


「2026 年将是具身智能的下半场,下半场的核心是应用。应用的供需两侧都在走向成熟。」
在业界普遍认为具身智能行业还处于「技术卡点」阶段的时候,星海图 CEO 高继扬给出了具身智能「下半场」的一些判断。
「过去两年基本上是全民探索具身智能可用场景的阶段。大大小小的企业,所有潜在的用人单位,都在思考如何用具身智能来优化自己的工作流程。许多应用场景正逐渐变得清晰。同时,整个市场的预期也回归到了一个比较理性的状态。」
同时,对于追求「通用人形机器人」的「通用」,高继扬也给出了一些不一样的看法。高继扬认为,从商业和产品价值的角度来看,当前阶段具身智能最有价值的是实现对象泛化和动作泛化。而实现本体泛化在商业上的重要性没那么高。

在 AGI Playground 大会上,高继扬分享了近期他在具身智能领域的最新思考,输出了一些非常精彩观点:
-
具身智能进展缓慢,背后的根本原因在于具身智能所需要的高质量数据是缺失的。而数据缺失,是因为缺少高质量、合适的本体。
-
具身智能,首先要有一个「正确的本体」,一个标准的本体。
-
把数据采集当作一项生产活动来看待。
-
具身智能基础模型在第一阶段会呈现出来的范式是,在垂直场景的简单任务上实现零样本泛化,在复杂任务上实现少样本泛化。这里的「少样本」,定义为完成新任务所需要的增量数据条数,大概在 100 条这个量级。
-
从商业和产品价值的角度来看,在当前阶段,具身智能最有价值的是实现对象泛化和动作泛化。在当前阶段,实现本体泛化在商业上的重要性没那么高。
以下是现场分享实录,经 Founder Park 整理后发布。
超 7000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

-
最新、最值得关注的 AI 新品资讯;
-
不定期赠送热门新品的邀请码、会员码;
-
最精准的AI产品曝光渠道
01
具身智能是不能有短板的游戏
具身智能并非一个「纯软件」的赛道,它是一个软硬件深度结合的领域。因此,我们称之为一个「没有短板的游戏」,其具体表现就是我们所说的「from motor to model」(从电机到模型)。
具身智能是一个从电机、到整机、再到数据和模型等一系列要素的整合。如果我们做一个对比,会发现大语言模型有一个显著特点,那就是「模型即产品」,模型本身直接决定了产品的体验。而且,在训练大语言模型时,所需要的数据很多都可以在互联网上公开获取,因为人类在过去二十多年里积累了海量的多模态数据。随着模型能力的提升,应用层产品也很快就进入了爆发期。
然而,当我们回到具身智能领域,会发现智能进展比较缓慢。我认为,背后的根本原因在于具身智能所需要的高质量数据是缺失的。而数据缺失,又是因为缺少高质量、合适的本体,也就是我们常说的「整机」。再往上看,会发现整个供应链都是缺乏且不成熟的。所以说,从供应链的零部件、电机,到整机,再到遥操作和数据,具身智能所需要的各项前期工作都还没有完全成熟。
这是具身智能与大语言模型在发展上的一个显著区别。这也印证了刚刚所讲的,「整机」加上「智能」才构成一个完整的产品。只有模型和算法,并不能构成一个可以为用户提供价值的「商品」。因此,做具身智能的核心是「整机+智能」的定位。
在这个定位之下,未来两到三年,具身智能应该为客户和世界提供什么样的产品形态?
我认为,中间这一列所展示的「整机+预训练模型+后训练工具」的组合,是一种概率很高的产品形态。这里的后训练工具,可以理解为是一套遥操作设备,用来遥控机器人完成特定领域或场景下的各种任务。
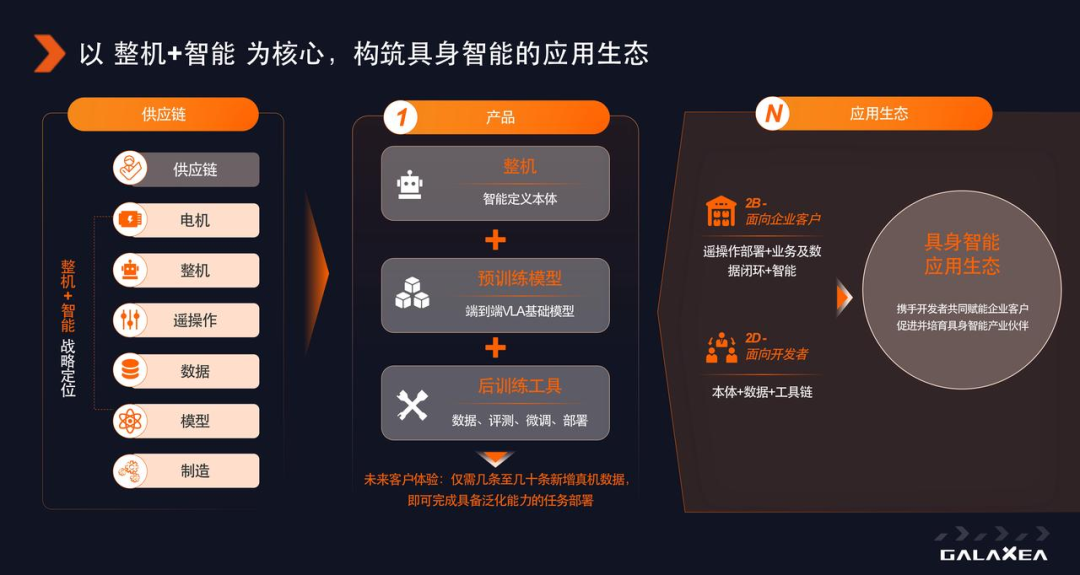
那么,它带给客户的产品体验应该是什么样的?就像培训一位新员工一样,我们用遥操作设备在任务场景里采集几条到几十条数据,用这些数据去微调(fine-tune)我们的预训练模型,然后将这个模型部署到整机上,这台整机就能完成我们刚才所提到的那些场景化任务了。
整个体验就像培训一位新员工。当这样的产品形态逐渐成熟之后,下游的应用一定会形成一个巨大的生态。在这个生态中,我们星海图始终坚持,自己既是开发者,也致力于赋能其他开发者,共同推动。所以,我们在业务上一直采取「To B, To D」的模式:面向企业(To Business)客户,我们提供「整机+智能」的解决方案;面向开发者(To Developer),我们则将内部使用的所有工具链都开放出来。
02
有「正确的本体」,
才能生产「好数据」
要做好这一切,背后所需要的供给,是从电机(motor)、到整机、再到遥操作的整个系统、数据管线,最后到模型这五个层面的全面成熟。只有这五层都准备好了,下游的应用才有可能繁荣起来。回到当下这个时间点,具身智能发展过程中最主要的问题,我们认为还是数据问题。其实许多算法要素已经具备,而「算法+数据=模型」,现在最大的瓶颈就在于数据;再往前追溯,根源在于没有一个在「正确本体」上产生的数据。
我们回顾一下 ImageNet 这件事。ImageNet 的出现已经是十几年前了,正是因为计算机视觉领域有了 ImageNet 这样大规模、高质量的数据集,才催生了后续我们看到的 AlexNet、VGG 等一系列代表性工作,也开启了深度学习的第一次崛起。
我觉得,这个过程给整个业界带来的最大经验(lesson learn)就是:要想有好的算法和模型,前提是要有好的数据。先有高质量数据,再有高质量模型。这一点,无论是大语言模型还是自动驾驶领域,我们都看到了类似的规律。而具身智能领域,我们看到一个特殊之处,那就是它所需要的数据并不是天然存在的。
具身智能发展所需的数据,不是互联网上的图片、文字、视频这类相对低质量的数据,而是更需要「本体与物理世界交互」的数据,比如操作一个物体、开门、关门、抓取、放置等。这就像一个婴儿出生后,通过与物理世界不断地交互、摸索,逐渐积累经验,在这个过程中积累下来的,才是我们所说的具身智能需要的高质量数据。而要做到这一点,就需要一个标准的硬件,所以我们强调,首先要有一个「正确的本体」,一个标准的本体。
只有在这个本体之上,我们才能去积累与物理世界交互的数据,然后定义任务、定义基准(Benchmark),后续模型的发展才能进入一个相对高速的时期。我们就是遵循着这样的思路,从创业之初,着手去定义我们的产品。因为我们的重点是做双臂操作,在具身智能领域,像宇树科技可能更侧重于双足的运动控制和全身运动控制,而我们则聚焦于让机器人能「干活」,也就是双臂操作。

在双臂操作领域,我们定义本体和整机时,一个很核心的理念就是「智能定义本体」。
那么,双臂操作究竟需要什么样的本体呢?可以给大家举一些例子,这里面其实有很多从智能本身出发,对硬件提出的需求。比如,我们的双臂系统采用的是低减速比电机和行星减速器,这与传统采用谐波减速器的机械臂系统有很大区别。我们的设计更能满足像人一样的高动态性能,更符合模仿学习的需求。
在双臂系统上,我们追求低减速比、高动态、大负载。很多时候,为了让算法达到更好的效果,我们甚至需要直接修改底层的驱动(FOC)层。在躯干部分,我们则采用了高减速比的电机,并且都带有抱闸。因为我们观察到,在作业过程中,一旦发生紧急掉电等情况,双足机器人可能会直接瘫倒在地,这种情况是我们不希望发生的。所以,我们躯干的四个电机都采用了高减速比设计,使其本身就具备较好的支撑性,同时还配有抱闸,确保在紧急断电时机器人不会倒下,而是能撑在原地。
还是机器人的底盘部分。人类双腿有一个很重要的作用,就是能够全向移动。比如,我横着跨一步,或者斜着往前走一步,都无需转身。这种跨步横移、全向移动的能力,对于上半身的操作而言至关重要。反观传统的轮式底盘,比如 AGV,大多采用两轮差速驱动,需要先转身,再前进一步,然后再转回来,这整个过程与双臂操作的配合是脱节的。因此,我们首创了六电机、三舵轮的全向移动底盘技术。
这就是我们围绕双臂操作的智能需求,重新去定义的整机本体。现在已经有了 R1、R1 Pro 和 R1 Lite 三款产品,特别是 R1 Lite 是我们和 Physical Intelligence 团队联合定义的,他们也在我们平台上开发了 Π-0.5 模型。
我再强调下刚才的观点:要想有好的数据,必须先有正确的本体。
03
要先实现对象和动作泛化,
场景和本体泛化当前没那么重要
有了本体之后,我们到底需要什么样的数据?现在很多具身智能领域得公司在获取数据时,第一反应是去建一个自采场。但我们认为,预训练所需要的是开放场景下的真实数据。因此,我们没有大规模地去构建采集场,而是选择直接进入真实世界环境。
目前,我们有几十台机器人,部署在酒店、公园、食堂、商场等真实场景中采集数据。要做好这件事并不容易,因为它涉及到大量的工具、数据生产运营和工艺问题。我们是把数据采集当作一项生产活动来看待的。
既然是生产活动,如何完成一次遥操作?这里面涉及工艺问题,就像如何完成一次装配、组装一个零部件一样,有许多工艺细节需要优化。工艺问题解决之后,就是如何运营整个团队,以及需要什么样的工具链来支撑我们的数据生产活动。
到今年第三季度,我们将累计获得一万小时、由我们的本体与物理世界交互产生的数据。这些数据覆盖的操作对象将超过 1000 个,任务数超过 300 个,这些构成了我们进行具身智能基础模型预训练最重要的数据基础。并且,所有的数据都将围绕着两个在我们看来是「正确」的本体 R1 Pro 和 R1 Lite 来采集,我们也会有步骤地将这些数据释放并开源给整个社区。
有了本体和数据之后,就是智能的部分了。在基础模型训练方面,我们坚持两个核心原则:一是端到端,二是真机数据为主。
先解释这「两个端」分别是什么:一端是视觉(Vision)和指令输入(Language),这个指令可以是自然语言,也可以是结构化的编码指令;另一端是 Action,也就是机器人最终的动作输出。我们希望模型是基于这种完整闭环的输入输出来训练的。整体的训练架构,其实和我们看到的其他领域的基础模型有一些相似——也是「预训练 + 后训练」的结构。

特别解释一下,对于具身智能而言,预训练到底是在做什么?预训练是在解决「本体与物理世界交互的基本法则」这个问题。打个比方,这更像是一个婴儿从出生到三五岁,再到上小学的这个过程。他不断地与物理世界接触、碰撞、摸索,学习如何与世界交互,如何支配自己的身体。这就是预训练。
而后训练,则更像是在一个特定的岗位上,去执行特定的任务。这就是我们理解的,具身智能中预训练和后训练之间的区别与关系。
具体到预训练的模型结构,我们采用的是一个「快慢结合」的模型结构,慢的部分我们叫做「慢思考」。这种「快慢结构」是由我们星海图的联合创始人赵行博士在自动驾驶驾驶领域首创的,后来这一结构也被用在具身智能领域。
「慢思考」主要负责进行逻辑层面的思考、任务拆解以及与人交互,这部分工作更多地可以由多模态大语言模型(VLM)来完成。比如,谷歌发布的 Gemini Robotics 模型,就是在 VLM 和「慢思考」领域一项非常重要的工作。
「快执行」这一部分,是 VLA 或具身智能公司目前真正需要聚焦解决的问题。它相当于一个实时的执行闭环、反馈控制以及感知识别等,这些功能都被整合在「快执行」模型中。「快执行」模型的参数量一般在 10 亿量级,而慢思考的 VLM 的参数量级可能是百亿甚至更大。也正是因为这样的模型架构,在终端部署时,会出现云、厂、端协同工作的问题,同时也存在很多工程优化方面的问题。
后训练方面,更多是围绕特定任务。比如,「拿起一个杯子倒一杯水」。围绕这样的任务,我们可能会收集 100 到 200 条数据,每一条数据就是对这个任务的一次完整执行。
经过这一系列的预训练和后训练后,我们期望看到的效果是:在垂直场景的简单任务上实现零样本泛化,在复杂任务上实现少样本泛化。这里的「少样本」,我们定义为完成新任务所需要的增量数据条数,大概在 100 条这个量级。这就是我们看到的,具身智能基础模型在第一阶段会呈现出的一个范式。
预训练到底是怎么做的,给大家展示一些案例。预训练并不局限于特定的任务。我们现在的做法是,当机器人到达一个新场景后,我们会观察人类在这个场景里会做什么,甚至利用大语言模型去定义各种各样的任务。有了这些任务之后,组织我们的数据生产团队,通过遥操作去采集数据。比如,清理桌面、整理台面,甚至把一件衣服挂到柜子里。下图右下角这个是在开一扇窗户。此外,还包括拿取和放置物品、给一个假人戴上毛线帽、打开冰箱门并放入东西,甚至使用一些工具来完成工作等等。
这就是我们所说的预训练阶段,本质就是让本体(整机)在尽可能多的场景中,围绕尽可能多的任务,与物理世界进行交互、理解和学习。在这个阶段,我们需要的数据量级是几千到上万小时的交互数据。
最后,我想谈一个非常重要的问题,这也是具身智能在发展过程中,技术与商业逐渐结合的体现。从技术的角度来说,具身智能的「智能」部分,核心是要解决泛化问题。那么,具身智能的泛化究竟是什么?归纳为「四个泛化」:对象泛化、动作泛化、场景泛化和本体泛化。这四个泛化组合在一起,构成了具身智能在技术上的终局形态。

「对象泛化」指的是,同样是抓取和放置的动作,我今天抓一个瓶子,明天可以抓一个杯子,后天可能换成一个手机或某个小物件;「动作泛化」指的是,对于同一个杯子,我今天可以把它拿起来放到某个位置,明天我可能要用它倒水,后天我可能需要把杯盖拧开;「场景泛化」是指,同样一个任务,今天我是在这张桌面上完成,明天换了另一张桌面、另一个背景,它依然能够完成;最后是「本体泛化」,即我训练出的模型,不仅可以在一种类型的本体上工作,也可以在另一种类型的本体上运行。这四个方向如果都做到了,具身智能的智能问题就算是被解决了。但从另一个角度,即从商业和产品价值的角度来看,在当前阶段,最有价值的是实现对象泛化和动作泛化。
为什么场景泛化和本体泛化在技术上很重要,但在商业上却可能没那么重要?因为当我们审视具身智能真正的工作场景时,会发现有相当比例的场景是「工站式」的,即在某种相对固定的工位或场景里,提供序列化的工作和服务。在这种情况下,场景泛化的挑战性远没有自动驾驶那么强。自动驾驶的车辆需要在马路上到处跑,场景泛化的需求和难度都要大得多。
而本体泛化,正如我刚才所说,具身智能的产品形态是「整机+智能」,而不是纯模型。既然产品形态是「整机+智能」,那么本体泛化在其发展的第一个阶段,商业上的重要性没那么高。所以我认为,在当前阶段,具身智能应优先解决对象泛化和动作泛化。这两个问题一旦解决,就有相当比例的应用场景可以被开发出来,其商业价值也能够得以释放。
04
市场回归理性,
商业闭环的核心在于开发者
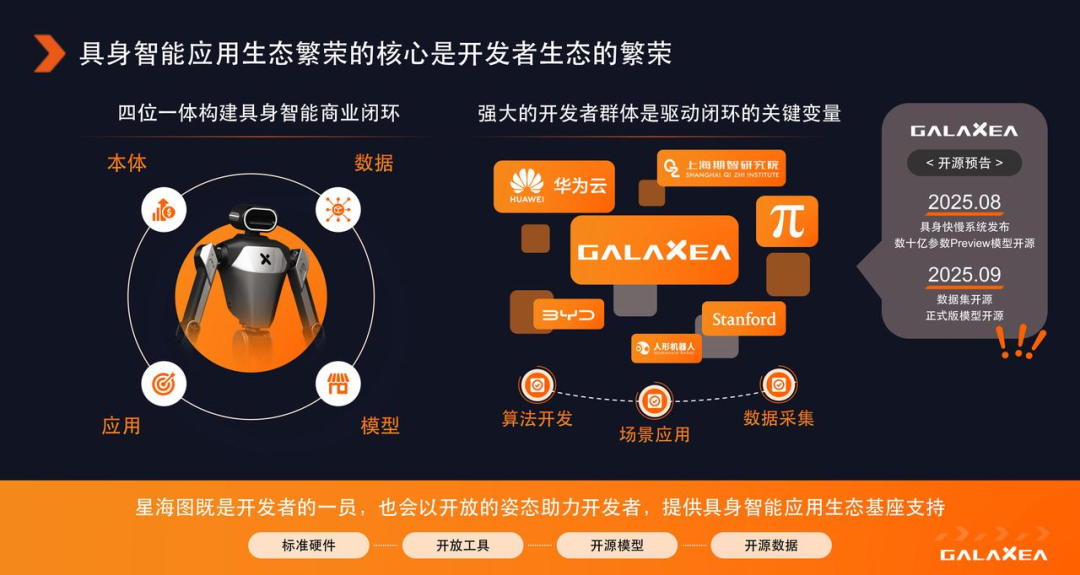
最后一部分,谈谈具身智能的应用和商业化的问题。在我们公司内部,特别重视开发者群体,具身智能商业闭环的核心变量在于开发者群体。
背后的逻辑是,具身智能领域要繁荣,前提一定是应用繁荣,因为应用才能创造价值。而应用繁荣的前提,是有一群充满活力、非常聪明的开发者在创造各种各样的应用。在这个过程中,开发者们需要支持和帮助。我们自己走过这条路,深切感受到具身智能的链条非常长,从供应链、电机制造、整机、遥操作到数据等等,把这些前期工作都做完,我们才能谈论做模型、做应用。但我们不能要求每一位开发者都从头把这些工作完整地做一遍。所以,我们的一个理念是:星海图自己是开发者,我们面向场景去做应用;同时,我们也尽可能地将我们的工具和整机提供出来,帮助全球的开发者与我们一起,共同把这件事做成。
星海图目前在全球有 50 多个客户和合作伙伴,我们正逐渐构建一个集本体、数据、模型、应用于一体的商业循环。
在今年 8 月份举办的 WRC(世界机器人大会)上,我们将开源我们的第一个具身基础模型,是我刚才介绍的一整套本体、数据管线和训练技术打造出来的模型产品。接着 9 月份,在 CoRL(Conference on Robot Learning)上,我们也将进一步开放我们的数据集与完整的训练模型。这两次重要的开源发布,我们希望能够对具身智能的开发应用起到激活的作用。
具身智能现在已经走到了上半场的结尾,我们即将迎来下半场。下半场一定是「应用为王」。
2026 年将是具身智能应用的「元年」。
从供给侧来看,机器人本体正在逐渐成熟和稳定。其次,模型开始具备初步的泛化能力。这里有几个定量的指标,首先是精度,它能完成什么精度的动作?目前还无法达到毫米级,但厘米级的操作精度是可以实现的;其次是速度,大约能达到人类执行速度的 70%到 80%;最后是泛化性,我们评价泛化性的指标是「学习一个新任务需要多少样本」,现在的水平大概在百条这个量级。
当这三个指标构成的智能供给形成之后,也就是基础模型成熟后,下游的应用将呈现出爆发式增长的状态。同时,还有一个关键因素,具身智能的开发者群体正在全球范围内快速增长。
从需求侧看,过去两年基本上是全民探索具身智能可用场景的阶段。大大小小的企业,所有潜在的用人单位,都在思考如何用具身智能来优化自己的工作流程。许多应用场景正逐渐变得清晰。同时,整个市场的预期也回归到了一个比较理性的状态。可能两年前,当特斯拉刚发布一些人形机器人的演示视频时,大家想的是人形机器人马上就要进入工厂,把所有工人都替换掉。但现在我们看到,大家回归了理性,更多地是着眼于一些局部环节,先从工站式的、以及面向人的服务型环节入手,先把商业模型「跑通」,再逐渐走向规模化量产和应用。
基于以上判断,我认为,2026 年将是具身智能的下半场,而下半场的核心就是应用。应用的供需两侧都在走向成熟。

(文:Founder Park)