

嘿,大家好!这里是一个专注于前沿AI和智能体的频道~
过去半年,AI Agent一直有个让人脑壳疼的问题:为什么开源Agent在解决真正复杂的难题时,总是被OpenAI的DeepResearch按在地上摩擦?
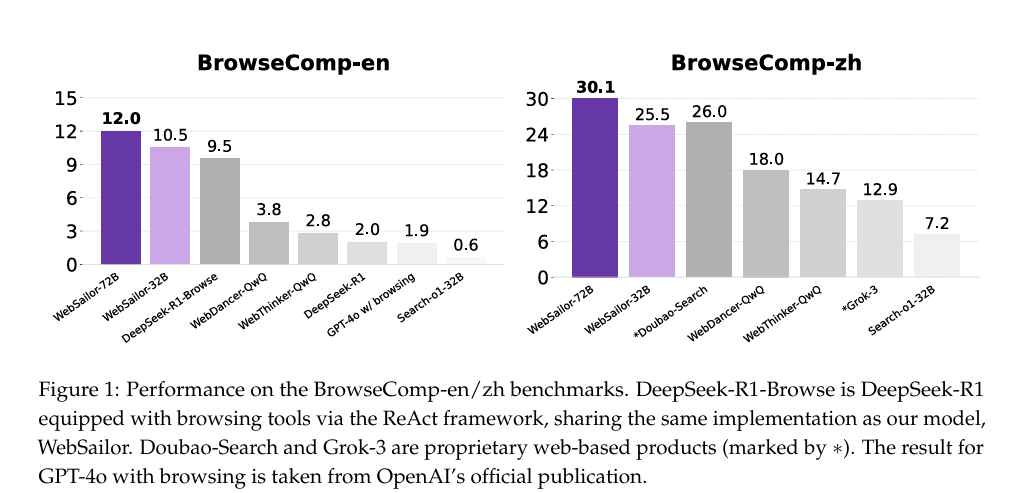
尽管我们看到了WebDancer、R1-Searcher等无数优秀的开源项目,但在OpenAI提出的那个变态难的BrowseComp榜单上,大家的得分基本都是零蛋。这道鸿沟,似乎难以逾越。
昨天,阿里通义开源了他们最新的Web Agent模型——WebSailor。
除了开源模型、代码、论文,它用一套完整且可复现的方法论,告诉了所有人:开源Agent,也能实现超人推理,挑战闭源霸权!
开源Agent的问题
首先,我们得搞清楚,为什么以前的开源Agent不行?
论文指出,问题出在训练数据的难度上。
之前的训练方法,基本都围绕着两类任务:
-
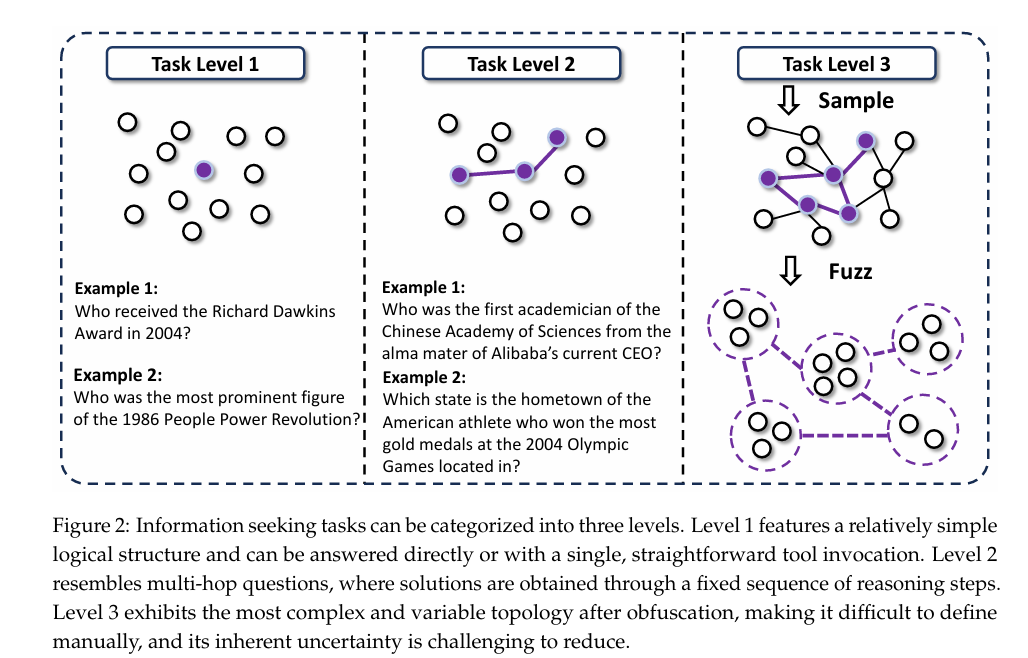
Level 1: 低不确定性任务,比如单次搜索就能找到答案的问题。 -
Level 2: 路径明确的多跳任务,比如“阿里巴巴现任CEO的母校的第一位中科院院士是谁?”。虽然复杂,但推理路径是固定的、线性的。
然而,现实中,很多挑战,属于 Level 3 :极高的不确定性 + 极其复杂的探索路径。
它没有标准答案路径,需要Agent像一个真正的研究员一样,在信息的海洋里不断探索、剪枝、整合、推理。
用Level 1和Level 2的数据去训练模型,然后让它去解决Level 3的问题,这无异于只教了加减法,就让学生去解微积分。结果自然是惨不忍睹。
秘诀一:构造出L3级别的合成数据
那么,如何创造出足够难的Level 3训练数据呢?
WebSailor开源了 SailorFog-QA, 它的生成方式非常巧妙:
-
构建复杂知识图谱:从真实世界的网站出发,通过随机游走的方式,构建出一个包含大量实体和复杂关系的高度互联的知识图谱。这保证了问题的源头是真实的,结构是非线性的。 -
采样+提问:从这个复杂的图中,随机采样出一个子图,然后基于这个子图生成问题和答案。 -
制造难度(关键步骤):在生成问题时,故意对信息进行模糊化处理。这招太绝了。 -
精确的日期,变成 “21世纪初”。 -
清晰的名字,变成 “一个由F开头的人创立的机构”。 -
具体的数值,变成 “市场份额不到1%”。
这种MASK直接把任务的初始不确定性拉满,逼着Agent必须学会比较、推理、综合信息,而不是简单地执行查找。
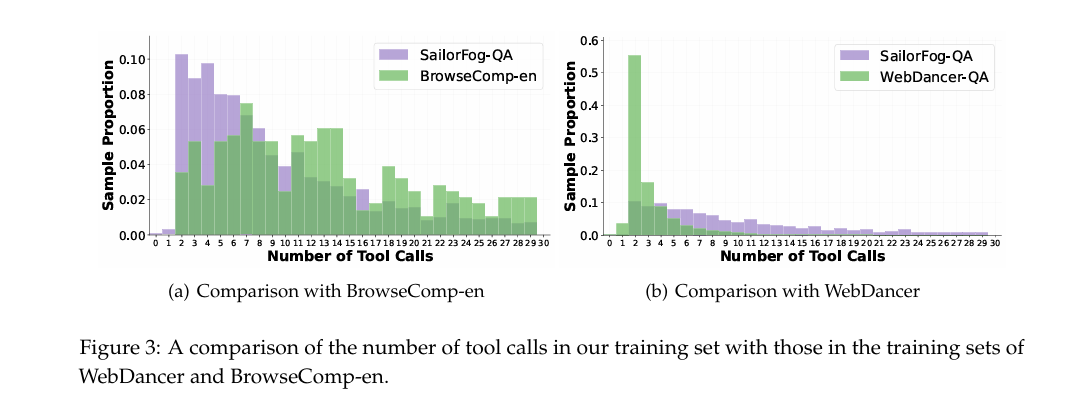
看上图就知道,SailorFog-QA要求的工具调用次数,分布与BrowseComp-en benchmark(橙线)惊人地相似,并且远超其它数据集。用这种高难度的数据喂出来的模型,实战能力自然强悍。
秘诀二:不学废话,只学精华
有了高质量的QA,下一步就是生成解题过程的轨迹,让模型去学习。
传统方法是找一个更强的专家模型(比如QwQ-32B),让它生成完整的思考和动作轨迹,然后让我们的模型去模仿。但这里有个大坑:专家模型通常非常啰嗦!
它们的思考过程充满了冗长、风格化的“废话”。直接学习这些,不仅会污染我们模型的思考风格,限制其灵活性,更致命的是,在需要几十步工具调用的长任务里,这些废话很快就会把上下文窗口(Context)撑爆!
WebSailor的做法堪称教科书级的取其精华,去其糟粕:
-
让专家模型生成完整轨迹,但只保留action-observation序列。这相当于只看大师的操作,不听他的碎碎念。 -
然后,再用另一个强大的指令跟随模型,去为每一步成功的动作反向生成一个简洁、凝练、直指目标的“思考”。
这样得到的训练轨迹,既保留了专家解决问题的核心逻辑,又干净利落,没有废话,非常适合长任务的训练。
秘诀三:先冷启动,再用DUPO精调
最后是训练环节。WebSailor采用了“两步走”策略。
第一步:RFT冷启动。
他们发现,直接上RL(强化学习)效果很差,因为任务太难,奖励太稀疏,模型一开始根本不知道往哪走。所以,需要先用少量(仅2k)经过筛选的高质量SFT数据进行“冷启动”,让模型先掌握基本的工具使用和长链条推理的“骨架”。
第二步:DUPO算法强化。
这是他们提出的一个更高效的RL算法——Duplicating Sampling Policy Optimization (DUPO)。相比之前的DAPO等方法,它最大的优势是快。
在Agent的RL训练中,与环境交互的“rollout”过程非常耗时。DUPO通过一个聪明的技巧——在训练中,优先复制(duplicate)那些表现出多样性(部分rollout成功,部分失败)的样本来填满一个batch,而不是去环境中拉取新样本——极大地提升了训练效率,实现了约2-3倍的加速。
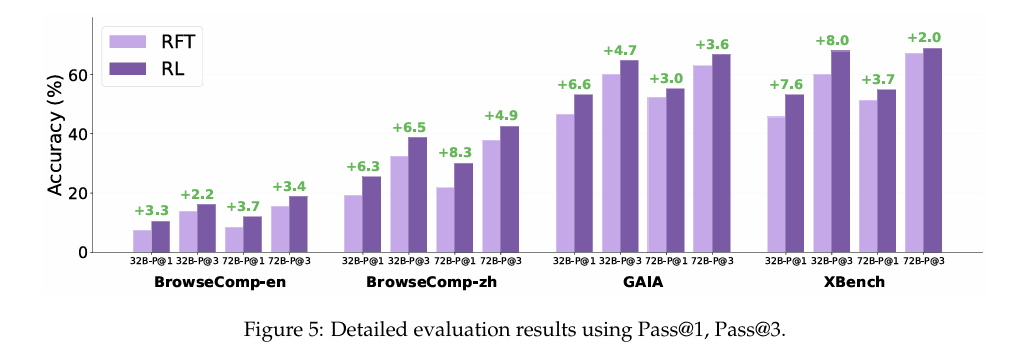
从上图可以看出,RL阶段(绿色部分)对模型的性能,尤其是在BrowseComp这种高难度任务上,带来了巨大的提升。
最后
数据仍然是Agent时代的护城河。
真正的壁垒不在于模型结构,而在于创造高难度、高不确定性训练数据的能力。
随着开源Agent的逐步探索,可以一定程度上降低工程压力。在复杂的Agent任务上,基础模型就能追赶甚至比肩顶级闭源系统。
开源,未来可期!
-
paper: https://arxiv.org/pdf/2507.02592 -
code: https://github.com/Alibaba-NLP/WebAgent -
model:https://huggingface.co/Alibaba-NLP/WebDancer-32B -
data: https://huggingface.co/datasets/callanwu/WebWalkerQA
好了,这就是我今天想分享的内容。如果你对构建AI智能体感兴趣,别忘了点赞、关注噢~
(文:PaperAgent)