

ChatVLA团队 投稿
量子位 | 公众号 QbitAI
还在担心机器人只能机械执行、不会灵活应变?
美的AI研究院和华东师范大学联合提出ChatVLA-2——一个具有开放世界具身推理能力的视觉-语言-动作模型(VLA)模型。
它引入动态混合专家架构,并结合双阶段训练流程,不仅最大程度保留了视觉-语言模型(VLM)的多模态认知和推理能力,还能将推理结果真正转化为可执行的动作。

在真机实验中,研究团队设计了两项任务,重点考察模型继承的核心能力:
-
通过数学匹配游戏评估其数学推理能力,对新算式的识别与推理; -
通过玩具摆放任务测试其空间推理能力,对新物体和指令的理解与执行。
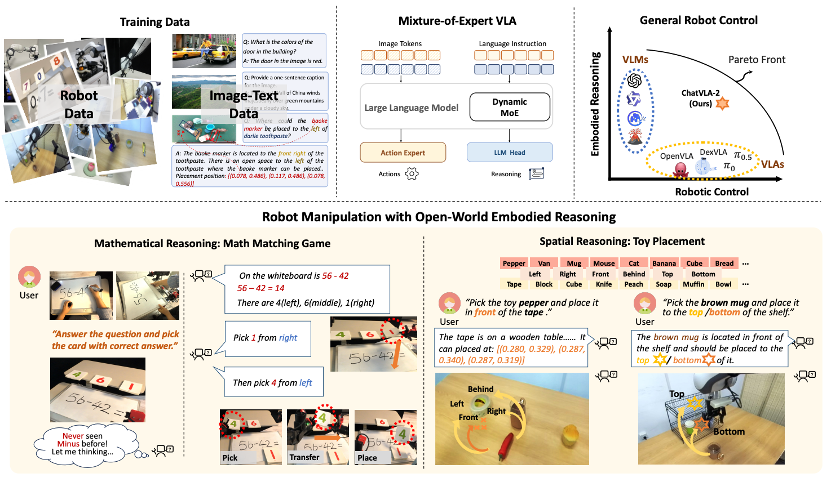
结果显示,ChatVLA-2面对新算式和新物体,在数学推理、空间理解和泛化操作能力上远超现有方法,开放世界任务成功率高达82%。
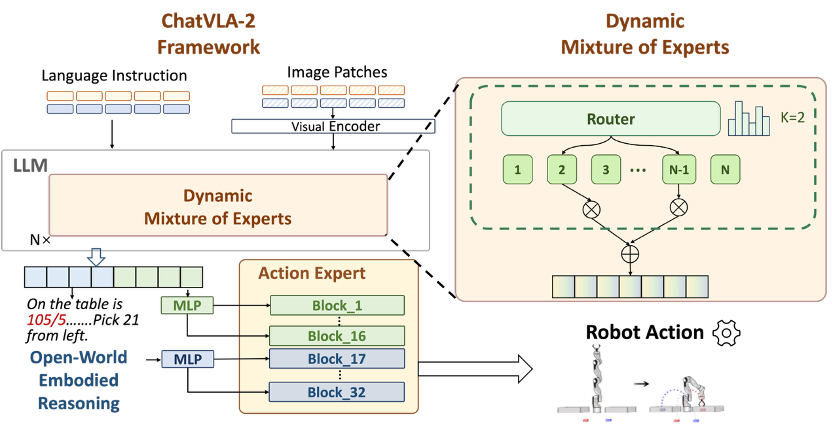
模型结构:专家协作,推理注入
混合专家模型
ChatVLA的研究表明,多模态理解与机器人操作任务往往会在参数空间中相互竞争。
为此,研究引入了混合专家模型架构(MoE),动态选择专家模块,希望部分专家专注于特定任务特征,另一些专家捕捉在多任务间共享的互利特征。这种自适应策略也确保了计算资源的高效分配。
推理跟随增强模块
为了让机器人动作能精准跟随复杂、甚至前所未见的域外推理指令,ChatVLA-2在模型的深层用推理令牌替换了原有的观测嵌入,生成调控动作生成的缩放与偏移参数,深度注入到模型决策过程中。
训练策略:先知后行,知行合一
仅仅拥有强大的模型骨架,还不足以打造真正通用的视觉-语言-动作模型。
如果在训练中直接混合开放世界图文数据与具身机器人动作数据,往往会导致动作学习过程难以控制,从而影响最终性能。
为此,团队创新性地提出了双阶段训练策略。
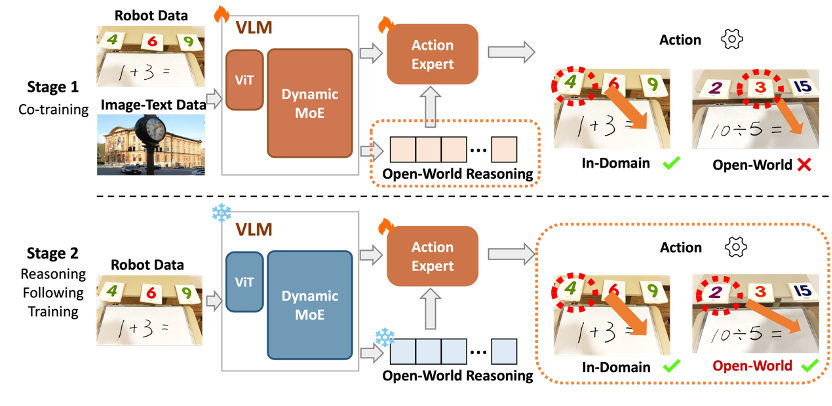
第一阶段:激活开放世界理解与推理
为了实现这一目标,将图文数据与机器人数据协同训练(co-training)被证明至关重要。
团队使用了多个开放场景主流图文数据集,并专门构建了机器人场景图文。训练数据的选择有意规避了对特定技能的倾向(如字符识别、数学推理)。
第二阶段:精进模型的推理跟随能力
开放世界的复杂任务常常需要模型进行超出训练数据范围的“超纲”推理。因此,确保模型动作能精准跟随并执行这些推理结果,是实现泛化控制的关键挑战。
基于此,模型在第二阶段冻结第一阶段中训练完的视觉语言模型,锁定其习得的知识与推理能力,只训练动作专家。
该策略能显著强化模型对前所未见推理场景的理解与响应能力,并让模型的“思考”过程与最终的“行动”输出紧密结合,从而大幅提升动作执行的精准度和任务完成的泛化性。
实验与效果
为全面验证ChatVLA-2,研究团队进行了大量真机实验。他们特别设计了两种实验场景:数学匹配游戏和玩具放置任务。
通过这些实验,重点考察了模型在数学推理、空间推理、字符识别(OCR)以及物体识别和定位方面的综合能力,其中任务涉及的开放世界场景并未出现在训练数据中。
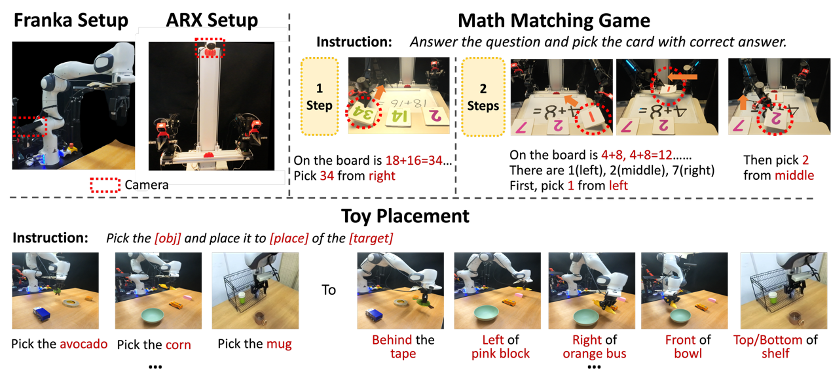
数学推理能力:在数学匹配游戏中,研究团队采用了三类指标来评估模型在域内和开放世界下的操控、推理与理解能力,包括任务成功率、手写数字与符号识别得分、以及数学推理得分。
开放世界评估中,测试的数学等式未在训练数据中出现,手写数字也存在不同书写风格。
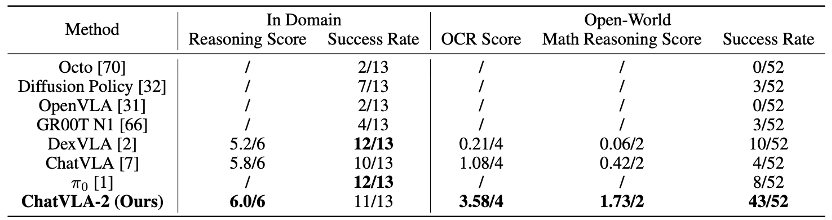
相比其他模型在陌生场景中几乎无法完成任务,ChatVLA-2 在未见过的数学表达上,依然取得了3.58的OCR得分、1.73的数学推理得分,并达成82.7%的操控成功率。
空间推理能力:在玩具放置任务中,研究团队同样采用三类指标:任务成功率、目标物体与参考物体识别率、边框准确识别得分。
开放世界评估中,目标和参考物体在训练中从未出现,模型需在此场景下识别所有物体,定位参考物体,理解空间关系,并完成摆放。
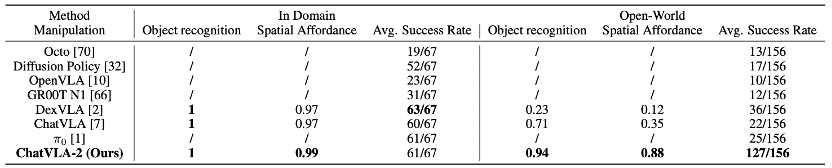
在陌生场景中,ChatVLA-2面对从未见过的物体和空间关系取得了0.94的目标识别得分,并以81.4%的操控成功率领先同类方法,充分证明了其在开放世界推理与机器人执行上的卓越实力。
从保留视觉-语言模型的认知能力,到实现推理结果向动作的转化,ChatVLA-2提供了一种探索通用机器人控制的新思路,并为后续在复杂场景与多模态交互中的研究提供了参考方向。
论文链接:https://arxiv.org/abs/2505.21906
项目主页:https://chatvla-2.github.io/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)