
目前,大模型LLMs能胜任知识问答、代码辅助等多种任务,但传统模型大多只能输出文本,无法直接生成自然语音,这让人机音频交互不够顺畅。
要知道,人类交流和感知环境可不只是靠文字,语音里藏着音色、情感、语调等丰富信息,其他音频也包含着现实场景的关键信息。所以,能根据语音或音频输入直接回应的音频语言模型就很重要,也是迈向AGI的关键一步。
所以,Step-Audio团队开源了一个端到端的语音大模型Step-Audio-AQAA,不需要先把语音转成文字再生成回答,而是直接听懂音频问题后,就能合成自然流畅的语音回答,像跟人聊天一样直接。

开源地址:https://huggingface.co/stepfun-ai/Step-Audio-AQAA
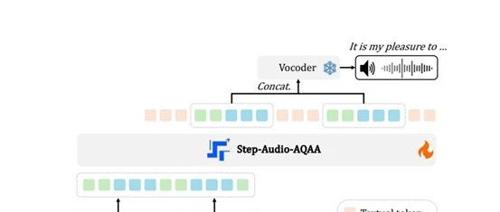
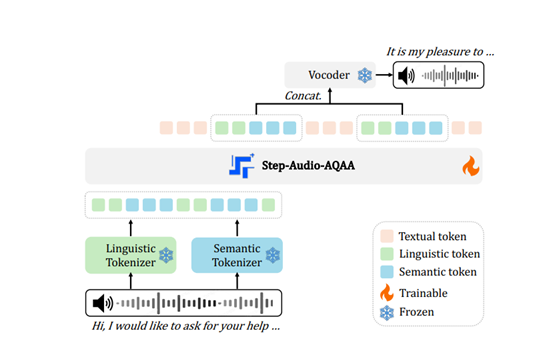
Step-Audio-AQAA的架构采用了一种完全端到端的音频语言建模,由双码本音频标记器、骨干LLM和神经声码器三个核心模块组成。
双码本音频标记器是 Step-Audio-AQAA 的前端模块,其作用是将输入的音频信号转换为结构化的标记序列。该模块的设计灵感来源于语音信号中丰富的语言和语义信息。为了更好地捕捉这些信息,Step-Audio-AQAA 引入了两个不同的标记器:语言标记器和语义标记器。语言标记器专注于提取语音的结构化、高层次特征,例如音素和语言属性,这些特征对于理解语音的语义内容至关重要。
它利用 Paraformer 编码器的输出,以 16.7 赫兹的速率将语音信号量化为离散的标记,码本大小为 1024。这种高频率的量化能够确保语音的细节得以保留,同时为后续的处理提供丰富的语言信息。
与此同时,语义标记器则侧重于捕捉语音的粗粒度声学特征。这些特征虽然不像语言标记那样直接关联到具体的语言内容,但它们能够提供语音的情感、语调等副语言信息,这对于生成自然、富有表现力的语音输出至关重要。语义标记器的设计参考了 CosyVoice 1.0,它以 25 赫兹的速率运行,码本大小为 4096。这种较高的采样率和较大的码本使得语义标记器能够捕捉到更细微的声学细节,从而为模型提供更丰富的上下文信息。
这两个标记器生成的标记并非独立存在,而是相互参照的。研究团队发现,当使用双码本进行训练时,语义标记和语言标记的下一个标记预测困惑度相比单码本训练时有所降低。这表明双码本的设计能够更好地捕捉语音信号中的复杂信息,并且能够提高模型对语音的理解能力。
在双码本音频标记器将音频信号转换为标记序列之后,这些标记序列会被送入骨LLM。Step-Audio-AQAA 的骨干LLM是一个预训练的 1300 亿参数多模态 LLM,名为 Step-Omni。Step-Omni的预训练数据涵盖了文本、语音和图像三种模态,这种多模态的预训练方式使得模型能够同时处理多种类型的数据,并且能够学习到不同模态之间的关联。在 Step-Audio-AQAA 的架构中,Step-Omni 的文本和语音能力被充分利用,而图像能力则未被涉及。
Step-Omni采用了仅解码器架构,这种架构的设计使得模型能够高效地处理序列数据。在处理来自双码本音频标记器的标记序列时,Step-Omni 首先将双码本音频标记使用合并词汇表进行嵌入。这种嵌入方式能够将语言标记和语义标记融合到一个统一的向量空间中,从而使得模型能够同时处理这两种标记。
随后,嵌入后的标记序列会经过多个 Transformer 块进行进一步的处理。每个 Transformer 块都包含一个输入 RMSNorm 层、一个分组查询注意力模块、一个后注意力 RMSNorm 层和一个前馈层。这些模块共同协作,能够对输入的标记序列进行深度的语义理解和特征提取。
最后,由骨干 LLM 生成的音频标记序列会被送入神经声码器模块。神经声码器的作用是将这些离散的音频标记合成为自然、高质量的语音波形。该声码器的设计灵感来源于 CosyVoice 1.0 中引入的最优传输条件流匹配模型,它采用了 U-Net 架构,这种架构在图像处理领域已经被证明是非常有效的。在神经声码器中,U-Net 架构的基本模块集成了 ResNet-1D 层和 Transformer 块,这些模块能够高效地提取音频标记中的特征,并将其转换为连续的语音波形。
(文:AIGC开放社区)