
开源端到端语音大模型:直接从原始音频输入,生成语音输出
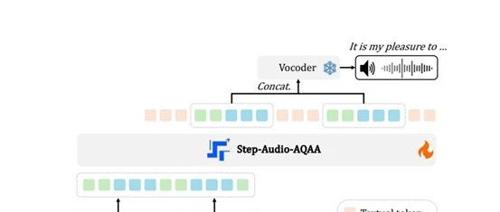
专注于大语言模型在多任务应用的研究及AIGC开发者生态建设。Step-Audio团队开源了端到端语音大模型Step-Audio-AQAA,能够直接生成自然流畅的音频回答。
专注于大语言模型在多任务应用的研究及AIGC开发者生态建设。Step-Audio团队开源了端到端语音大模型Step-Audio-AQAA,能够直接生成自然流畅的音频回答。

4 月 18-19 日,由 CSDN&Boolan 联合举办的「2025 全球机器学习技术大会」将在上海虹桥西郊庄园丽笙大酒店隆重举行,云集多位重量级嘉宾分享前沿议题。段楠博士将详解多模态大模型进展,并深入剖析 Step-Video-T2V 和 Step-Audio 模型的最新成果和挑战,为参会者提供宝贵见解。

Step-Audio是首个支持多语言对话、情感表达和方言的开源智能语音交互框架;Frames of Mind项目通过思维链可视化思考过程;DragAnything实现对象运动控制;《AI Agents for Beginners》课程教授初学者构建AI代理技能;Chat2Geo结合遥感数据进行地理空间分析。