

在 AI 模型大战已陷入疲态的当下,月之暗面(Moonshot AI)凭一己之力,再次点燃了全球用户对国产大模型的热情。

Kimi K2 来了,一开源就是万亿参数级。
这次的 Kimi K2,不同于以往卷模型“基础性能”(智商),而是剑走偏锋,开始卷“任务执行”(谁更能干活)。
Kimi 的这步棋,无疑是走对了。
来看看国外用户对 Kimi K2 的评价。
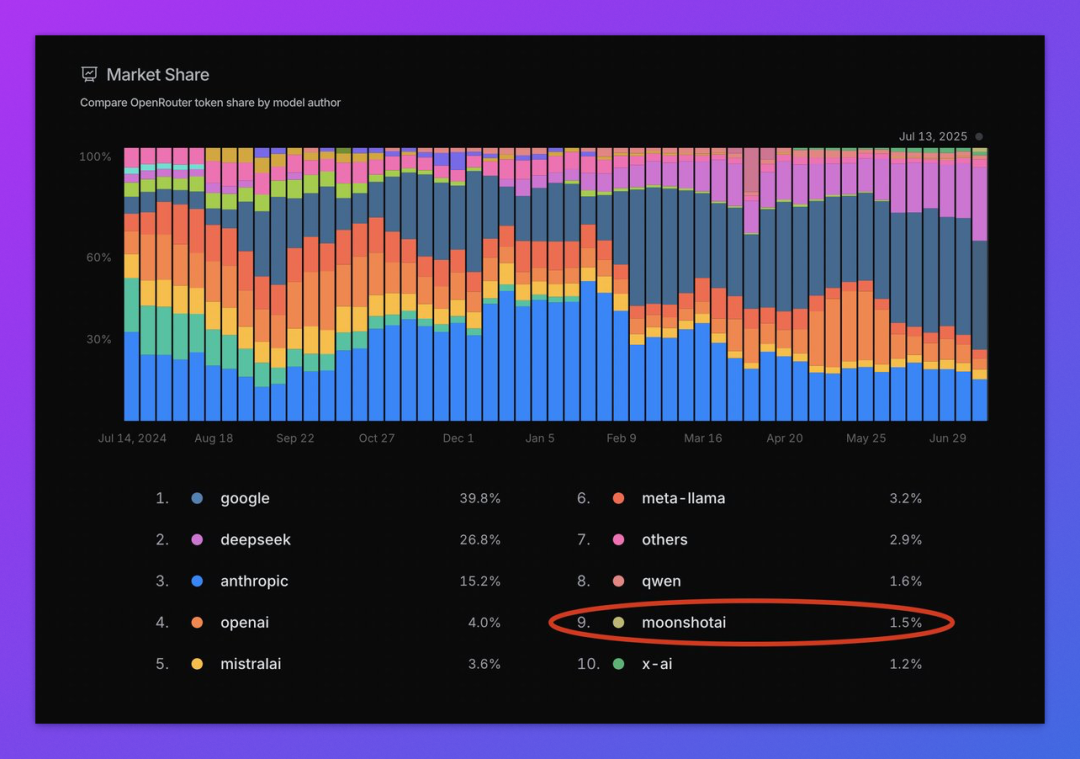
首先是来自大模型市场 OpenRouter 官方的认可:“就在 Kimi K2 推出后短短几天内,Moonshot AI 在 token 市场份额已超过了 xAI。”

OpenRouter 上各个模型 API 使用量是用户对这个模型评价的直接反映。Kimi K2 目前超过 xAI,排在第九名。另外一个国产之光 DeepSeek 排在第二,毕竟,性价比太高了。
再比如下面这位网友的评价:“Kimi K2 是继 Claude 3.5 Sonnet 之后,第一个让我在生产环境里可以放心调用的模型。”

类似的评价还有很多,多到我甚至都怀疑是不是 Kimi 官方雇了“水军”。
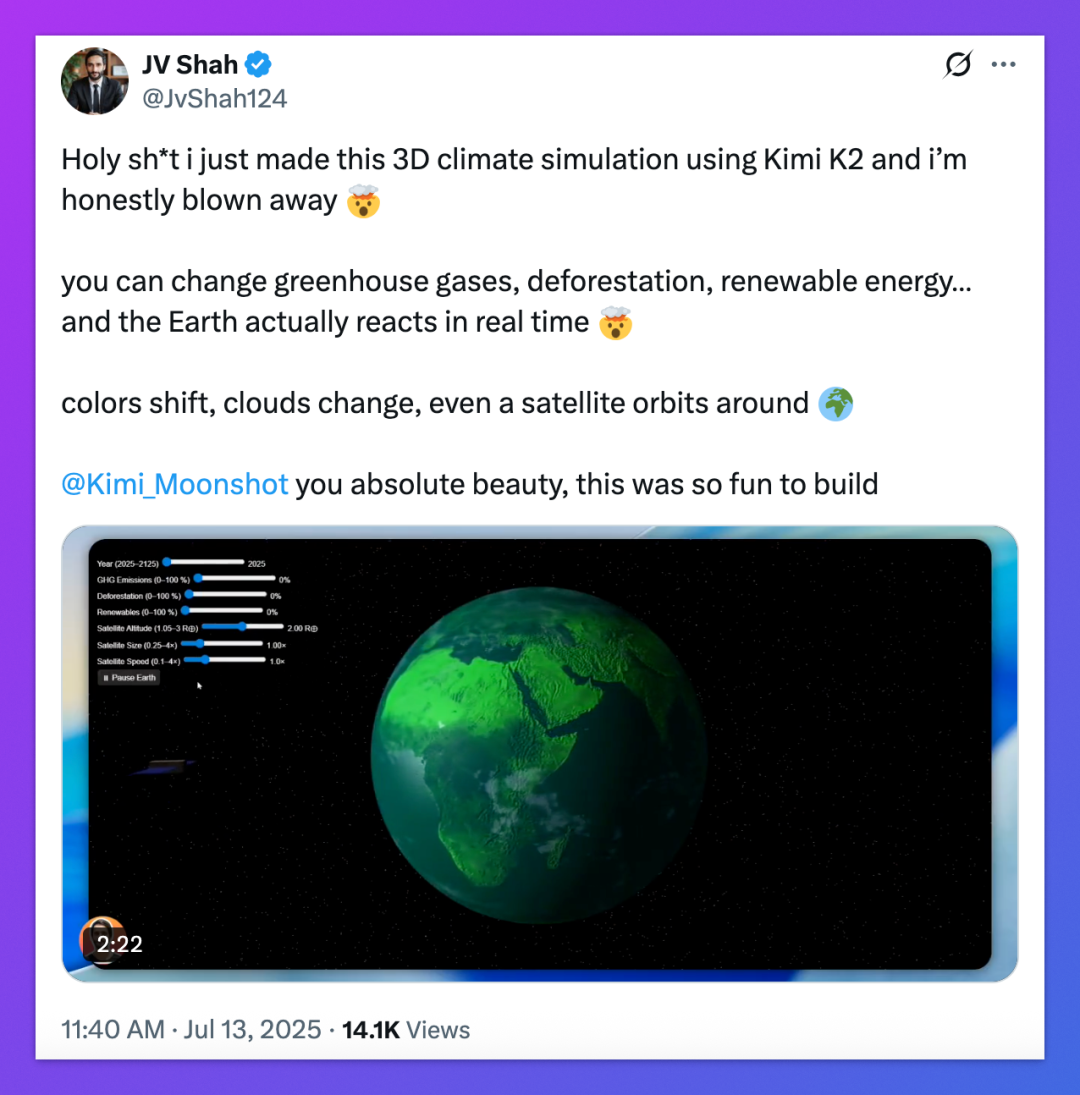
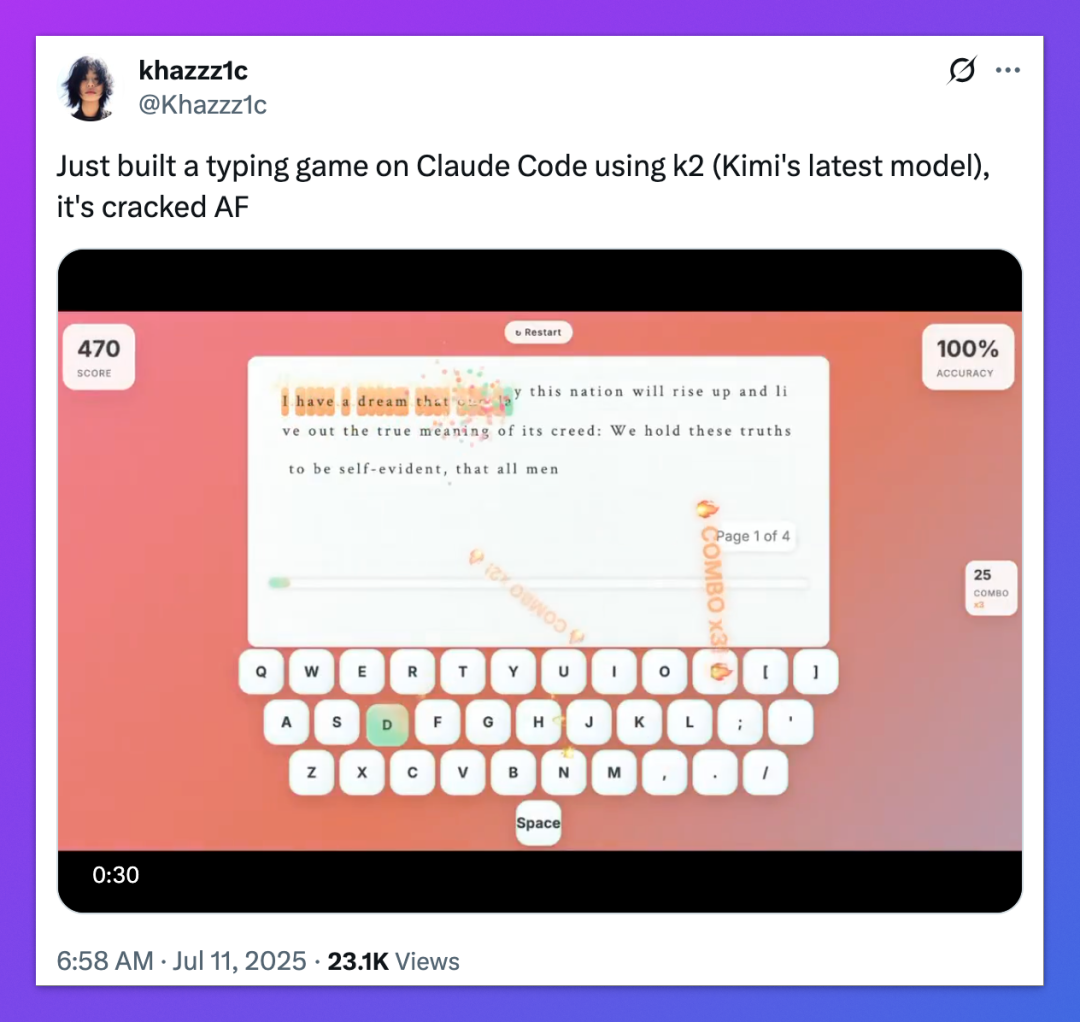
那么,Kimi K2 真的很“行”吗?它到底“强”在哪?
今天就来尝试客观地分析一波。
01|Kimi K2 基本参数
基础参数方面,Kimi K2 最亮眼的无疑是“万亿参数”。
1T(1 万亿)总参数,使用 MoE 架构推理时激活 32B(320 亿)参数,上下文长度 128K tokens。
作为对比,DeepSeek V3 参数总量为 671B(6710 亿),激活参数 37B(370 亿),上下文长度 64K。
不同于“刷榜型大模型”(特指 Llama 4,Grok 4 等模型),Kimi K2 主打“代码生成 + 工具调用 + 数学推理”这些真实生产场景。
所以,月之暗面官方在宣传 Kimi K2 时,用得最多的一个词,就是 Agentic,即自主的、具备代理能力的。

02|Kimi K2 两个版本
Kimi K2 共发布两个版本,分别面向不同的使用场景。
-
Kimi-K2-Base,基础预训练模型。没有经过任何指令微调,保持了原始训练后的通用能力,更适合科研研究、自定义微调或用作下游任务的底座。如果你是开发者或研究人员,想在此基础上继续探索新领域,这个版本是理想选择。
-
Kimi-K2-Instruct,经过指令微调后的通用版本。它已经被优化用于实际应用场景,比如 Agent 工具调用、复杂任务拆解、多轮对话以及代码生成等,是在 Kimi 官网、App 和 API 中默认使用的模型。
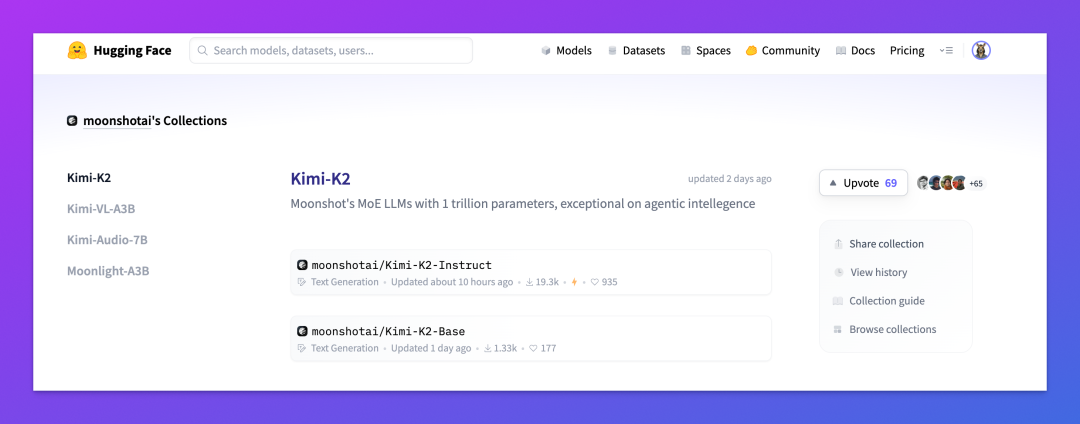
这两个版本都已经开源,可以直接在 Hugging Face 上下载使用,这里附上地址:https://huggingface.co/moonshotai/Kimi-K2-Instruct。
03|非推理模型,脱颖而出
Kimi 官方很实在,特别强调:Kimi K2 是非推理模型(Non-CoT),且暂不支持多模态输入。
下面则是 Kimi 官方放出的 Kimi K2 基准测试对比图。
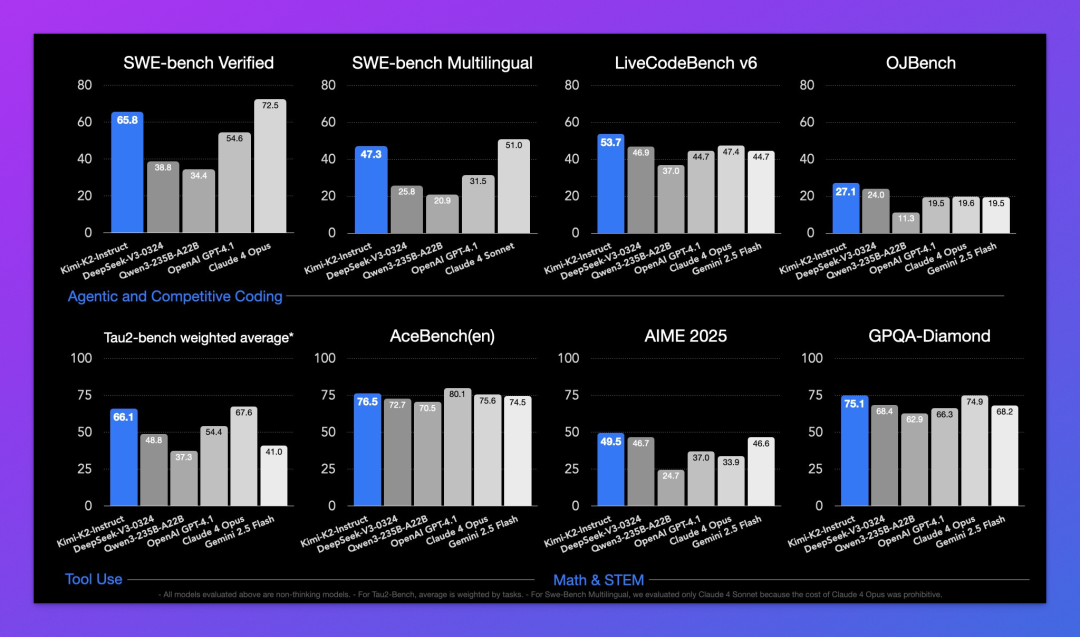
作为一个非推理模型,Kimi K2 肯定是没法和 o3、Gemini 2.5 Pro 这些顶级推理模型比的,这估计也是 Kimi 官方的小心思,在对比图里压根没有出现 o3 和 Gemini 2.5 Pro 的身影。
参与对比的模型包括 DeepSeek-V3、Qwen3-235B、GPT-4.1 以及 Claude 4 系列,Kimi K2 可以说是表现相当亮眼,在这些模型中脱颖而出。
尤其是官方宣传最多的:自主编程(Agentic Coding)和工具调用(Tool Use)。
数学推理方面就不用想太多了,推理模型因为具有思维链机制简直是碾压,毕竟 o3 在 AIME 2025 测试中已接近满分,Kimi K2 则是 49.5%。
04|Kimi K2 怎么用?
Kimi 官方提供了三种方式来体验 Kimi K2。
最简单的方式就是在 Kimi 官网(kimi.com)或 App,直接使用。
但要注意的是,模型不支持多模态,比如图片输入,当前 Kimi 仅支持用 OCR 技术提取图片里的文字内容。
并且,不支持推理模式。
其次是 API。如果你习惯使用 API 调用的方式来体验各个模型,Kimi K2 也都支持。定价每百万输入 tokens 4 元,每百万输出 tokens 16 元,和 DeepSeek-R1 相同,是 DeepSeek-V3 的 2 倍。
当然,OpenRouter 已支持免费的 Kimi K2 模型,用量小更推荐。
最后是自部署。Kimi K2 Base 和 Instruct 模型都是开源的,支持 FP8 权重,可直接从 Hugging Face 下载部署。
虽然总参数是万亿级别,但 32B 的激活参数大大降低了部署门槛。
05|Kimi K2 初体验
目前仅做了几个测试,给我的感觉:有惊喜,有不足。
惊喜来自一道数学题目的测试。
对于一个非推理模型来说,测试数学题稍“严苛”了点,但 Kimi K2 的表现可圈可点。
这是号称史上最难的 1984 年全国卷数学选择最后一题。
Kimi K2 的回答完全正确,包括推理过程。虽然部分推理重复且冗长,但瑕不掩瑜。

不足:以图片格式上传数学题目,Kimi 没有一次能准确识别其中文字的,这应该是 OCR 限制了 Kimi 的发挥,但不支持多模态输入的确是 Kimi K2 的一大短板。
所以上面的测试,我是直接把 Latex 格式的数学题发给了 Kimi。
备注:更全面的测评正在准备中。
结语
从“对话”到“干活”,
Kimi K2是一场方向正确的试探。
在大模型越来越“内卷”的今天,Kimi 并没有继续死磕榜单,而是选择了一条“下沉到底层执行力”的路线。
Kimi K2 没有思维链、不支持多模态、也不是最强的“考试”选手,但不影响它在国外“火出了圈”。
在全球用户被“能用、敢用”体验打动的背后,Kimi 所代表的,可能正是国产大模型正在寻找的那条新路径。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)