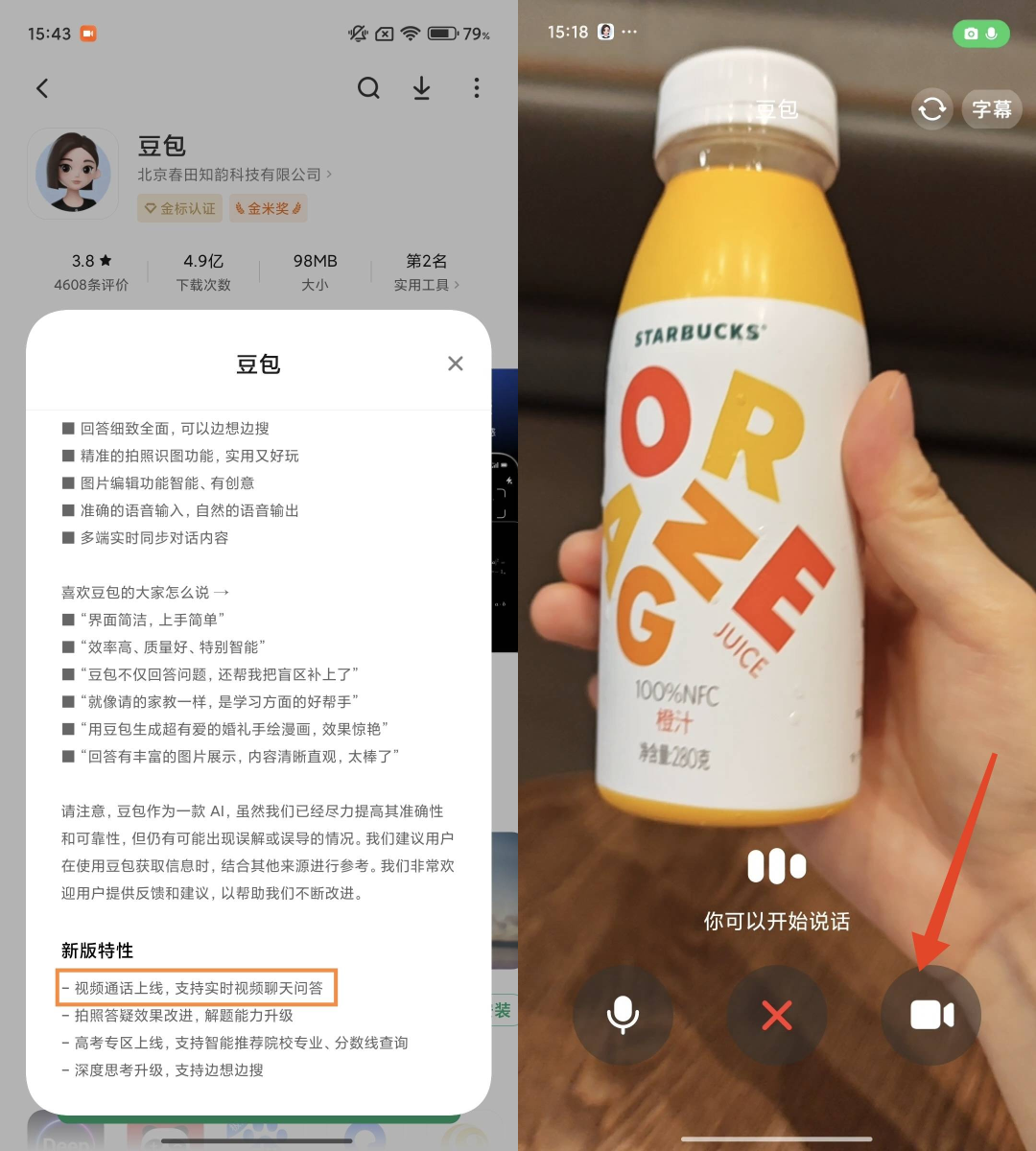
比如买了一瓶橙汁,想要问问橙汁营养成分和 NFC 工艺的解释,对储存时间的建议。打开豆包视频通话功能后,只需要拿着这瓶橙汁放在镜头前,不断提出问题,豆包就能迅速、准确地响应回答。
在视频能力方面,豆包能快速识别整体画面和部分细节,即便是在圆柱体曲面上印刷模糊或肉眼看起来很小的字,豆包都能又快又准地理解;
在音频能力方面,每个问题抛出后,体感几乎在 2 秒内就能得到流畅、完整、自然的语音回复,不论是音色还是语音语调,都很有真人感。如果豆包在说话过程中被人打断,它也会自然地暂停,优先听用户新的表达,然后再顺畅地回复新内容。
此外,即便是使用时在有嘈杂的背景音乐、他人交流的咖啡店,豆包依然可以从嘈杂环境中精准筛选用户声音,屏蔽环境人声及噪声干扰。
再比如用豆包音视频通话功能帮助理解屏幕操作。用户遇到不确定的电脑操作时,不用发帖求助或者麻烦朋友,直接可以打视频给豆包,豆包能准确识别页面 GUI 元素以及对应操作步骤逻辑,用自然易懂的方式讲给用户精准的操作指引。

RTC 技术支撑豆包实时音视频
体验了强大的能力和丰富的场景,是时候了解一下豆包实时音视频功能的幕后功臣了——RTC实时音视频技术。
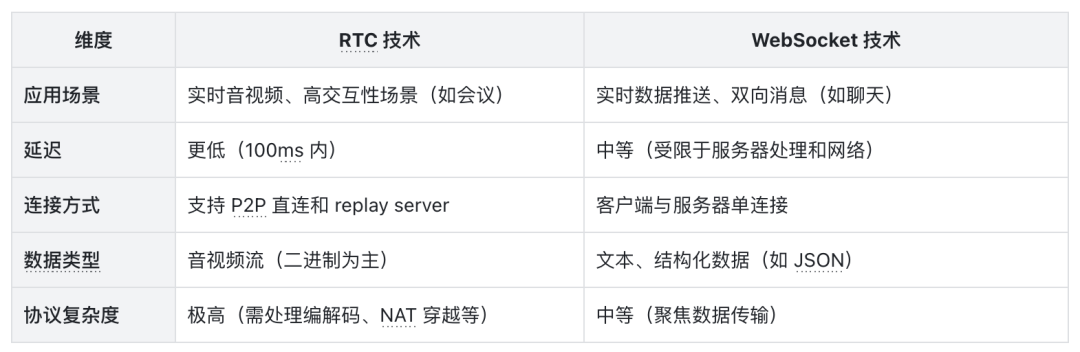
首先聚焦于基础技术的理解认知,目前业界主要有两种处理音视频通信的技术,分别是 RTC 和 WebSocket。
RTC 全称是 Real-Time Communication,是一种通过网络实现音频、视频和数据实时传输的技术,RTC 的核心优势在于毫秒级低延迟和抗弱网能力,适合用于音视频流类型的数据,可应用于视频会议、在线教育、智能驾驶等场景。
WebSocket 则是另一种实时技术,由一组协议和 API 组成,可通过持久的单套接字 socket 连接,在 Web 客户端和 Web 服务器之间实现全双工,实现客户端和服务器主动双向发送数据,相对延迟更久,而且会受限于网络环境。
特工们从应用场景、延迟、连接方式、数据类型、协议复杂度这几个维度对 RTC 与 WebSocket 进行对比:
接着从用户视角出发,当人们体验消费一个流媒体服务时,最基础的要素便是稳定。结合上面对 RTC 技术和 WebSocket 技术特点的理解,可以发现,RTC 的低延迟、稳定性、对网络环境较低的要求,相比 WebSocket 能更好保障视频传输、语音传输的稳定性。
像上文与豆包对话的场景,用户之所以能体验到一个能实时听、实时看的 AI 助手,是因为 AI 在进行同步、低延时的视觉推理和搜索反馈,而这样流畅的交互感对降低卡顿有更高的要求。
为了达成这类目标,豆包采用了火山引擎 RTC 传输方案,借助方案的带宽估计、前向纠错、丢包重传等抗拥塞能力与端到端传输优化,能够有效降低移动网络或拥挤 Wi‑Fi 下画面卡断、不清晰问题的出现,即便是 720p 高清视频流,依然能够保障稳定的低延时传输,从而得以支撑 AI 实时的多模态的感知与推理。
更进一步,在大模型应用时代下的与 AI 助手语音通话的场景中,RTC 可以为实时语音对话的低延迟与强对抗性保驾护航,让 AI 语音对话有更高的效率、更自然真实、更接近活人感。例如,从产品体验层面,用户在通话中可以更快速、更低延迟地收到 AI 助手的语音回复,也可以像与真人对话一样随时打断、开启新的话题。
再回到泛化的现实生活场景,生活中网络环境复杂多变,弱网环境更偏常态。虽然理想网络下 RTC 与传统 WebSocket 的语音延迟差异可能差距还不算特别显著,但根据线上实测数据,在网络条件不太好的情况下,RTC 的表现比 WebSocket 好太多了。
具体来说:当网络有 20% 的数据包丢失时,用 WebSocket 的话,会出现严重的卡顿甚至断连,这会导致线上 15% 的用户根本没法正常使用; 但 RTC 就很优秀,就算网络丢包率高达 80%,用户无法使用的比例也只有 1%,虽然这时候使用起来可能会感觉有点延迟,但差不多 4.6 秒左右就能有反应,影响不算大。
从行业产品视角也不例外,除了豆包这类 AI 助理可实时音视频通话,语音应用场景在大模型应用落地中也愈发被看好,这对语音交互的实时性和并发管理提出了更高要求。
例如 AI 社交娱乐赛道,像狼人杀这类团队小游戏,玩家可以和多个 AI NPC 实时对话互动;在 AI 效率办公赛道,能通过语音交互让多个 AI Agent 工作助手并行任务处理。
在多 Agents 并行的场景下,传统 WebSocket 在处理多路音频时复杂性较高,相反 RTC 则具有优势。RTC 的房间管理、音频流控制、混音、角色权限等能力,可用于精细管理多个语音流与优先级,从而能构建一个结构清晰、响应流畅的 Multi Agents 语音交互系统。

在火山引擎可使用同款对话式 AI 方案
但凡事都有两面性,分析了这么多 RTC 技术的优点,它仍然存在问题。尽管 RTC 具有低延迟、抗弱网的优势,局限却在于自建集成门槛高、云端服务资源投入大。这些高门槛和高投入特点,导致很多应用开发时望而却步,在实际落地中只能降级采用 WebSocket 技术,为了可实现性而让步了体验。
事实上,不论是个人开发者或是企业内开发团队,在做技术选型时,都是既想要满足产品经理的需求、迎合用户诉求,又想要用尽量低的成本做好实现的方案,确实不是一件容易的事情。
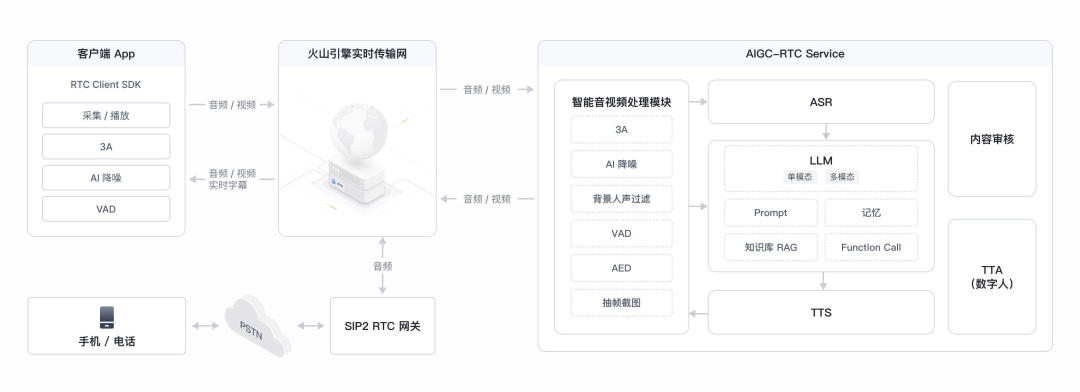
不过好在火山引擎已经提前替开发者们考虑到了这一痛点,提供的火山引擎对话式 AI 一站式方案能够帮助企业以更低的集成门槛,实现超低延时、稳定流畅、自然逼真的 AI 音视频交互能力。
除了上面硬核的抗弱网、低延时能力之外,更惊喜地发现,对话式 AI 方案方案很接近真人!在与 AI 助手实时对话交流时,“活人感”是很重要的影响体验的因素。要想实现“活人感”,关键还需要具备准确断句的能力,这也是 AI 语音中最难解决的问题之一。
试想与真人交谈时,说话人之间可以随时灵活地判断对方有没有讲完话,也可以准确地判断说话人是不是想要打断对话。但一些传统 AI 语音对话只能机械地识别是否讲完,用户也只能等 AI 完全说完一段话才有机会开启新的对话。
这其中的技术挑战不少,一方面要求 AI 灵活理解语义和人声的完结,避免用户在思考时短暂停顿就收到回复;另一方面还需要 AI 判断输入的人声是否具有打断意图。应对这些问题,火山引擎基于 RTC 的对话式 AI 方案,已经支持了智能语义判停和声纹降噪等功能,从而让智能体更有“活人感”。
比如前文出现的在咖啡店嘈杂环境音下,用户打断豆包说话转而新起一个问题的例子,就可以直观地感受到智能判停和抗背景噪音的效果。
开发者现在就可以通过火山引擎官网低门槛接入对话式 AI 方案,同时获得每月 10,000 分钟的免费额度。
官网:https://www.volcengine.com/product/veRTC/ConversationalAI
也许下一个开发出像豆包 AI 音视频通话功能的人就是你。




(文:特工宇宙)