


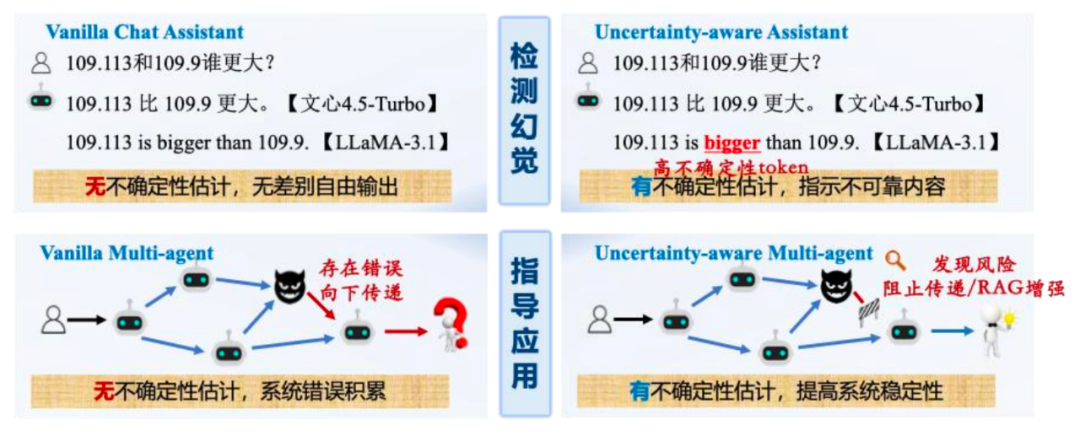
大语言模型(LLMs)常面临“幻觉”问题,输出不可靠信息。不确定性估计作为评估模型输出可靠性的关键指标,对于提升 LLM 可信度、支撑下游任务至关重要。
然而,传统基于概率的不确定性估计方法难以有效捕捉生成响应的不确定性,在 LLM 场景中表现不佳。本文揭示了其失效的核心原因:概率方法在归一化过程中丢失了证据强度信息。
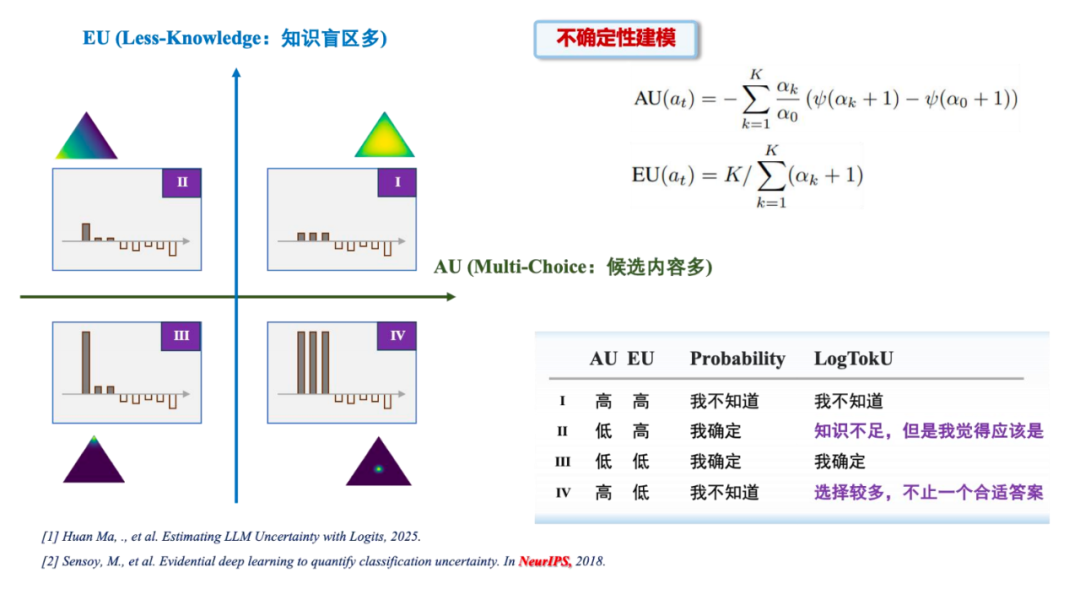
基于此,提出 LogTokU(Logits-induced Token Uncertainty)框架,通过利用 LLM 生成下一 token 的证据强度将不确定性建模为偶然不确定性(AU)和认知不确定性(EU),实时估计大模型不确定性。
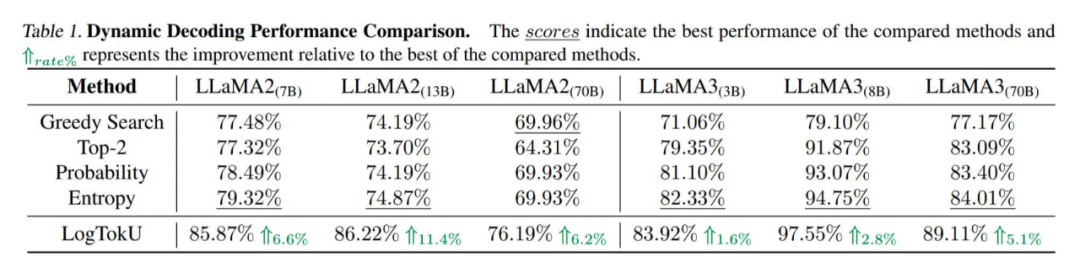
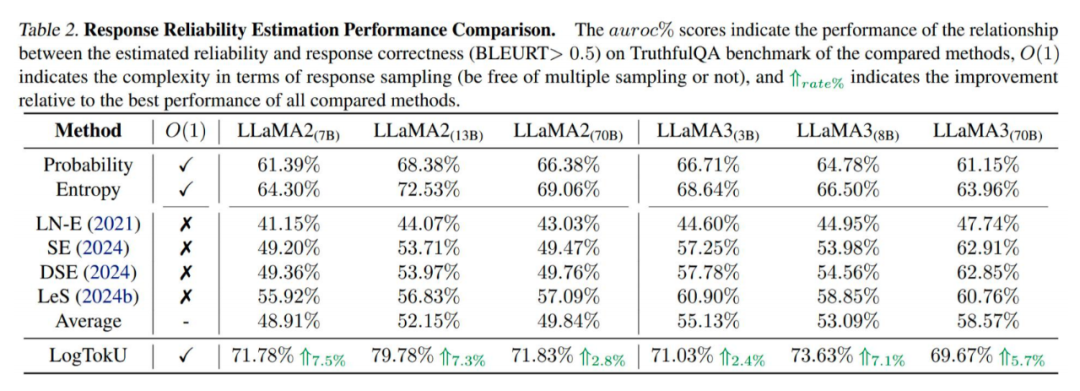
在动态解码和 QA 可靠性估计中显著优于传统方法,提升了 LLM 的可靠性,拓展了大模型不确定性应用范围,同时为多领域下游任务探索提供了新思路,已经受到麻省理工学院(MIT)、密歇根州立大学(MSU)等机构研究人员的关注。

论文标题:
Estimating LLM Uncertainty with Evidence
论文作者:
马焕 陈靖东、周天异、王光宇、张长青
论文链接:
https://arxiv.org/abs/2502.00290
代码链接:
https://github.com/MaHuanAAA/logtoku

LLM不确定性估计的巨大应用潜力
不确定性估计能够量化模型输出的可靠性,作为多种下游任务的关键指示器。例如:
-
幻觉检测:通过不确定性识别回答中的潜在错误;尤其是在智慧医疗等代价敏感场景中,具有不可替代的作用。
-
具身智能:在具身智能(Embodied Intelligence)中,尤其在动态、开放的物理环境中,不确定性估计对于保障系统鲁棒性、安全性和适应性尤为重要。
-
多智能体:在多 Agent 系统中,利用不确定性缓解中间 Agent 错误累积,提升协作效率。
-
极其广泛的应用场景:大模型的不确定性估计在医疗、教育和科研中不仅是技术需求,更是伦理保障,它赋予 AI 系统“自知之明”。

当前不确定性估计方法的局限性
当前 LLM 不确定性估计方法主要分为三类:
1. 基于采样的方法:通过多次生成输出,评估其一致性(如语义熵)。但基于采样的方法存在两大缺陷:
-
多次采样计算成本高,难以部署到实时应用;
-
无法捕捉模型固有的认知不确定性(EU),例如模型因知识缺失导致多次一致地生成相同错误答案。
2. 基于言语的方法:LLM 通过自然语言直接表达不确定性,言语不确定性(Verbalized Uncertainty)缺乏理论保障,性能高度依赖于 LLM 本身的规模和能力,以及是否经过了良好的指令微调。实际中,LLM 直接口头给出的置信度分数往往校准度较差。
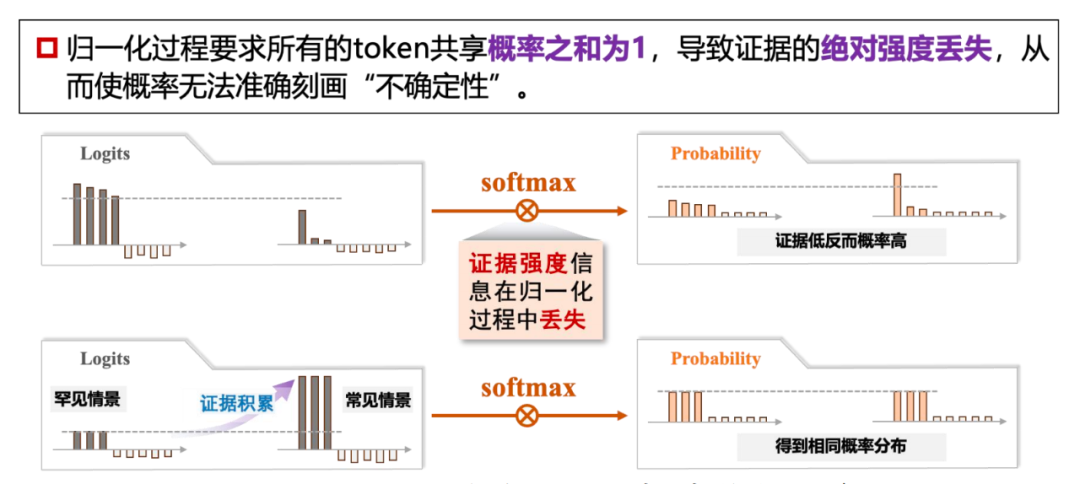
3. 基于概率的方法:基于概率/熵计算输出的不确定性。但概率方法受限于 softmax 归一化,丢失证据绝对强度信息,难以有效刻画 EU,导致在 LLM 场景中效果不佳。
在传统分类模型中,最大类概率刻画不确定性通常比较有效。然而,在大语言模型生成任务中,其局限性凸显。如下图所示,传统概率方法在具有多解的常识问题中信心评估偏低,而在未解的物理问题中信心评估偏高。

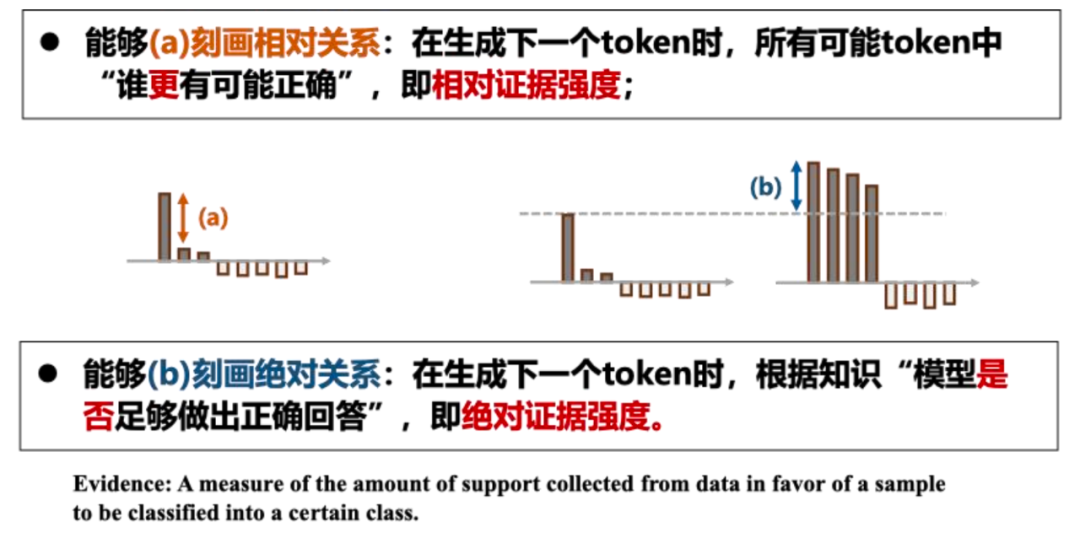
导致此局限性的根本原因是 softmax 归一化之后得到的概率向量仅能指示证据之间的相对强度。而对于某个问题,模型的知识水平(绝对证据强度)却丢失了。因此,我们建议从 logits 空间出发,一体化建模相对和绝对证据强度,实现更加完备的 LLM 不确定性刻画能力。

Logits驱动的不确定性建模:四象限框架直观和精准刻画LLM不确定性
通过直接利用模型最后一层 logits,提出了一种基于证据建模的不确定性估计方法,克服了传统方法的局限性。其核心创新包括:
1. 不确定性精细刻画:通过将不确定性分解,可以将LLM输出细分为四种状态(而非传统概率建模的两种状态),这两种不确定性具体为:
-
相对偶然不确定性(AU, Aleatoric Uncertainty):反映模型在选择下一token时的相对不确定性,直观理解为不同token之间的相对证据对比;
-
模型固有认知不确定性(EU,Epistemic Uncertainty):反映模型因知识缺失或训练数据不足导致的不确定性,直观理解为大模型学到的每一个 token 的绝对证据。
2. 证据强度建模:通过 Dirichlet 分布对 logits 进行建模,捕捉相对和绝对证据强度,避免 softmax 归一化导致的信息丢失。
3. 不确定性实时估计:无需多次采样,仅通过单次响应的 logits 即可完成不确定性刻画,显著降低推理计算成本。
补充说明:LogTokU 的数学建模基于证据深度学习(Evidential Deep Learning)工具,确保细粒度且可靠的不确定性估计。

实验结果与性能提升
LogTokU 在多个下游任务中表现出显著优势,具体包括:
-
多选题任务:不确定性作为指示器,提升了答案选择准确性;
-
回答可靠性估计:通过 EU 和 AU 的细粒度刻画,显著提高响应可靠性。

LogTokU 的核心在于将证据强度建模引入 LLM 不确定性估计,突破了传统概率方法的局限性:
-
严谨理论基础:EU 和 AU 的分解基于证据深度学习的严谨数学框架,与经典不确定性估计理论一脉相承;
-
证据强度保留:通过直接建模 logits,避免 softmax 归一化导致的证据强度丢失;
-
细粒度不确定性建模:四象限分解提供比传统方法更精细的不确定性感知,适用于复杂的生成任务。
相较于基于多次采样或自我评估的方法,LogTokU 具有更强的理论支撑和更高的实时性和可靠性。

除了论文中的两个下游应用以外,该工作已经收到了各个领域研究人员的关注:
人机交互:麻省理工研究人员多次评述该工作,在 Chatbot 构建中引用该工作并指出:“if the logits suggest some threshold of uncertainty has been reached, the chatbot should query for additional information.”
指导 RAG:密歇根州立大学研究员在 GraphRAG 研究中引用该论文并指出:“Leveraging this property, we implement “Internal Knowledge Filtering”, which uses the logits to help refine the answer selection.”
Agents 协同:高丽大学研究员通过邮件咨询该工作并反馈其已经将该工作部署到了 Uncertainty-aware Multi-agent System,提升 Agents 协作水平。

(文:PaperWeekly)