



论文标题:
Unified Domain Adaptive Semantic Segmentation
第一作者:
张哲(东北大学)
通讯作者:
柴天佑、吴高昌
合作作者:
张敬、朱霞天、陶大程
合作单位:
东北大学、武汉大学、英国萨里大学、新加坡南洋理工大学
项目主页:
https://github.com/ZHE-SAPI/UDASS

导语:从无监督域适应任务挑战到统一突破
1.1 任务背景
在语义分割领域,无监督领域自适应(Unsupervised Domain Adaptive Semantic Segmentation,UDA-SS)旨在将有标签的源域知识迁移到无标签的目标域。随着数据规模和多样性的迅速提升,该任务日益重要。
目前主流研究集中于图像 UDA-SS,而视频 UDA-SS 近年来也开始受到关注。然而,两者的研究路径几乎完全割裂,存在如下挑战:
(a)研究割裂:图像与视频任务各自为政,导致方法碎片化、认知零散;
(b)方法难迁移:图像方法无法有效迁移到视频,视频方法无法泛化至图像;
(c)知识利用低效:两类任务间经验难以共享,降低整体研究效率。
1.2 核心突破
本文首次提出统一处理图像与视频 UDA-SS 的框架,通过统一特征空间建模和统一训练路径,有效解决上述割裂与低效问题。
为此,我们设计了全新机制 QuadMix(四向混合),构建连续、稳健、丰富的中间域表示,从而大幅缩小跨域差异。并进一步引入光流引导的时空聚合模块,用于细粒度特征的分布对齐。
统一不是简单地“通用化”,而是一种深入语义建模的能力提升。QuadMix 作为桥梁,不仅使图像和视频任务共享表征基础,更通过可扩展的路径结构,有望实现跨模态、跨场景的泛化能力,从而为未来多模态感知系统奠定了范式基础。

▲ 图1. 相较于分别研究图像和视频的 无监督域适应语义分割(UDA-SS),我们提出了统一研究二者的研究框架。

方法详解:从四向混合到时空对齐
我们将图像视为无时间依赖的视频特例,提出统一建模图像与视频的视觉感知领域自适应语义分割新范式。
2.1 QuadMix:首创四向混合机制,跨域特征更稳定
我们在显式特征空间中同时引入以下四种混合路径:
(a)S → S:源域内部混合;
(b) T → T:目标域内部混合;
(c)T →(S → S):目标域融合到源内部混合中;
(d)S →(T → T):源域融合到目标内部混合中。
这种设计不仅打破了传统一阶/双向 Mixup 的限制,更是首次在特征空间中引入交叉式路径结构,最大限度地提升了域内连续性与语义对齐能力。实验表明,四向混合路径在 t-SNE 可视化中呈现更紧致、更均衡的分布,显著提升了迁移稳定性与泛化鲁棒性。

▲ 图2. 不同领域混合范式的对比。与现有方法相比(存在如域内不连续性,特征泛化性差,以及特征分布不一致问题),我们提出的 QuadMix 方法在空间(时间)维度的像素级与特征级上,同时对域内混合和跨域混合进行了泛化与增强。其中符号“*”表示样本模板。
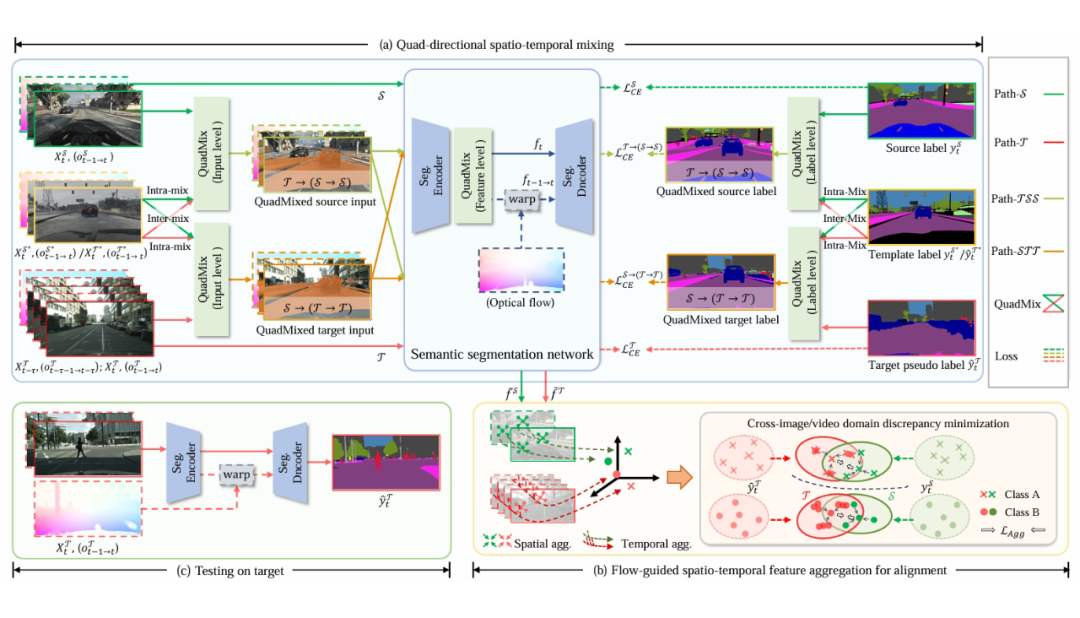
▲ 图3. 所提出的 QuadMix 用于 UDA-SS 的整体框架概览。图像领域自适应语义分割(Image UDA-SS)遵循一条并行流程,唯一的区别在于不包含时间线索,如图中虚线所示。
(i)图(a):QuadMix 包含四条全面的域内/跨域混合路径,在时空像素层与特征层上桥接域间差异。像素级混合作用于相邻帧、光流和标签/伪标签,旨在迭代生成两个增强的跨域中间域:T→(S→S)和 S→(T→T)。
这些中间域克服了源域 S 与目标域 T 内部的非连续性,并展现出更具泛化性的特征,从而有效弥合域间差异。此外,在 quad-mixed 域之间进行的特征级混合,有助于缓解因不同视频上下文导致的特征不一致问题。
(ii)图(b):光流引导的时空特征聚合模块将跨域视频特征压缩至一个紧凑的类别感知空间中,有效最小化类内差异,并提升类间判别能力,从而增强目标域的语义表征能力。
(iii)整个训练过程是端到端的。在图(c)中,目标域测试阶段需要输入相邻帧堆叠的序列和光流 。
2.2 类别感知 Patch 模板生成
QuadMix 的混合质量高度依赖于 Patch 模板的生成机制。为此,我们创新性地引入“在线类别感知 Patch 模板”机制:
(a)针对图像和视频,分别提取语义一致的类别区域作为模板;
(b)在每个训练迭代中自适应更新,避免固定模板带来的标签漂移问题;
(c)Patch 模板不仅包含像素,还包括伪标签和光流信息,覆盖图像+视频两个维度;
这些模板为每个 iteration 中 QuadMix 路径构建提供高质量输入,确保跨域混合具备一致的语义表征。

▲ 图4. 展示了在视频 UDA-SS 中,QuadMix 的多种混合策略示例:(a)为源域 S 和目标域 T 的原始样本(QuadMix 之前);(b) 显示了源模板 S*(如人物、骑手)与目标模板 T*(如交通标志、天空);(c)展示了域内混合路径 S→S 与 T→T 的结果;(d)展示了进一步的跨域混合路径 S→(T→T)与 T→(S→S),即 QuadMix 后的结果。这些混合策略分别作用于视频帧、光流与标签/伪标签。需要特别说明的是,每一轮训练中所需的 Patch 模板均通过在线机制根据前一轮(n−1)自适应生成。请放大查看细节。
2.3 像素级 + 特征级双层混合
输入级混合解决图像构成层次的差异,特征级混合则进一步对语义表征层进行融合与对齐。
(a)输入级 QuadMix:通过 Hadamard 运算叠加帧、标签与光流模板;
(b)特征级 QuadMix:构建共享类别掩码区域,在特征图中动态拼接并共享表示;
我们还使用轻量化的 1×1 卷积模块实现特征融合,从而减少语义漂移区域,提高模型鲁棒性,并有效降低了计算成本。

时空聚合机制:让视频特征对齐更加细粒度
与图像不同,视频数据包含时序信息,如何充分利用时间结构进行语义对齐,是提升视频 UDA 性能的关键。
本文提出的“光流引导的时空聚合模块”,围绕三个维度展开:
3.1 光流引导的伪标签传播
(a)使用 ACCEL 网络结构获取光流;
(b)将光流用于伪标签 warp 操作,获得跨帧伪标签;
(c)保证语义一致性与时序鲁棒性;
该模块显著提高了伪标签在视频中的质量,为后续聚合与对齐奠定基础。
3.2 类别感知的空间聚合
(a)按类别构建特征子空间;
(b)对每类特征进行平均聚合,获得“类别代表向量”;
(c)使用该向量进行空间重构,提升类别判别力;
3.2 时间维度的信息聚合
(a)多帧空间聚合结果通过信息熵加权方式融合;
(b)构建时序一致的语义表示;
最终,整个模块实现类别–空间–时间三重维度的精细化特征对齐,为目标域提供了坚实的泛化支持。

▲ 图5. 展示了用于领域对齐的光流引导时空特征聚合过程,其中 表示前一时间步, 表示目标帧的时间聚合权重。 表示从前一时间步 通过光流引导 warp 得到的帧特征,其中 “→” 表示沿时间维度的 warp 方向。

实验验证:全面评估四大数据集,全面领先
我们在四个经典的 UDA-SS benchmark 上进行了严格验证,涵盖图像与视频两大类任务:
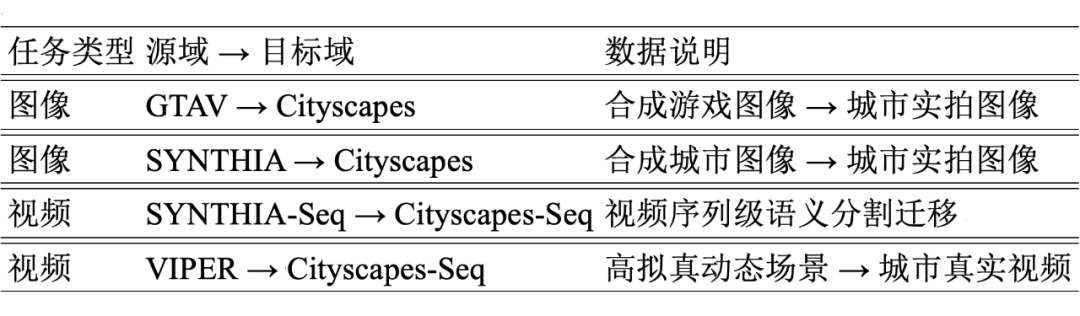
具体实验结果如下:
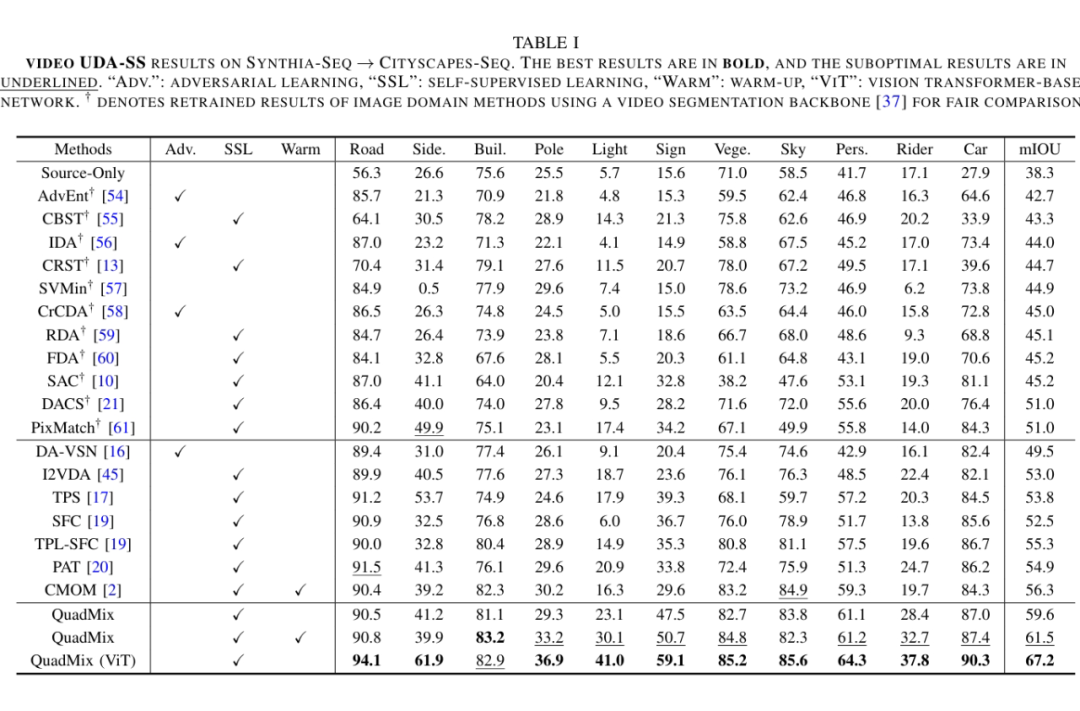
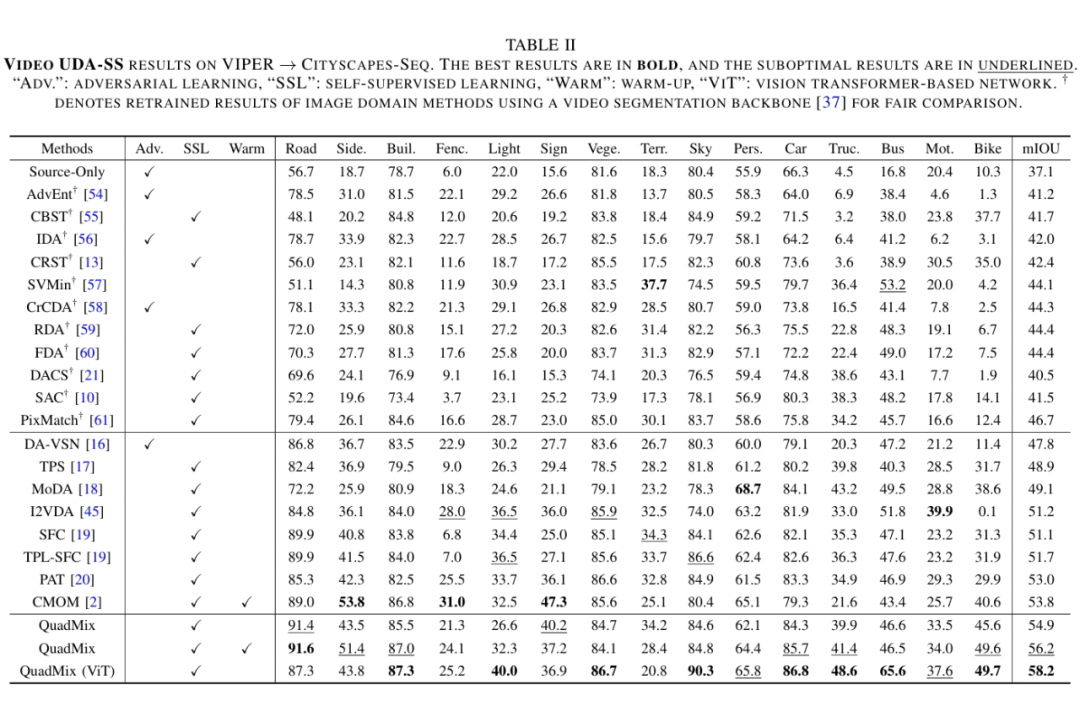
4.1 视频域适应语义分割任务
4.2 图像域适应语义分割任务
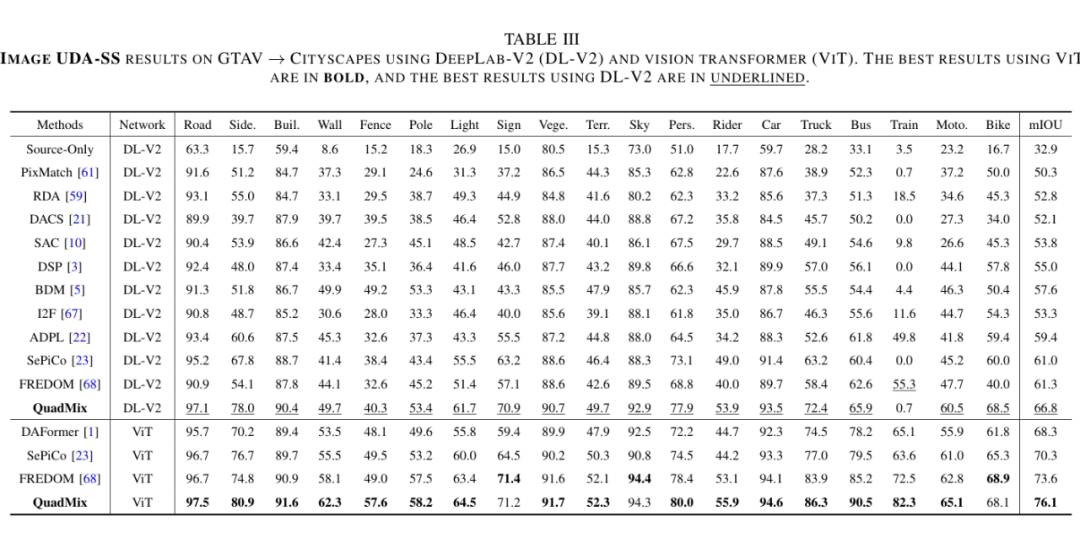

在各种任务上,我们的方法均显著超过现有 SOTA 方法,如 DACS、ProDA、DAFormer、SAC、CMOM 等。
其中最引人注目的是:在 SYNTHIA-Seq → Cityscapes-Seq 视频迁移任务上,我们使用 Vision Transformer 架构(QuadMix ViT)实现了 67.2 的 mIoU,刷新历史最好结果,领先前 SOTA(PAT、TPL-SFC)近 12 个百分点。
此外,在 GTAV → Cityscapes 图像迁移任务中,QuadMix 实现 66.8 的 mIoU,超过 DAFormer、SePiCo 等先进方法,展现统一方法在图像上的强大适应能力。
4.3 消融实验

4.4 可视化结果分析

▲ 图6. 来自 Cityscapes-Seq 验证集的三个连续帧的定性结果。结果展示顺序如下:目标图像、真实标签、仅源域模型的语义分割结果、DA-VSN [16]、TPS [17]、CMOM [2] 以及本文提出的方法。我们的方法在分割精度上表现最佳,边缘更平滑、细节更精细。请放大查看细节。
更多可视化结果请参考视频 demo:
4.5 特征空间分布TSNE分析

▲ 图7. 展示了不同混合范式在 t-SNE 空间中的可视化效果,分别以 sign(第一行)和 pole(第二行)两个类别为例。子图(a)到(e)的实验设置对应表 VI 中的消融实验编号:Exp.ID 0*、ID 6、ID 1、ID 3 和 ID 12。请注意,子图(b)、(d)和(e)中的点数相同。子图(b)展示的是域内混合(intra-mixed)后的特征嵌入,呈现出较为连续的分布;而子图(e)展示的 四向混合(quad-mixed) 域则表现出更具泛化性的特征分布,而非聚集式的形式。这种分布更有效地缓解了域内不连续性问题,并更好地实现知识迁移中的细粒度特征分布拉近。

理论支持 + 可复现性 + 工业可落地性
5.1 理论支撑
QuadMix 的有效性不仅体现在性能指标上,还获得了充分的理论与可视化支撑:
(a)使用 t-SNE 对比 QuadMix 与传统 Mixup 的特征分布,发现 QuadMix 特征分布更均匀、类别边界更清晰;
(b)通过类别交叉可视化,展示 quad-mixed 域具备更强的语义一致性与边界准确性;
5.2 可复现性
(a)所有实验已开源:https://github.com/ZHE-SAPI/UDASS
(b)支持主流框架(PyTorch)和多种分割 backbone(CNN/ViT)
(c)训练脚本、预处理流程、模型参数均一键调用
5.3 工业部署潜力
由于 QuadMix 可以不依赖 offline warm-up 模型和固定伪标签生成器,具备如下优势:
(a)易于部署到边缘设备或实时视频处理系统;
(b)可无缝集成至现有工业语义分割 pipeline;
(c)支持城市感知、AR导航、智能制造等多种场景;

未来研究:从统一分割迈向跨模态感知新方向
我们认为,统一研究视频和图像 UDASS 不是融合的终点,而是跨模态泛化的起点。QuadMix 所提出的“四向混合”不仅服务于图像与视频的统一语义分割,更提供了未来跨模态建模的结构性范式:
(a)可推广至图文融合(Image-Text UDA)、点云+图像联合建模(Multi-Sensor Fusion);
(b)可用于大模型预训练中的中间域设计,如 Diffusion 模型数据生成优化;
(c)甚至可拓展到 Reinforcement Learning 场景中的策略迁移与经验对齐;
整体而言:QuadMix 代表的是从数据空间结构建模出发,构建统一泛化表示的全新路径。
欢迎关注团队主页、代码仓库,或联系作者学术交流!
(文:PaperWeekly)