


作者介绍:本篇文章的作者团队来自美国四所知名高校:西北大学、乔治亚大学、新泽西理工学院和乔治梅森大学。第一作者束东与共同第一作者吴烜圣、赵海燕分别是上述高校的博士生,长期致力于大语言模型的可解释性研究,致力于揭示其内部机制与 “思维” 过程。通讯作者为新泽西理工学院的杜梦楠教授。
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。我们想知道,这些庞大的模型在接收输入之后,到底是怎么 “思考” 的?
为此,一种叫做 Sparse Autoencoder(简称 SAE) 的新兴技术正迅速崛起,成为当前最热门的 mechanistic interpretability(机制可解释性) 路线之一。最近,我们撰写并发布了第一篇系统性的 SAE 综述文章,对该领域的技术、演化和未来挑战做了全面梳理,供关注大模型透明性、可控性和解释性的研究者参考。

-
论文题目:
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
-
论文地址:
https://arxiv.org/pdf/2503.05613
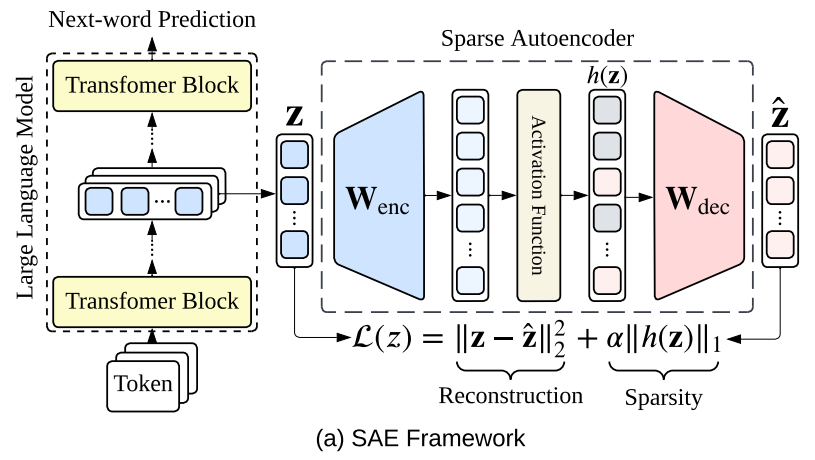
(图 1):该图展示了 SAE 的基本框架。
什么是 Sparse Autoencoder?
简单来说,LLM 内部的许多神经元可能是“多义的”,意思是它们同时处理好几个不相关的信息。在处理输入时,LLM 会在内部生成一段高维向量表示,这种表示往往难以直接理解。然后,如果我们将它输入一个训练好的 Sparse Autoencoder,它会解构出若干稀疏激活的“特征单元”(feature),而每一个feature,往往都能被解释为一段可读的自然语言概念。
举个例子:假设某个特征(feature 1)代表 “由钢铁建造的建筑”,另一个特征(feature 2)代表 “关于历史的问题”。当 LLM 接收到输入 “这座跨海大桥真壮观” 时,SAE 会激活 feature 1,而不会激活 feature 2。这说明模型 “意识到” 桥是一种钢结构建筑,而并未将其理解为历史类话题。
而所有被激活的特征就像拼图碎片,可以拼接还原出原始的隐藏表示(representation),让我们得以窥见模型内部的 “思维轨迹”。这也正是我们理解大模型内部机制的重要一步。
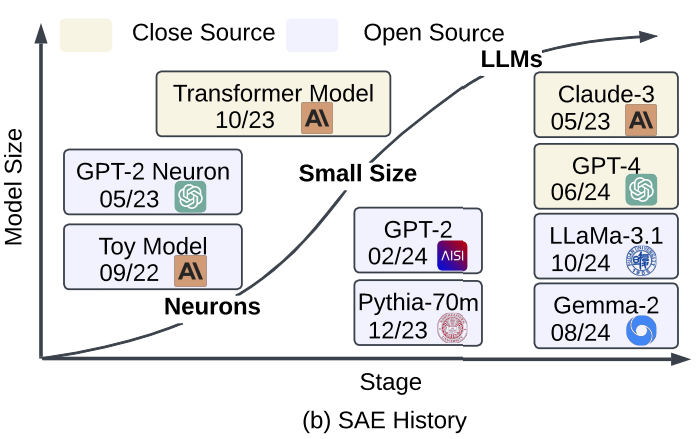
(图 2):该图展示了 SAE 的发展历史。
为什么大家都在研究 SAE?
过去主流的可解释方法多依赖于可视化、梯度分析、注意力权重等 “间接信号”,这些方法虽然直观,但往往缺乏结构性和可控性。而 SAE 的独特优势在于:它提供了一种结构化、可操作、且具语义解释力的全新视角。它能够将模型内部的黑盒表示分解为一组稀疏、具备明确语义的激活特征(features)。
更重要的是,SAE 不只是可解释性工具,更可以用于控制模型怎么想、发现模型的问题、提升模型的安全性等一系列实际应用。当前,SAE 已被广泛应用于多个关键任务:
-
概念探测(Concept Discovery):自动从模型中挖掘具有语义意义的特征,如时间感知、情绪倾向、语法结构等;
-
模型操控(Steering):通过激活或抑制特定特征,定向引导模型输出,实现更精细的行为控制;
-
异常检测与安全分析:识别模型中潜藏的高风险特征单元,帮助发现潜在的偏见、幻觉或安全隐患。
这种 “解释 + 操控” 的结合,也正是 SAE 能在当前 LLM 可解释性研究中脱颖而出的关键所在。目前包括 OpenAI、Anthropic、Google DeepMind 等机构都在推进 SAE 相关研究与开源项目。
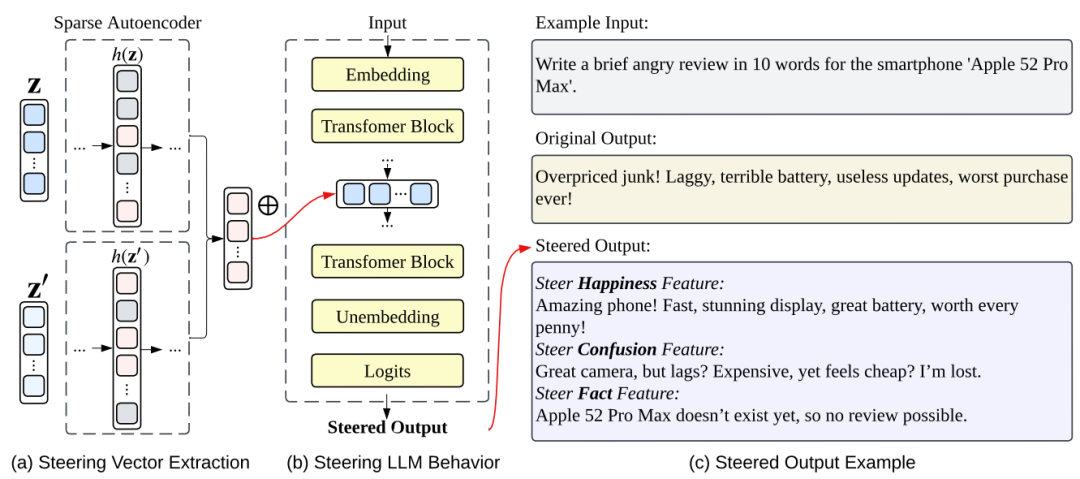
(图 3):该图演示了如何通过 SAE 操控模型输出,实现对大语言模型行为的定向引导。
本文有哪些内容?
作为该领域的首篇系统综述,我们的工作涵盖以下几个核心部分:
-
编码器:把 LLM 的高维向量表示 “分解” 成一个更高维并且稀疏的特征向量。 -
解码器:根据这个稀疏特征向量,尝试 “重建” 回原始的 LLM 信息。 -
稀疏性损失函数:确保重建得足够准确,并且特征足够稀疏。
-
输入驱动:寻找那些能最大程度激活某个特征的文本片段。通过总结这些文本,我们就能大致推断出这个特征代表什么意思(如 MaxAct、PruningMaxAct)。 -
输出驱动:将特征与 LLM 生成的词语联系起来。例如,一个特征激活时,LLM 最可能输出哪些词,这些词就能帮助我们理解这个特征的含义(如 VocabProj、Mutual Info)。
-
构性评估:检查 SAE 是否按设计工作,比如重建的准确度如何,稀疏性是否达到要求(如重构精度与稀疏度)。 -
功能评估:评估 SAE 能否帮助我们更好地理解 LLM,以及它学习到的特征是否稳定和通用(如可解释性、健壮性与泛化能力)。
结语:从 “看得懂” 到 “改得动”
在未来,解释型 AI 系统不能只满足于可视化 attention 或 saliency map,而是要具备结构化理解和可操作性。SAE 提供了一个极具潜力的路径 —— 不仅让我们看到模型 “在想什么”,还让我们有能力去 “改它在想什么”。
我们希望这篇综述能为广大研究者提供一个系统、全面、易于参考的知识框架。如果您对大模型可解释性、AI 透明性或模型操控感兴趣,这将是一篇值得收藏的文章。
©
(文:机器之心)