

随着大模型从“能看懂”走向“会思考”,视觉语言模型(VLM)在多模态复杂推理上的瓶颈日益凸显。智谱AI最近开源的GLM-4.1V-Thinking系列,首次将“思维链+课程强化学习”引入10B量级VLM,以“小体积、大思考”刷新行业上限。本文以技术视角拆解其原理、功能、性能与落地实践,为开发者与研究者提供一份系统参考。

一、项目概述
GLM-4.1V-Thinking 是智谱AI基于GLM-4V架构推出的开源视觉语言模型家族,主打“思维链推理+课程采样强化学习”,在10B参数规模实现72B模型的推理能力,支持图像、视频、文档等多模态输入,面向教育、内容创作、行业智能等场景。
二、技术原理
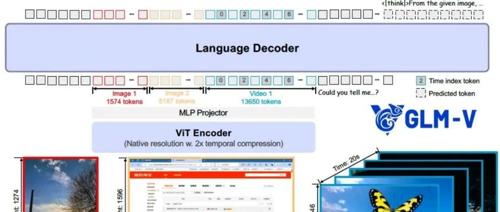
(一)、整体架构
1、视觉编码:AIMv2Huge ViT作为视觉骨干,2D/3D-RoPE支持任意分辨率、任意宽高比及4K高清图。
2、特征对齐:MLP Adapter将视觉token映射到GLM语言模型空间,实现跨模态统一表示。
3、语言解码:GLM-4-9B-0414基座,支持64 k上下文,双语(zh/en)生成。
(二)、训练策略
1、预训练:大规模图文对、学术论文、STEM题库,构建通用视觉语言先验。
2、思维链微调(CoT-SFT):引入长链推理样本,教会模型“先思考后回答”。
3、课程采样强化学习(RLCS):按难度动态采样,减少过拟合,提升跨任务稳定性。
(三)、创新点
1、首次在10B级VLM中引入显式<think>标签,生成可解释推理路径。
2、2D-RoPE+3D-RoPE组合,兼顾空间与时间维度建模。
3、RLCS策略使训练效率提升1.8倍,内存占用降低15%。
三、主要功能
(一)、图像理解
1、通用任务:目标检测、细粒度分类、OCR、图表问答。
2、高阶任务:视觉指代表达、多图一致性判断。
(二)、视频处理
1、时序事件链抽取,支持长视频(≤30 min)关键帧采样。
2、视频描述与问答,可定位事件起止时间戳。
(三)、文档解析
1、多页PDF/PPT语义检索,图表、公式、表格结构化输出。
2、长文档跨页推理,结合图表数据进行问答。
(四)、数学与科学推理
1、多步数学题解:几何证明、代数推导、物理公式计算。
2、实验数据分析:读取实验曲线图并给出结论。
(五)、逻辑与跨模态推理
1、因果推断:图文混合的“如果…那么…”场景。
2、视觉锚定:根据图像细节回答开放域问题。
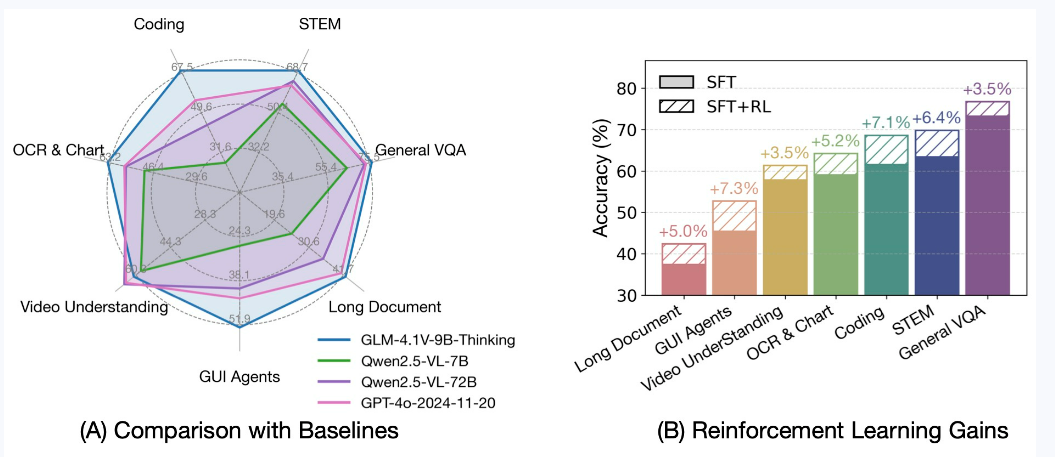
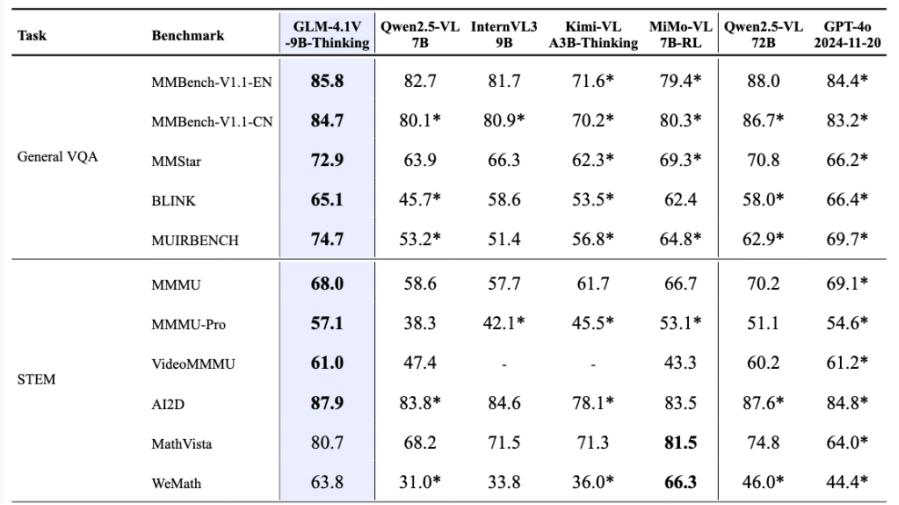
四、性能评测表现
GLM-4.1V-9B-Thinking 在回答准确性、内容丰富度与可解释性方面, 全面超越传统的非推理式视觉模型。在28项评测任务中有23项达到10B级别模型最佳,甚至有18项任务超过8倍参数量的Qwen-2.5-VL-72B。
五、应用场景
(一)、教育辅导
例如,学生在完成作业时,无论是数学、物理等理科作业中遇到的难题,还是语文、英语等文科作业中的阅读理解问题,只需将作业拍照上传,系统就能快速给出步骤化的详细解析。对于包含手写公式的作业,系统能够精准识别公式内容,并进行正确的推导和解答,帮助学生深入理解知识点,掌握解题思路。
(二)、内容创作
例如,商家在推广产品时,只需输入产品图片和相关关键词,系统就能自动生成小红书、亚马逊等平台的多语言营销文案。文案内容不仅能够突出产品的特点和优势,还能根据不同平台的用户喜好和语言风格进行定制,吸引更多的潜在客户,提高产品的销售量。
(三)、智能交互
例如,在客服领域,当用户遇到问题并上传截图、视频等相关资料时,客服机器人能够利用模型对这些资料进行分析,快速定位故障原因,并提供相应的解决方案。
(四)、行业智能
例如,在医疗领域,医生可以将患者的医疗影像(如X光、CT、MRI等)与病历文本进行联合输入,系统能够对影像和文本进行综合分析,辅助医生进行疾病诊断和治疗方案制定。
(五)、娱乐生活
例如,在旅游前,用户可以上传旅游目的地的图片或输入相关关键词,系统能够自动生成详细的旅游攻略,包括景点推荐、美食介绍、交通路线规划等。在旅游过程中,用户可以随时上传当地的风景图片,获取图片中景点的详细信息和历史文化背景,丰富旅游体验。
六、快速使用
(一)、安装依赖
安装transformers
pip install git+https://github.com/huggingface/transformers.git(一)、模型推理
以下是模型推理示例:
from transformers import AutoProcessor, Glm4vForConditionalGenerationimport torchMODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"messages = [{"role": "user","content": [{"type": "image","url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"},{"type": "text","text": "describe this image"}],}]processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)model = Glm4vForConditionalGeneration.from_pretrained(pretrained_model_name_or_path=MODEL_PATH,torch_dtype=torch.bfloat16,device_map="auto",)inputs = processor.apply_chat_template(messages,tokenize=True,add_generation_prompt=True,return_dict=True,return_tensors="pt").to(model.device)generated_ids = model.generate(**inputs, max_new_tokens=8192)output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)print(output_text)
结语
GLM-4.1V-Thinking以10B参数打破“模型越大能力越强”的刻板印象,通过思维链推理与课程强化学习,将视觉语言模型的性价比推向新高度。无论你是研究者、开发者还是行业用户,都能从中找到落地路径。可以访问下方官方地址,动手体验实践!
项目地址
GitHub:https://github.com/THUDM/GLM-4.1V-Thinking
Hugging Face:https://huggingface.co/collections/THUDM/glm-41v-thinking
ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Thinking
技术论文:https://arxiv.org/abs/2507.01006
(文:小兵的AI视界)