





余承东表示:“鸿蒙单框架原生的应用与元服务数量超过3万个,虽然跟安卓、iOS等十几万的体量相比还有差距,但我想告诉大家,TOP5000的应用占了消费者使用时长的99.9%。”

与此同时,HarmonyOS 6 Developer Beta今日面向开发者正式启动,这是一个更加全面拥抱AI的智能操作系统。
鸿蒙6作为全场景智能操作系统,在流畅度、安全性、连接性、开发友好度等方面全盘升级,并正式启动开发者测试计划。

其中,鸿蒙智能体框架有着三大核心优势:更自然的AI交互体验、系统级服务闭环能力以及多智能体协同功能,首批50多个鸿蒙智能体即将上线,覆盖工作生活多个领域。
苹果AI一直在放鸽子,华为这回则直接把对应的“鸿蒙智能”端上了牌桌。

现场展示的鸿蒙系统创新的“碰一碰”交互功能,可以在所有鸿蒙设备之间无缝分享文件、多设备应用接续操作等十分便捷,而AI智能体更是深入到了应用中,鸿蒙智能体框架具备意图理解、任务执行等能力,能与系统中的应用深度协作,小艺智能体开放平台为应用开发者提供多种工具支持自然对话创建智能体,用户可通过多种方式快速调用智能体服务。
大会上华为还宣布启动1亿元的鸿蒙星光计划,激励年轻开发者创新,还通过多个开发者案例展示了鸿蒙在工作生活、实况服务、云服务、政务安全等领域的应用成果,体现了鸿蒙生态的多元化和多样化场景适配。
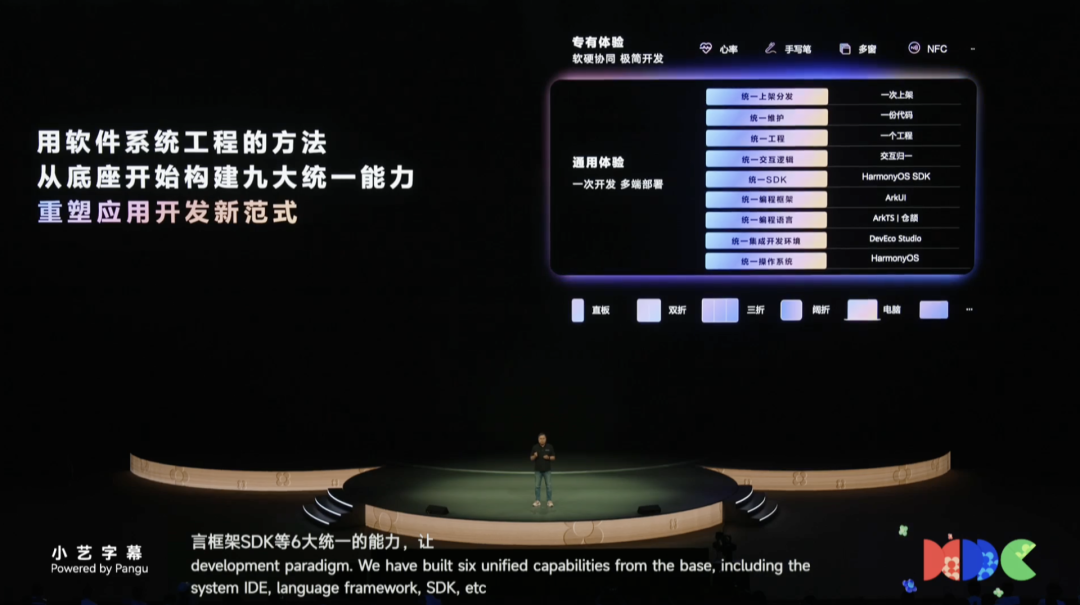
华为终端BG软件部总裁龚体重点阐述了鸿蒙系统一次开发多端部署的核心优势,通过SDK、交互归一等九大统一能力,显著提升开发效率。
此外,华为还对鸿蒙系统专用的AI辅助开发工具DevEco CodeGenie进行了升级,该工具基于大语言模型,通过21亿tokens的鸿蒙知识库训练,具备代码续写、问题定位和UI生成等开发者呼声非常高的核心能力,同时涉及创新的IDE交互设计,可以写出更有“鸿蒙味儿”的代码。

更进一步的目标是,华为还在推动构建中国自己的编程语言:仓颉,仓颉编程语言将于今年7月30日正式开源上线。

在大模型领域,华为新推出了盘古大模型5.5,包括7180亿参数的盘古Ultra自然语言处理大模型和可交互的4D空间生成盘古世界大模型等,在多项评测中表现优异,在复杂的推理能力、工具调用、数学高阶推理和AI编程能力等榜单的评测中,盘古大模型的得分处于业界第一梯队。
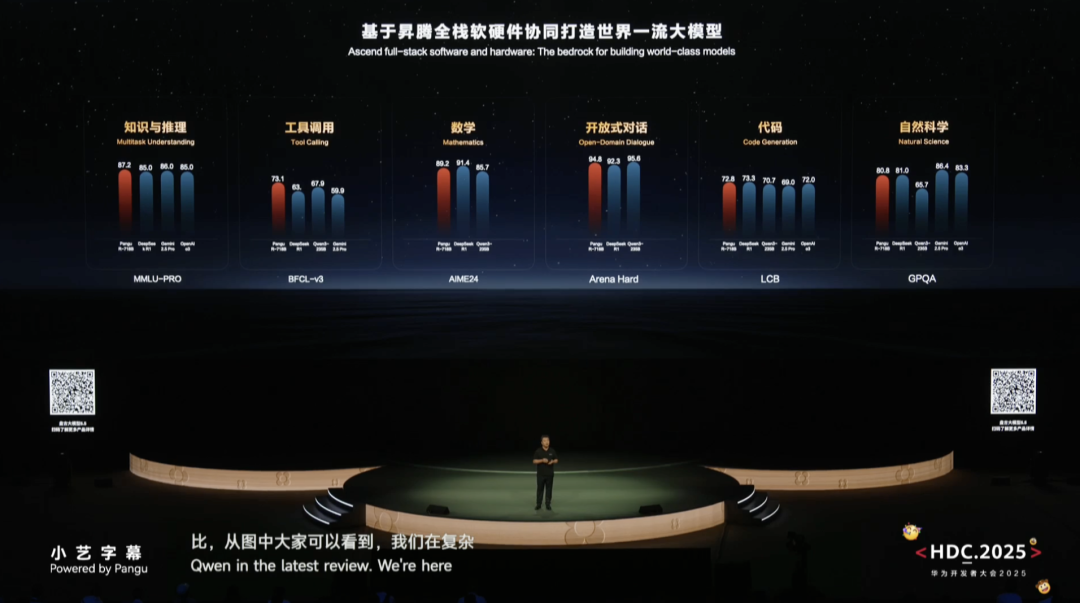
相较于榜单上的排名高低,更重要的一点是,很多领先大模型全都是基于美国的AI芯片进行训练,最新的盘古模型则完全基于CloudMatrix 384超节点的昇腾云服务训练而成,华为用自身实践证明,基于昇腾芯片完全可以训练出世界一流的大模型。

盘古5.5模型在长序列处理、低幻觉、快慢思考自适应等方面进行了技术创新,大大减少了幻觉问题,创新性提出的自适应快慢思考合一技术,使模型能根据问题复杂度自动切换思考模式,提升8倍推理效率,同时针对Agent应用场景进行了优化,在开放域信息获取方面实现高效执行能力。
华为诺亚方舟实验室还布局了扩散大语言模型、动态稀疏比架构、极低比特训练、空间物理智能等前沿技术方向,并通过华为云ModelArts工具链帮助各行各业快速构建基于盘古的专业大模型。
会上,华为还全新发布了盘古世界模型,可生成数字物理空间,通过模拟提升各种类机器人的操作能力;CloudRobo具身智能平台旨在通过云端AI算力为各类联网机器提供智能支持,提供端到端的能力整合,此外,还有数字人相关布局。
近期,华为最受外界关注的还是其CloudMatrix 384超节点,通过“数学补物理,空间换算力,能源助性能”的设计策略,384个昇腾NPU加上192个鲲鹏CPU将单台服务器的算力提升了50倍,达到300Pflops。

据华为公司Fellow、云系统首席专家云舟介绍,384超节点采用两级无收敛交换架构,实现384个节点内高带宽低延迟互联,节点间与节点内带宽差异仅2-3%,延迟增加仅约1微秒,同时发挥超节点带宽优势与模型进行联合优化,超节点架构能显著提升MoE模型训练和推理效率,增强大语言模型推理吞吐量。
业内人士分析,华为奉行系统级、通信优先的单体超级节点的AI算力哲学,旨在通过构建庞大、扁平化的通信域来弥补单个芯片“向上扩展”(scale-up)的性能短板;而NVIDIA因为工艺不受限仍在坚持芯片级、计算优先的主导地位。
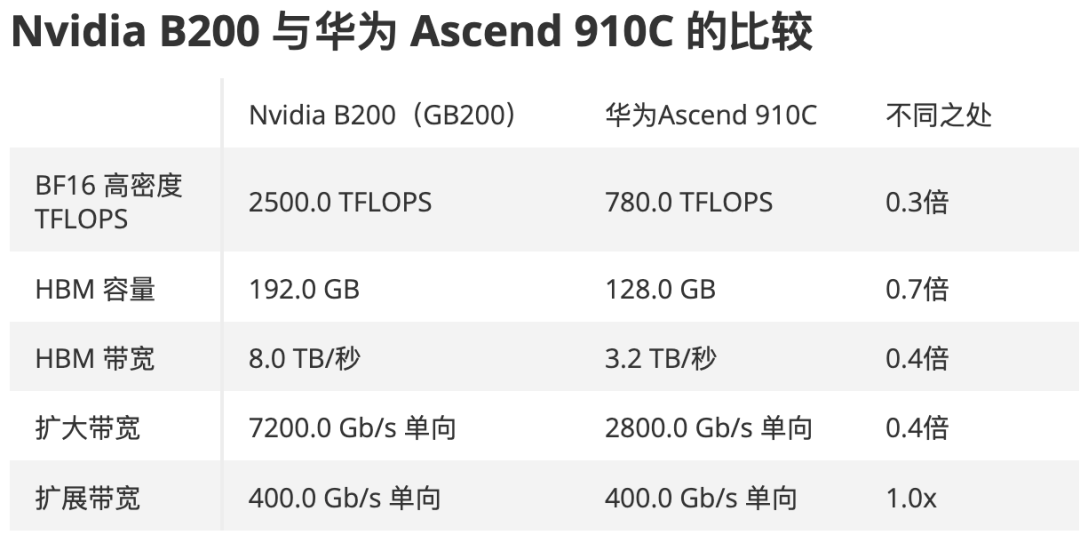
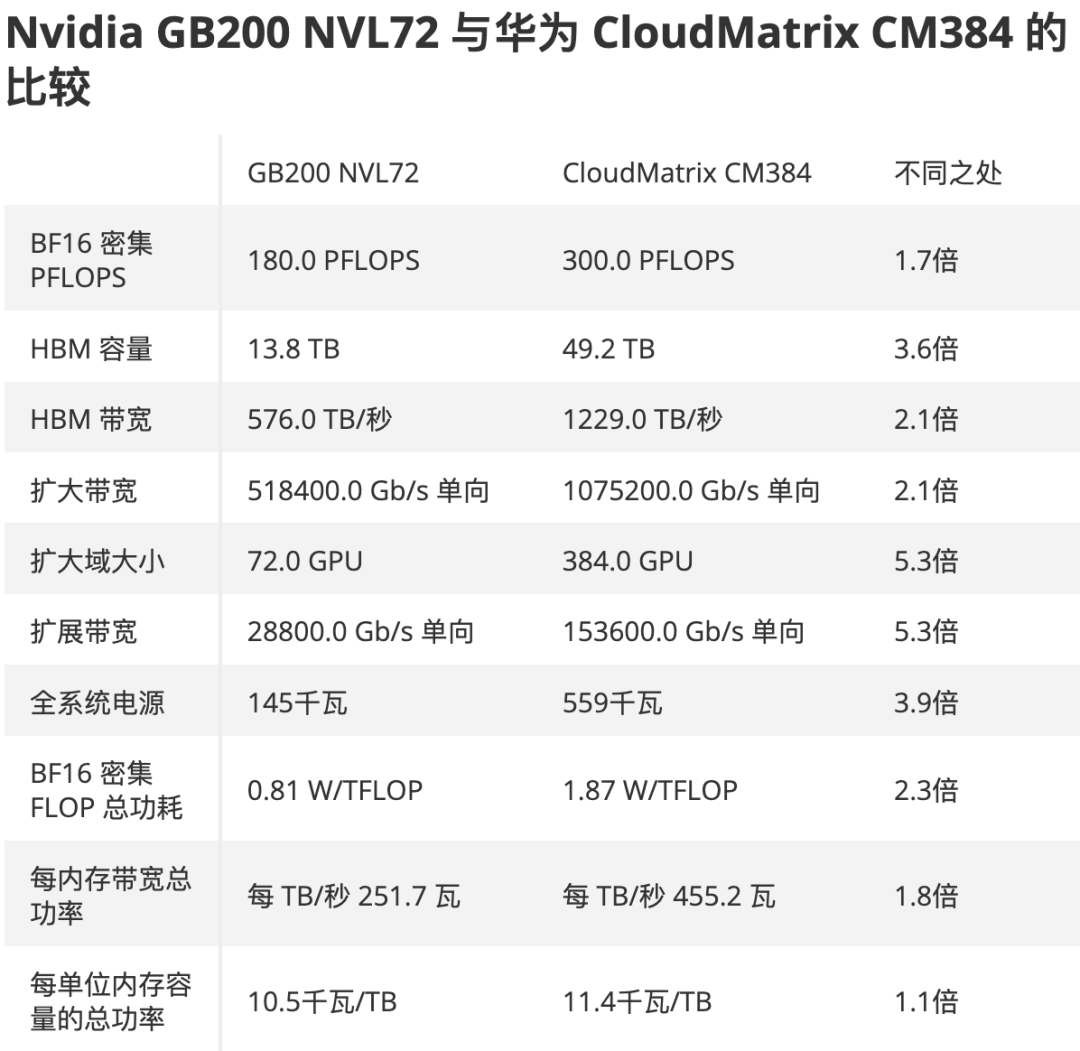
在当下中美AI竞逐和各种制裁限制的背景下,华为优先通过系统级设计来弥补在芯片工艺技术上的滞后,这一趋势可能将全球AI算力市场引向一个新的竞争维度,用中国自己的技术优势,重新定义AI基建的扩展范式,最终,市场将拥有更多样化的AI基础设施选择。
从AI算力角度来看,未来的技术PK也将从单纯的芯片算力堆积,转向系统级的综合效能、成本以及异构硬件与模型融合在一起的成熟度之争。
这场AI突围战,华为又赢了一局。
-END-

(文:头部科技)