

大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。
基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
因此,奖励模型对大模型能力来说举足轻重:它既需要能够准确进行评判,又需要足够通用化,覆盖多个知识领域,还需要具备灵活的判断能力,可以处理多种输入,并具备足够的可扩展性。
7 月 4 日,国内 AI 科技公司昆仑万维发布了新一代奖励模型 Skywork-Reward-V2 系列,把这项技术的上限再次提升了一截。
Skywork-Reward-V2 系列共包含 8 个基于不同基座模型和不同大小的奖励模型,参数规模从 6 亿到 80 亿不等,它在七大主流奖励模型评测榜单上全部获得了第一。
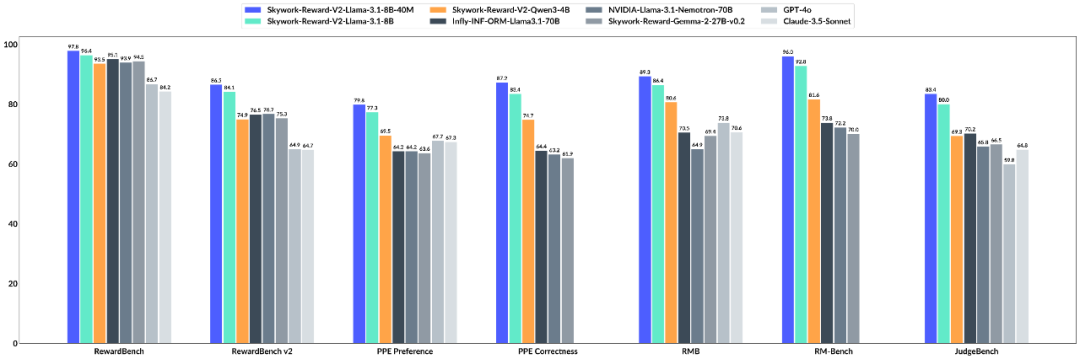
Skywork-Reward-V2 系列模型在主流基准上的成绩。
与此同时,该系列模型展现出了广泛的适用性,它在多个能力维度上表现出色,包括对人类偏好的通用对齐、客观正确性、安全性、风格偏差的抵抗能力,以及 best-of-N 扩展能力等。Skywork-Reward-V2 系列模型目前已经开源。
-
技术报告:https://arxiv.org/abs/2507.01352
-
HuggingFace 地址:https://huggingface.co/collections/Skywork/skywork-reward-v2-685cc86ce5d9c9e4be500c84
-
GitHub 地址:https://github.com/SkyworkAI/Skywork-Reward-V2
其实在去年 9 月,昆仑万维首次开源 Skywork-Reward 系列模型及数据集就获得了 AI 社区的欢迎。过去九个月中,该工作已被开源社区广泛应用于研究与实践,在 Hugging Face 平台上的累计下载量超过 75 万次,并助力多个前沿模型在 RewardBench 等权威评测中取得成绩。

这一次,昆仑万维再次开源的奖励模型,或许会带来更大的关注度。
打造千万级人类偏好数据
想让大模型的输出总是符合人类偏好,并不是一个简单的任务。
由于现实世界任务的复杂性和多样性,奖励模型往往只能作为理想偏好的不完美代理。这种不完美性可能导致模型在针对奖励模型优化时出现过度优化问题 —— 模型可能会过分迎合奖励模型的偏差而偏离真实的人类偏好。
从实际效果来看,当前最先进的开源奖励模型在大多数主流评测基准上表现仍然说不上好。它们经常不能有效捕捉人类偏好中细致而复杂的特征,尤其是在面对多维度、多层次反馈时,其能力尤为有限。此外,许多奖励模型容易在特定的基准任务上表现突出,却难以迁移到新任务或新场景,表现出明显的「过拟合」现象。
尽管已有研究尝试通过优化目标函数、改进模型架构,以及近期兴起的生成式奖励模型(Generative Reward Model)等方法来提升性能,但整体效果仍然十分有限。
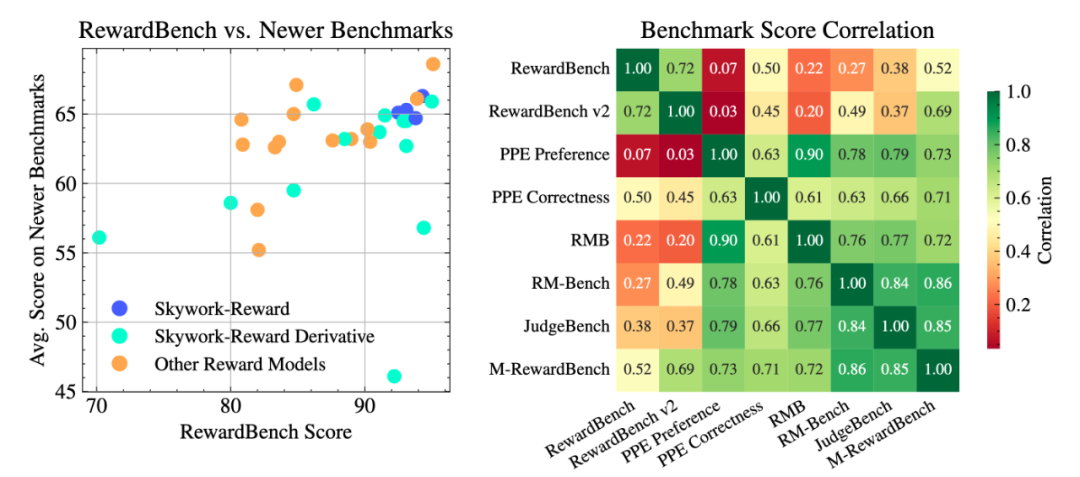
左图:31 个顶尖开源奖励模型在 RewardBench 上的能力对比;右图:分数的相关性 —— 可见很多模型在 RewardBench 上性能提升后,在其他 Benchmark 上成绩却「原地踏步」,这可能意味着过拟合现象。
同时,以 OpenAI 的 o 系列模型和 DeepSeek-R1 为代表的模型推动了「可验证奖励强化学习」(Reinforcement Learning with Verifiable Reward, RLVR)方法的发展,通过字符匹配、系统化单元测试或更复杂的多规则匹配机制,来判断模型生成结果是否满足预设要求。虽然此类方法在特定场景中具备较高的可控性与稳定性,但本质上难以捕捉复杂、细致的人类偏好,因此在优化开放式、主观性较强的任务时存在明显局限。
对此,昆仑万维在数据构建和基础模型两大方向上尝试解决问题。
首先,他们构建了迄今为止规模最大的偏好混合数据集 Skywork-SynPref-40M,总计包含 4000 万对偏好样本。其核心创新在于一条「人机协同、两阶段迭代」的数据甄选流水线。
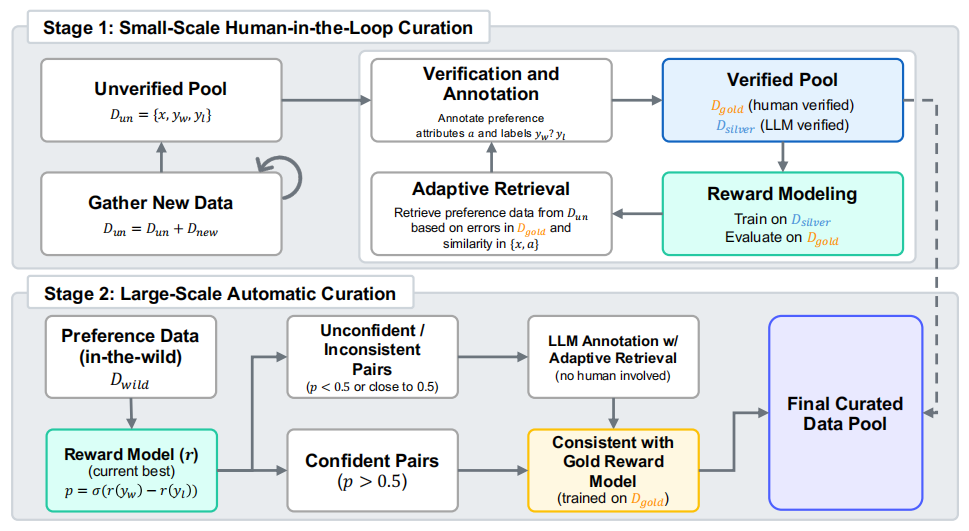
两阶段偏好数据整理流程。
如图所示,这个流程分为两大阶段:
第一阶段,人类引导的小规模高质量偏好构建。此阶段研究人员针对 RLHF 可能存在的「高质量数据缺乏→模型弱→生成数据质量低」恶性循环,独创「金标准锚定质量 + 银标准扩展规模」的双轨机制,一方面利用有限人工精准突破初始瓶颈,另一方面利用模型自身能力实现规模化突破。
具体来说,人工和大模型会分别标注出「黄金」和「白银」偏好数据,奖励模型在白银数据上进行训练,并与黄金数据对比评估其不足之处。接着,系统选择当前奖励模型表现不佳的相似偏好样本进行重新标注,以训练 RM 的下一次迭代,这一过程重复多次。
第二阶段,全自动大规模偏好数据扩展。此阶段不再由人工参与审核,而是让训练完成的奖励模型独挑大梁,通过执行一致性过滤,对数据进行二次筛选。
此时,系统将第一阶段的奖励模型与一个专门基于验证的人类数据训练的「黄金」奖励模型相结合,通过一致性机制来指导数据的选择。由于这一阶段无需人工监督,因此能够扩展到数百万个偏好数据对。
从效果来看,该流程结合了人工验证的质量保证与基于人类偏好的大型语言模型(LLM)的注释,实现了高度可扩展性。
最终,原始的 4000 万样本「瘦身」为 2600 万条精选数据,不仅人工标注负担大大减轻,偏好数据在规模与质量之间也实现了很好的平衡。
突破体量限制:参数差数十倍依然能打
经过人机结合数据训练的 Skywork-Reward-V2 系列模型,实现了超出预期的能力。
相比去年 9 月发布的 Skywork-Reward,工程人员在 Skywork-Reward-V2 系列上基于 Qwen3 和 LLaMA 3 等模型训练了 8 个奖励模型,参数规模覆盖更广。
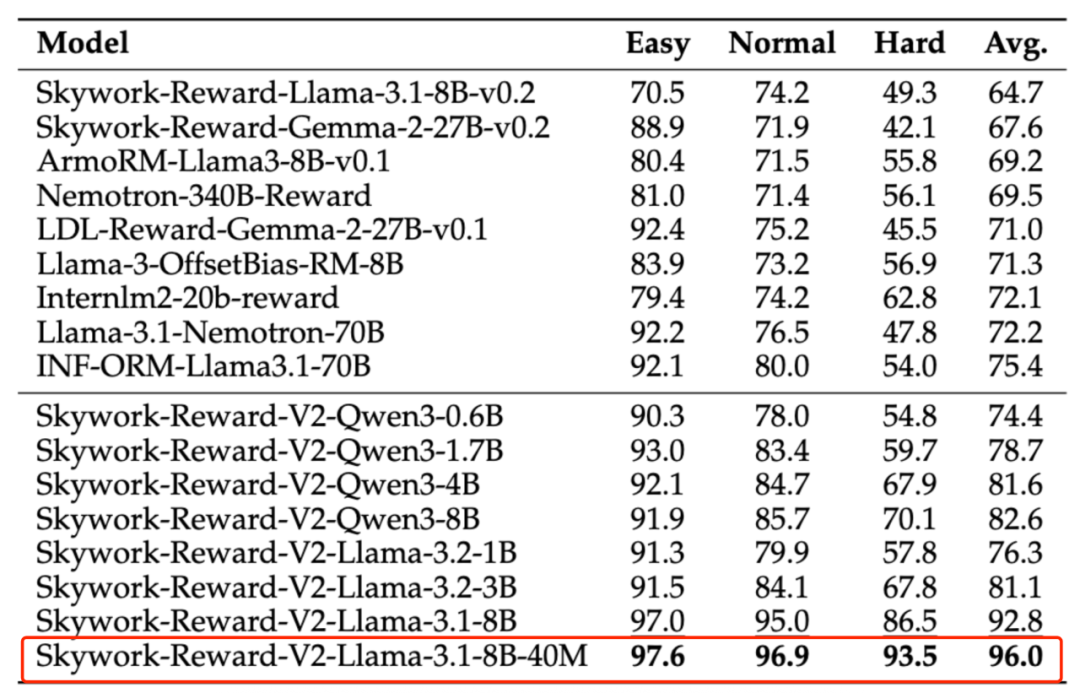
我们从下表可以看到,在 RewardBench v1/v2、PPE Preference & Correctness、RMB、RM-Bench、JudgeBench 等主流奖励模型评估基准上,Skywork-Reward-V2 均创下最佳纪录。
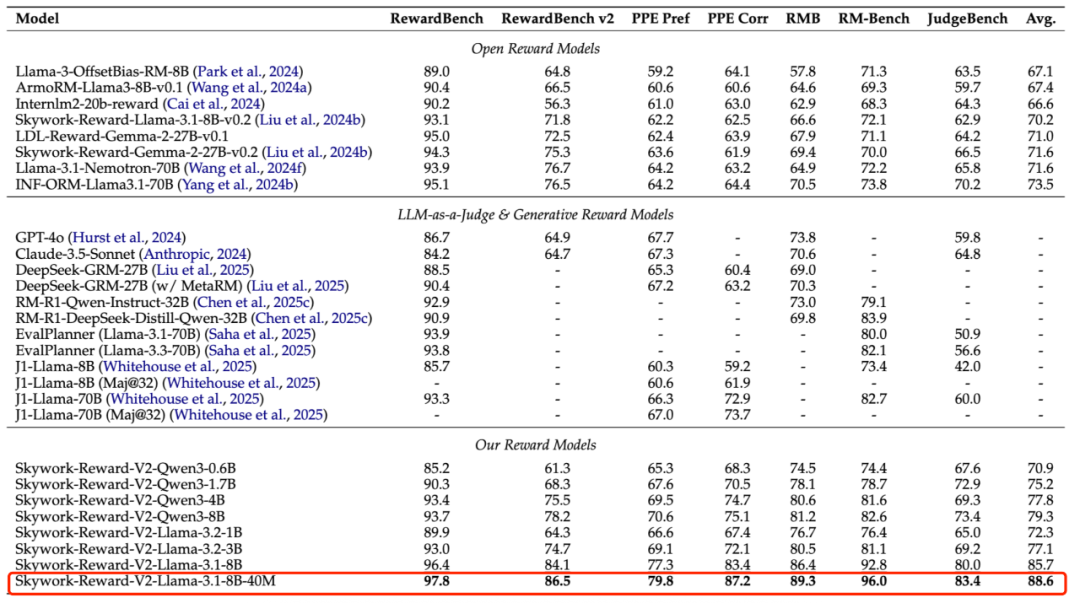
取得 SOTA 成绩的背后,我们可以提炼出以下几点关键发现:
首先,数据质量与丰富度的提升极大地抵消了参数规模的限制,使得奖励模型在特定任务上可以精炼为小型专家模型。
比如在奖励模型评估基准 RewardBench v2 上,Skywork-Reward-V2 在精准遵循指令方面展现出了卓越能力。即使是最小的 Skywork-Reward-V2-Qwen3-0.6B,其大大拉近了与上一代最强模型 Skywork-Reward-Gemma-2-27B-v0.2 的整体差距,参数规模整整相差了 45 倍。
更进一步,Skywork-Reward-V2-Qwen3-1.7B 的平均性能与当前开源奖励模型的 SOTA ——INF-ORM-Llama3.1-70B 相差不大,某些指标实现超越(如 Precise IF、Math)。最大规模的 Skywork-Reward-V2-Llama-3.1-8B 和 Skywork-Reward-V2-Llama-3.1-8B-40M 通过学习纯偏好表示,胜过了强大的闭源模型(Claude-3.7-Sonnet)以及最新的生成式奖励模型,在所有主流基准测试中实现全面超越,成为当前奖励模型新王。
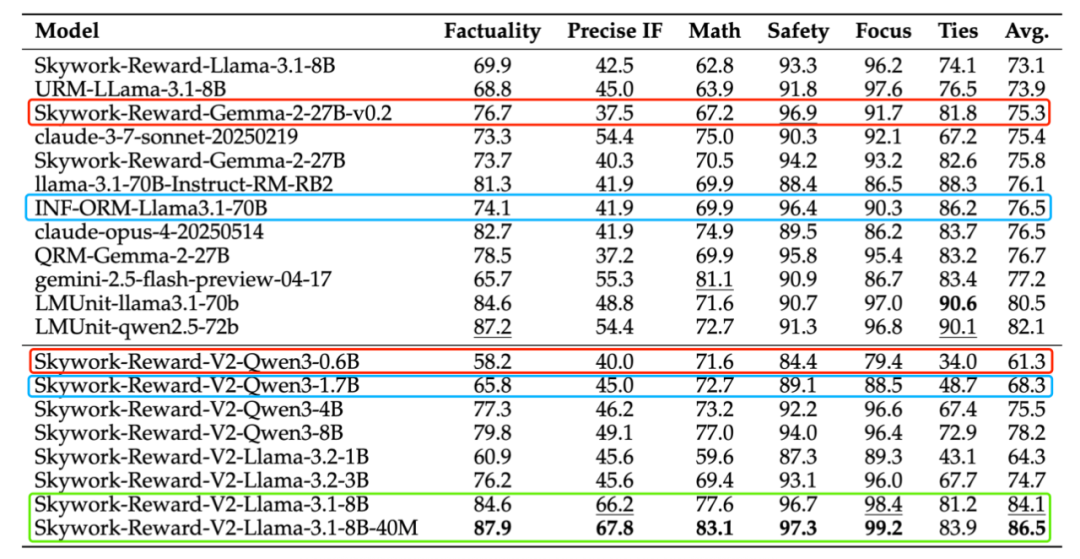
RewardBench v2 基准测试结果。
跑分拉升意味着数据工程策略的作用越来越大,有针对性、高质量的训练数据能支撑起「小打大」;另外,数据驱动 + 结构优化足以与单纯堆参数正面竞争,精工细作的模型训练范式同样值得考虑。
其次,随着对人类价值的结构性建模能力增强,奖励模型开始从「弱监督评分器」走向「强泛化价值建模器」。
在客观正确性评估基准(JudgeBench)上,Skywork-Reward-V2 整体性能虽弱于 OpenAI o 系列等少数专注于推理与编程的闭源模型,但在知识密集型任务上优于所有其他模型,其中 Skywork-Reward-V2-Llama-3.2-3B 的数学表现达到了 o3-mini (high) 同等水平,Skywork-Reward-V2-Llama-3.1-8B 更是完成超越。
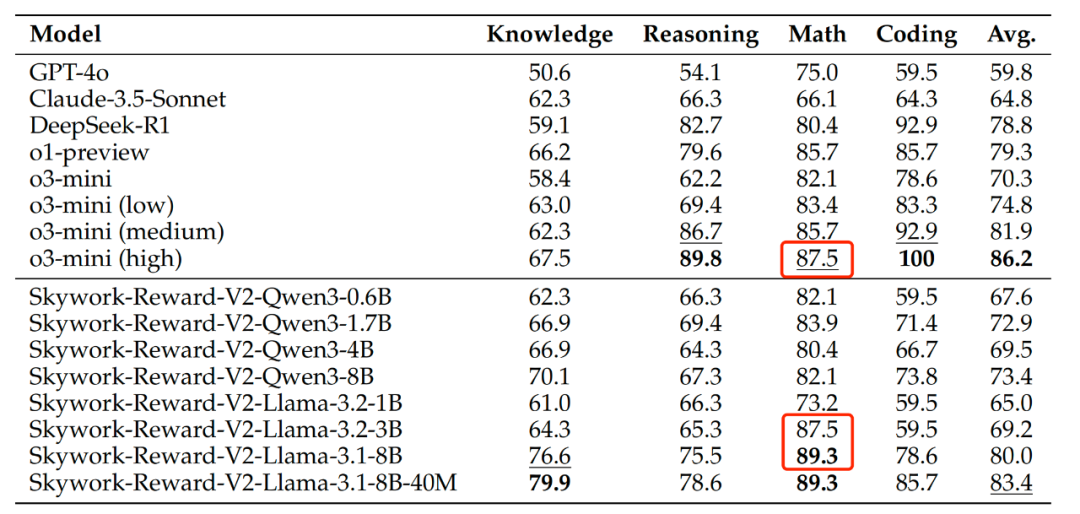
JudgeBench(知识、推理、数学与编程)基准上与顶级 LLM-as-a-Judge 模型(如 GPT-4o)和推理模型(o1、o3 系列)的性能对比。
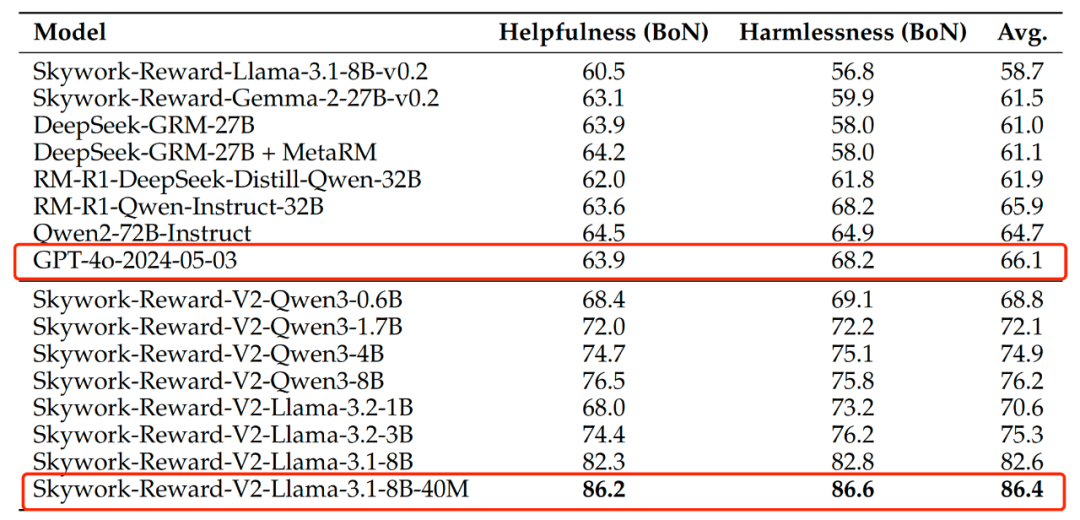
在另一客观正确性评估基准 PPE Correctness 上, Skywork-Reward-V2 全系 8 个模型在有用性(helpfulness)和无害性(harmlessness)指标上均展现出了强大的 BoN(Best-of-N)能力,超越此前 SOTA 模型 GPT-4o,最高领先达 20 分。
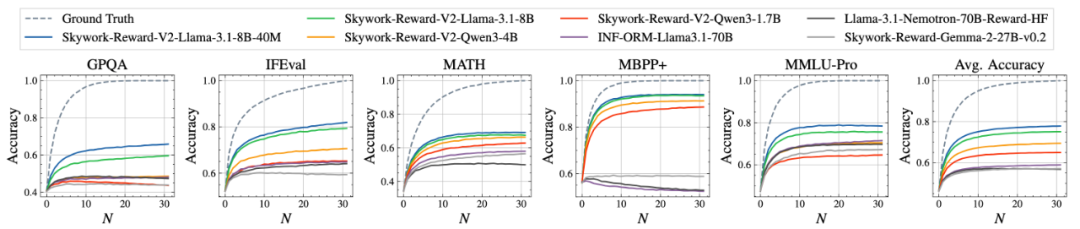
另外,从下面 PPE Correctness 五项高难度任务的 BoN 曲线可以看到,Skywork-Reward-V2 表现出持续正扩展性,均达到 SOTA。
同样在偏见抵抗能力测试(RM-Bench)、复杂指令理解及真实性判断(RewardBench v2)等其他高级能力评估中,Skywork-Reward-V2 取得领先,展现出强大的泛化能力与实用性。
在难度较高、专注评估模型抵抗风格偏差的 RM-Bench 上,Skywork-Reward-V2 取得 SOTA。
最后,在后续多轮迭代训练中,精筛和过滤后的偏好数据能够持续有效地提升奖励模型的整体性能,再次印证 Skywork-SynPref 数据集的规模领先与质量优势,也凸显出「少而精」范式的魔力。
为了验证这一点,工程人员尝试在早期版本的 1600 万条数据子集上进行实验,结果显示(下图),仅使用其中 1.8%(约 29 万条) 的高质量数据训练一个 8B 规模模型,其性能就已超过当前的 70B 级 SOTA 奖励模型。
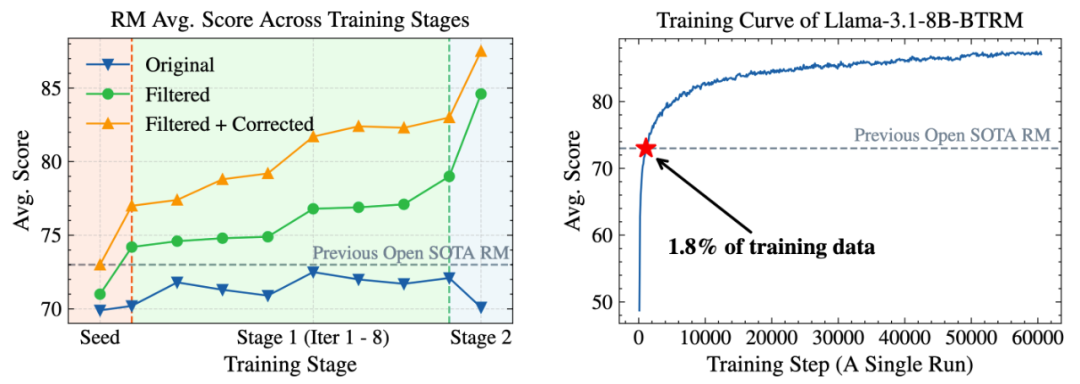
图左展示了整个数据筛选流程(包含原始数据、过滤后数据、过滤后数据 + 校正偏好对三个阶段)中奖励模型得分的变化趋势;图右展示了 Skywork-Reward-V2-Llama-3.1-8B 奖励模型的初始版本(即 Llama-3.1-8B-BTRM)在最终训练轮次的平均得分。
可以预见,随着奖励模型的能力边界不断扩展,未来其将在多维偏好理解、复杂决策评估以及人类价值对齐中承担更核心的角色。
结语
Skywork-Reward-V2 的一系列实证结果输出了这样一种观点:随着数据集构建本身成为一种建模行为,不仅可以提升当前奖励模型的表现,未来也有可能在 RLHF 中引发更多对「数据驱动对齐」技术的演进。
对奖励模型的训练来说,常规的偏好数据往往非常依赖人工标注,不仅成本很高、效率低,有时还会产生噪声。结合大语言模型的自动化标注方法,让人工验证的标签「指导」AI 进行标注,这样可以兼具人类的准确与 AI 的速度,进而实现大规模的偏好数据生成,为大模型能力的提升奠定了基础。
这次发布 Skywork-Reward-V2 时,昆仑万维表示,未来基于人类 + AI 的数据整理方式,还可以激发出大模型的更多潜力。
除了再次开源奖励模型,2025 年初至今,昆仑万维一定程度上也是业内开源 SOTA 大模型最多的 AI 企业之一,其开源包括:
-
软件工程(Software Engineering, SWE)自主代码智能体基座模型「Skywork-SWE」:在开源 32B 模型规模下实现了业界最强的仓库级代码修复能力;
-
空间智能模型「Matrix-Game」:工业界首个开源的 10B + 空间智能大模型;
-
多模态思维链推理模型 「Skywork-R1V」:成功实现强文本推理能力向视觉模态的迁移;
-
视频生成系列模型:SkyReels-V1,以及今年 4 月发布的迭代版 —— 全球首个使用扩散强迫框架的无限时长电影生成模型 SkyReels-V2;
-
数学代码推理模型「Skywork-OR1」:在同等参数规模下实现了业界领先的推理性能,进一步突破了大模型在逻辑理解与复杂任务求解方面的能力瓶颈。
这一系列的开源,势必将加速大模型领域技术迭代的速度。
©
(文:机器之心)