
DeepSeek-TNG-R1T2-Chimera 是由 TNG Technology 使用三种 DeepSeek 父模型组装出的“专家混合体”语言模型,在智能、响应速度和一致性上实现平衡,相比前代提升显著并修复了关键的 token 问题。
-
三亲模型融合:不同于前代只融合两个父模型,R1T2 通过“Assembly of Experts”方法,将 R1-0528、R1 和 V3-0324 三者融合,并引入精细的“脑编辑”技术。
-
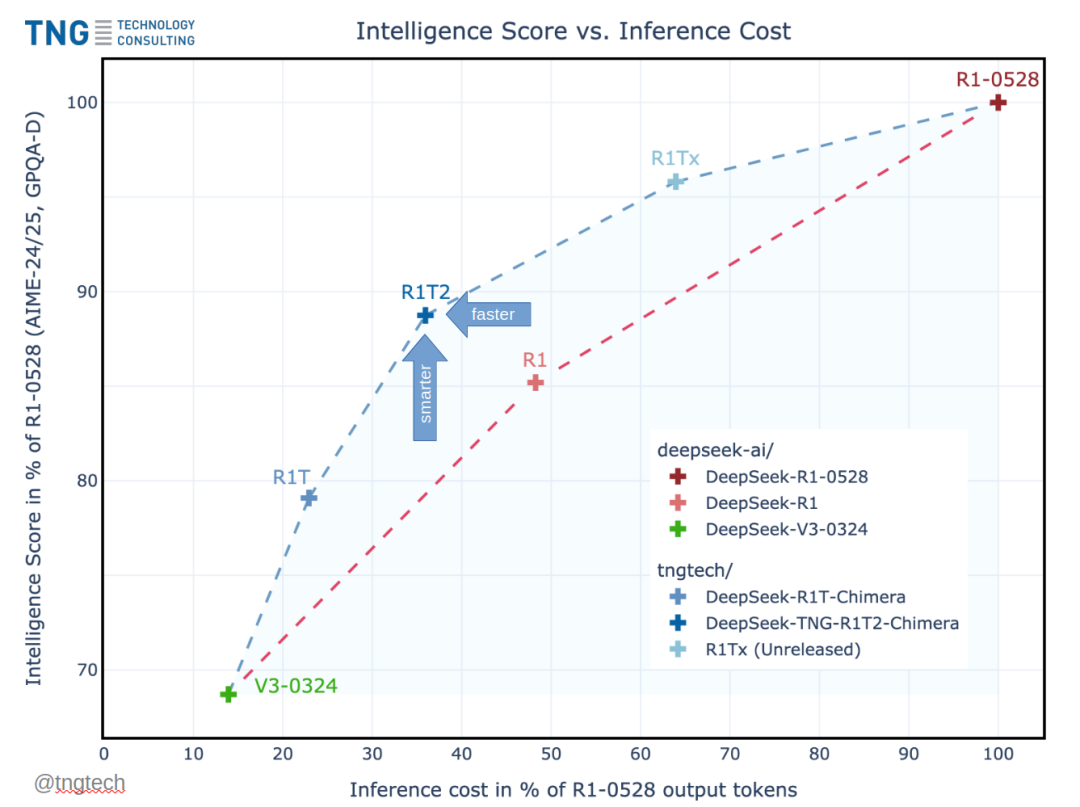
性能平衡的“甜点区”:相较于 R1 和 R1T,R1T2 提供约 20% 更快的推理速度、更高的智能测试成绩(如 AIME-24/25、GPQA-Diamond)以及更好的 token 一致性。
-
推荐场景对比:如果追求推理能力优于 V3 且速度优于 R1-0528,R1T2 被视为 R1 的“几乎通用、可直接替换”的升级;不适合高强度函数调用场景(遗留自 R1 父模型的局限)。
-
智能测试成绩:在 AIME-24 上得分 82.3(显著高于 V3-0324 的 59.4),在 GPQA-Diamond 上也领先于同类。
-
训练与推理细节:推荐温度 0.2、最大 context 长度约 60k token(尽管曾成功处理过 13 万上下文)。
-
法律和合规提示:提醒 EU 用户在 2025 年 8 月 1 日后遵守欧盟 AI 法案,或停止使用。
-
底层架构:基于 DeepSeek-MoE(Mixture of Experts)Transformer 架构,结合定制化的蒸馏、视觉编码和长上下文缓存优化。
-
设计团队背景:由慕尼黑 TNG 团队开发,并公开感谢 DeepSeek 提供开源支持与模型合并方法的先行研究。
参考文献:
[1] https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
知识星球:Dify源码剖析及答疑,Dify扩展系统源码,AI书籍课程|AI报告论文,公众号付费资料。加微信buxingtianxia21进NLP工程化资料群,以及Dify交流群。
(文:NLP工程化)