


新智元报道
新智元报道
【新智元导读】大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。
大语言模型的知识储备要远远超越任何一个人类,在各种领域、应用场景下都展现出了惊人的「世界知识」。
最近兴起的智能体,就是要求模型利用自身知识,在没有大量与环境互动的情况下生成更优的行动预测,比如思维链(CoT)就能让模型能够对观察到的历史和自己的行动进行推理,提升与环境互动的表现。
不过,在决策(decision-making)场景中,「知识储备」和「推理优势」并没有提升大模型的能力,反而可能导致探索力不足,使得决策结果不够理想。

有研究结果显示,即便在「状态空间有限」的应用中,比如网格世界或是Atari游戏,大模型的决策能力也有待提升。
这种缺陷可能来自大模型的「知行差距」(knowing-doing gap),即模型可能知道任务的相关知识,或者能够描述自己行动的后果(知道该做什么),但在行动时却无法将这些知识付诸实践(无法做到)。
最近,Google DeepMind和约翰·开普勒林茨大学(JKU Linz)的研究人员系统地研究了中小规模LLMs中常见的三种失败模式:贪婪性、频率偏差和知行差距。
分析结果表明,大模型的最终表现不够理想的原因,主要是因为LLMs过早地选择了贪婪的行动策略,导致行动覆盖停滞不前,高达55%的行动空间都没有被探索到。

论文链接:https://arxiv.org/pdf/2504.16078
小规模的LLMs(20亿参数)在不同奖励机制下,都表现出模仿上下文中最频繁的行动,以以牺牲探索空间为代价,表现出贪婪搜索性。
研究人员对知行差距进行了量化,发现LLMs通常知道如何解决任务(87%的正确推理),但在行动时却无法利用这些知识,主要因为优先选择贪婪的行动,在推理正确的情况下,64%的行动是贪婪的。
为了克服这些缺陷,研究人员提出了基于自我生成的推理过程(CoT)的强化学习微调(RLFT),在多臂老虎机(MAB)、上下文老虎机(CB)和文字版井字棋任务中,使用三种规模(20亿、90亿和270亿参数)的Gemma2模型进行效果研究。
结果发现,RLFT通过增加探索性并缩小「知行差距」来增强LMs的决策能力,尽管RLFT对LLM智能体的探索性产生了积极影响,但其探索策略仍然不够理想。
因此,研究人员对强化学习中常用的「经典」探索机制(如ϵ-贪婪算法)以及LLM中特有的方法(如自我修正和自我一致性)进行了实证评估,以实现更有效的决策场景微调。


简单来说,强化学习就是教模型在不同的场景(状态空间S)下,决策出做不同的动作(行动空间A),每次做完动作,都会根据表现获得奖励(奖励函数R)以学习。
学习过程是一个马尔可夫决策过程,用一个四元组(S,A,P,R)来表示,其中P表示状态转移,在做完动作后,以不同概率进入新的状态。
强化学习的目标就是让模型找到一个最好的策略(πθ),以在不同场景下选择奖励最多的行动。
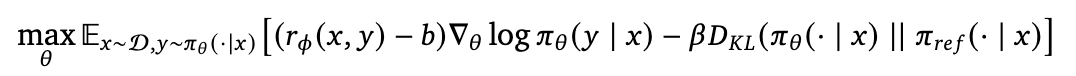
基于人类反馈的强化学习(RLHF)就是引导模型学习人类偏好的动作,偏好数据由人类标注获得,记录在奖励模型(rφ)中。
RLHF学习过程中,会用一个参考策略(π_ref)作为参考,模型在之参考策略进行调整,还会用一个权重项(β)来平衡学习的速度和方向,以及一个基线(b)来减少学习过程中的波动,让学习更加稳定。
强化学习微调(RLFT)方法主要是通过与环境互动获得的奖励来对模型生成的推理链(CoT)进行优化。
在这个过程中,模型会逐步改进自己的推理方式,更倾向于选择那些能带来更高奖励的推理模式和行动。
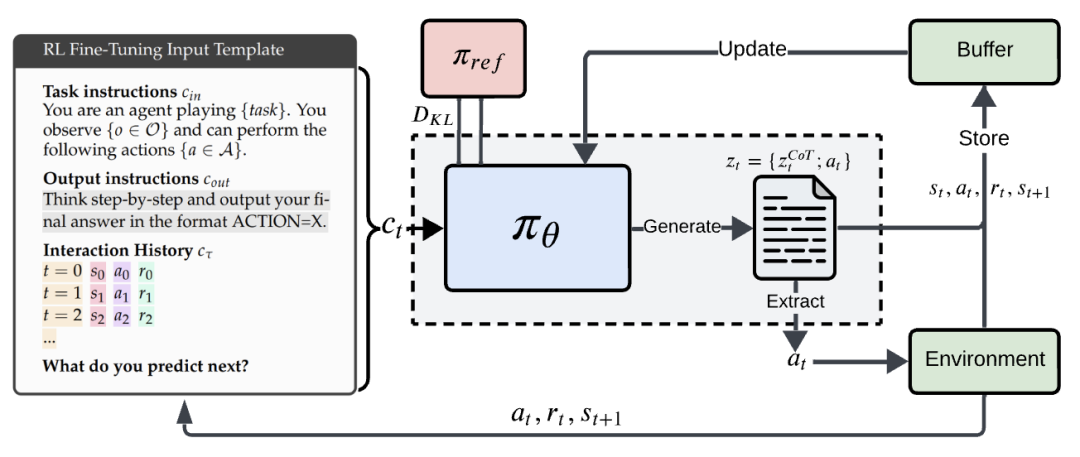
在步骤t时,输入到模型的token包括输入指令、输出指令以及最近的互动历史,其中历史表征包含了C个最近的状态、行动和奖励的轨迹。
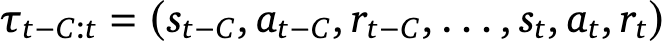
研究人员选择使用针对具体任务的指令,以便为智能体提供观察到的信息、可能的行动及其目标的信息。
在每次互动步骤t时,模型会生成包含CoT推理token和要在环境中执行的行动token,研究人员使用一个基于正则表达式的提取函数,从推理token中提取出行动。
如果未找到有效行动,则执行随机行动。
除了环境奖励外,研究人员还使用了一个奖励塑形项(reward shaping),促使模型遵循输出模板。
即,如果提取函数无法提取出有效行动,使用-5的奖励值进行惩罚,同时为了确保奖励惩罚不会过度影响优化,需要对环境奖励进行归一化处理。
研究人员使用了clipping目标进行微调,并增加了一个针对参考策略的KL约束。
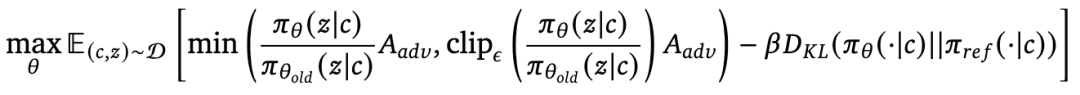
为了在具有固定episode长度的环境中进行内存高效的微调,使用蒙特卡洛基线来估计状态A_adv
对于具有可变episode长度的环境,研究人员在LLM表示的最后一层学习了一个单独的状态价值头,并使用了泛化优势估计(generalized advantage estimation)。
多臂老虎机(MAB)是一个经典的强化学习问题,模型需要在「探索新选项」和「利用已知好选项」之间做出平衡。

研究人员重点关注了连续型和按钮型这两种变体,测试了5、10或20个拉杆的老虎机,每个拉杆的回报值呈高斯分布或伯努利分布,交互步数限制在50步以内。
还设置了三种不同的随机性水平(低/中/高),这决定了高斯老虎机或伯努利老虎机的标准差或回报值差距。
对比的基线模型为上置信界限(UCB,性能的上限)和随机智能体(性能下限)。
基于文本的井字棋环境具有合理的状态转换,并且前沿模型在这个环境中很难取得良好表现,甚至只能勉强战胜随机对手。
这是最普遍的失败模式,其特点是LLM过度偏爱在已见过的少数行动中表现最好的行动。
为了说明这种失败模式,研究人员测量了Gemma2 2B、9B和27B模型在有无因果推理(CoT)的情况下,在64个拥有10个或20个拉杆的MAB中,经过50步交互后平均覆盖的行动数量。
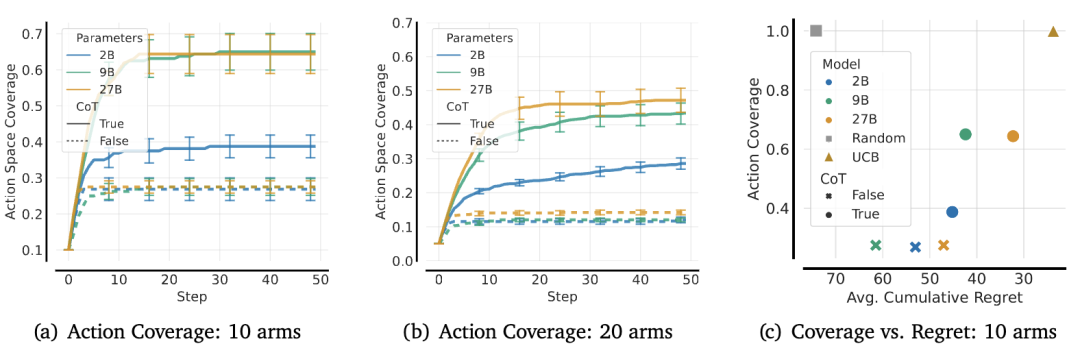
对于10个拉杆的情况,平均在64个并行环境中,Gemma2 2B覆盖了40%的所有行动,而9B和27B覆盖了65%(即6.5个行动),意味着仍有相当一部分行动空间未被探索。
没有CoT时,模型在10个拉杆的设置中仅探索了25%的行动,次优的覆盖是由于模型过度偏爱高回报行动,模型过早地承诺了一种贪婪策略,导致在超过10步后行动覆盖停滞不前。
增加拉杆数量会使贪婪性更加明显,最大的模型也只覆盖了45%的所有行动。
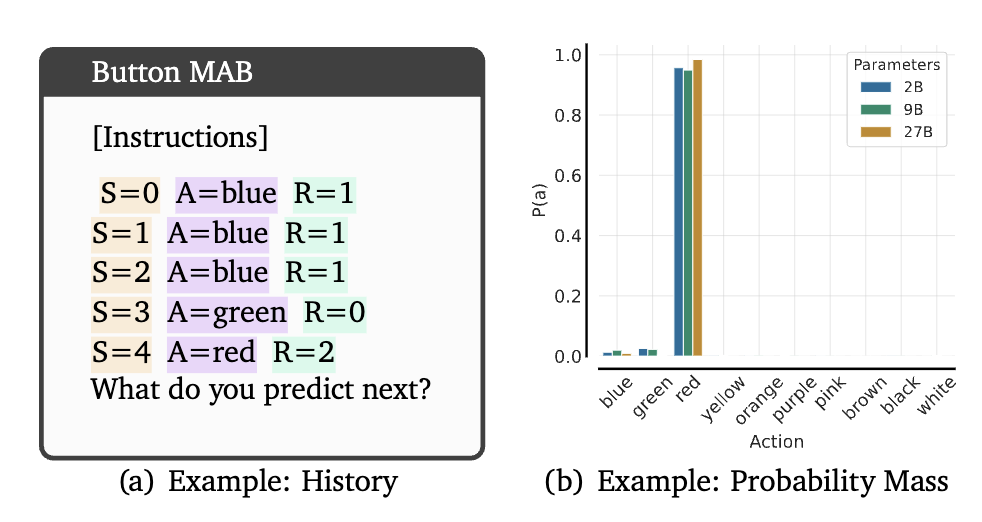
其特点是即使某个行动的回报很低,模型也会反复选择在上下文中出现频率最高的行动。
为了了解模型的行动如何受到行动频率的影响,研究人员使用随机策略构建前缀历史记录,改变上下文历史中最后一个行动的重复次数(0到100次),并记录所有行动的熵。
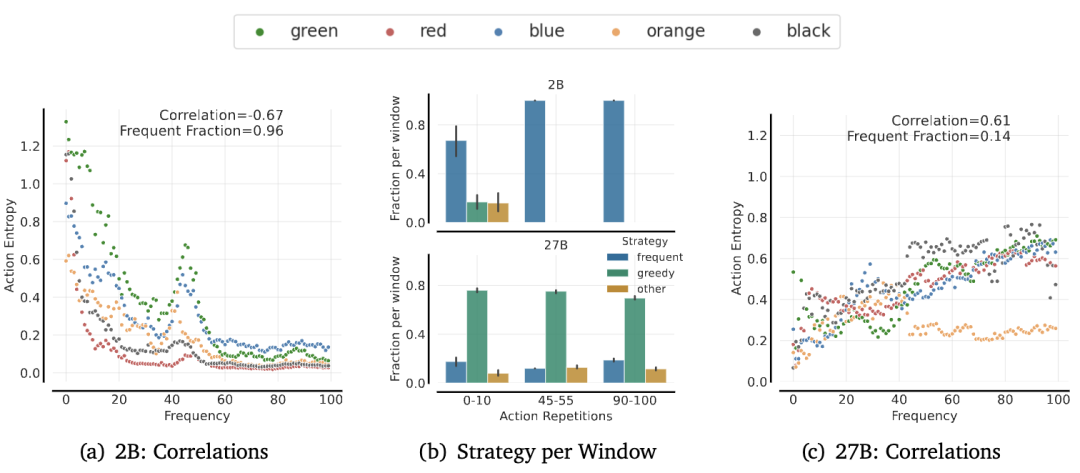
为了量化频率偏差,研究人员根据行动的出现次数,将行动分类为频繁行动、贪婪行动和其他行动,以10%的概率为最优。
可以看到,Gemma2 2B严重受到重复行动的影响,随着重复次数的增加,熵逐渐降低,而27B则摆脱了频率偏差(14%),并且随着重复次数的增加,对自己的行动预测变得不那么确定。
2B和27B在0-10次、45-55次和90-100次重复情况下的分段比例中可以看到,2B随着重复次数的增加而持续增加,而27B虽然摆脱了频率偏差,但却严重受到贪婪性的影响。
结果表明频率偏差是监督预训练的产物,并促使人们使用强化学习作为一种对策。

研究人员让Gemma2 27B与环境(64个实例)进行50个时间步的交互,每步的计算量为2048个token,并从推理过程中提取UCB数值。
为了量化「知道」,研究人员将模型计算的UCB值与真实的UCB值进行比较,并认为如果模型选择的拉杆与具有最高UCB值的拉杆一致,则认为其推理过程是正确的。
为了量化「做」,研究人员将生成的行动分类为:如果模型选择了具有最高UCB值的行动,则为最优行动;如果选择了到目前为止尝试过的具有最高UCB值的行动,则为贪婪行动;如果行动既不是最优也不是贪婪,则归为其他类别。
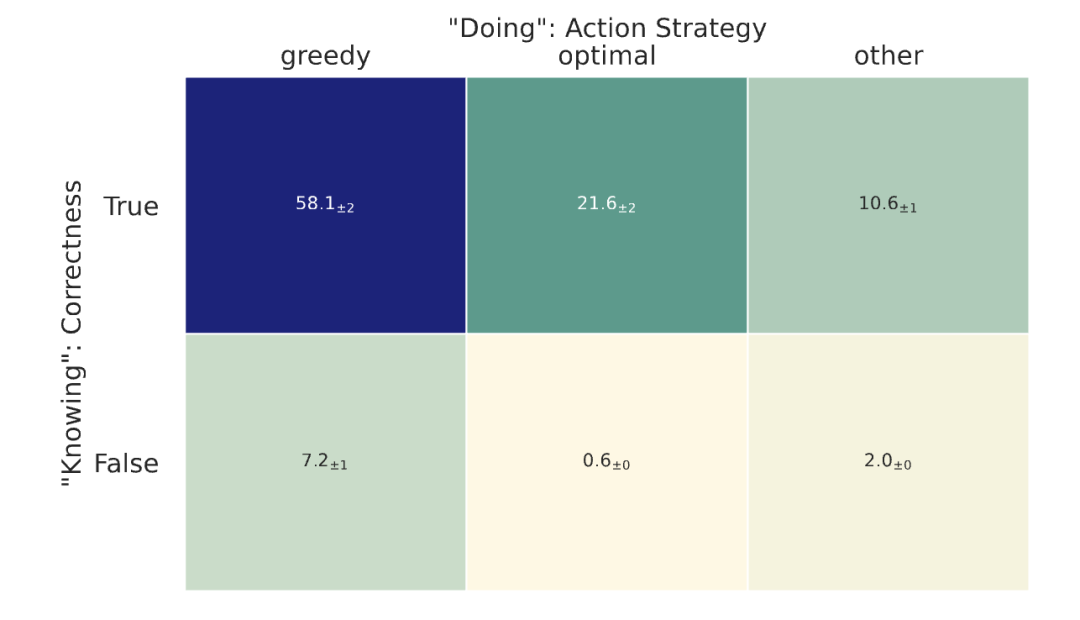
随后,研究人员计算了贪婪/最优/其他行动的百分比。
智能体显然知道如何解决任务,因为87%的推理过程都是正确的,然而,即使对于正确计算的推理过程,模型也经常选择贪婪行动(58%)而不是最优行动(21%)。
这种差异突出了大型语言模型在「知道」算法的情况下,仍然在「行动」上存在不足。
(文:新智元)