

编辑:泽南
Apple Intelligence 进入新的一章。
近日,苹果发布了 2025 年 Apple Intelligence 基础语言模型技术报告。
刚刚加入 Meta 的前苹果 AI 负责人庞若鸣(Ruoming Pang)发出多条推文进行了介绍。
在报告中,苹果详细介绍了训练新一代模型所用的数据、模型架构、训练方案、优化推理技术手段,以及与同类模型对比的评估结果。文中重点展示了苹果如何在提升用户价值的同时实现功能扩展与质量优化,并大幅提高设备端和私有云计算的运行效率。
报告链接:https://machinelearning.apple.com/research/apple-foundation-models-tech-report-2025
这次苹果介绍了两种多语言、多模态基础语言模型,可为苹果设备和服务中的 Apple Intelligence 功能提供支持。其中包括:
1)通过 KV 缓存共享和 2 位量化感知训练等架构创新,针对苹果自有芯片进行了优化的 3B 参数设备模型;2)一种可扩展的云端模型,它结合了新型并行轨道混合专家 (PT-MoE) Transformer 和交错的全局 – 局部注意力,以便在苹果的私有云计算平台上进行有效推理。
这两款模型均通过负责任的网络爬取、授权语料库和高质量合成数据集进行大规模多语言、多模态训练,并在新的异步平台上通过监督微调和强化学习进一步优化。最终模型不仅支持多种新增语言,还能理解图像并执行工具调用。
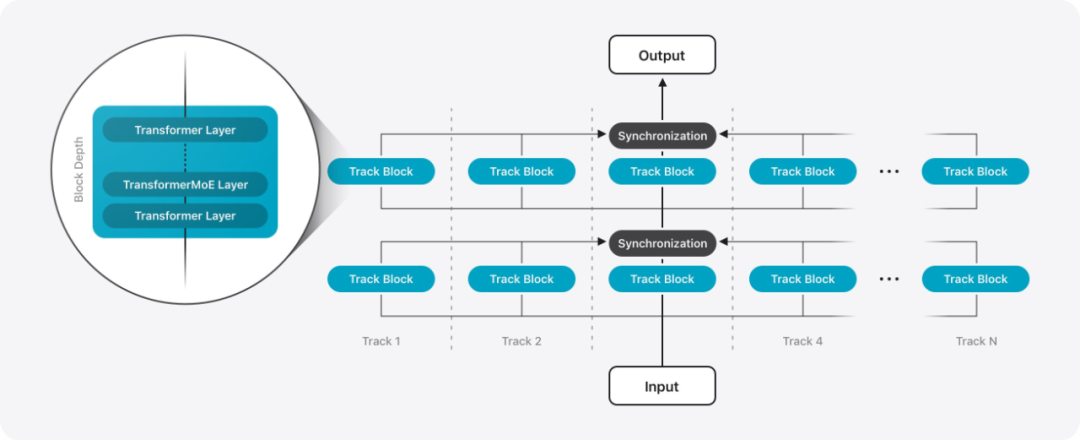
PT-MoE 架构示意图。每个轨迹 track 由多个轨迹块组成,每个轨迹块包含固定数量的 Transformer/MoE 层。假设总层数为 L 层且轨迹块深度为 D,则同步开销可从 2L(张量并行)降低至 L/D(轨迹并行)。例如当 D = 4 时,PT 架构可将同步开销减少 87.5%。
PT Transformer 是苹果研究人员提出的一种新型架构。与仅包含单一顺序层堆栈的标准解码器式 Transformer 不同,该架构将模型划分为多个小型 Transformer 模块,称为轨道。每个轨道由多个堆叠的轨道块组成,每个轨道块本身都是一个 Transformer 层堆栈。这些轨道块独立处理标记数据,仅在轨道块的输入输出边界进行跨轨道同步。这种隔离设计不仅实现了轨道间的直接并行执行,还有效降低了传统 Transformer 解码器(如采用张量并行技术的模型)中常见的同步开销。这种方法被称为轨迹并行,改进了训练和推理的延迟,而不会影响模型的质量。
为实现服务器端模型的进一步扩展,苹果在每个轨道块内部引入了专家混合层(MoE),从而构建出 PT-MoE 架构。由于各 MoE 层中的专家模块仅在对应轨道内运行,通信开销可与计算过程有效重叠,从而提升训练效率。结合轨道并行性带来的轨道级独立性优势,这种设计使模型在保持低延迟的同时实现高效扩展 —— 得益于稀疏度的提升,模型运行更加轻量化。
另外为了实现现视觉理解能力,苹果引入了一个可以从输入图像中提取视觉特征的视觉编码器,在大量图像数据上进行了预训练,以提高其性能。视觉编码器包含两个关键组件:一个视觉主干,用于从输入图像中提取丰富的视觉表征;以及一个视觉语言适应模块,用于压缩视觉表征并将这些视觉特征与模型的标记表征进行对齐。
在视觉主干网络中,苹果采用了标准的视觉 Transformer(ViT-g),服务器模型为 10 亿参数;以及更高效的 ViTDet-L 主干网络,设备端模型为 3 亿参数。
设备端视觉主干网络采用了 ViTDet 架构,该架构在大多数视觉 Transformer 层中使用窗口注意力机制,仅包含三个跨窗口全局注意力层。为更有效地捕捉并整合细粒度局部细节与宏观全局上下文信息,苹果在标准 ViTDet 基础上创新性地引入了注册窗口(RW)机制。该机制通过让全局注册表(或类别)标记在参与整体全局上下文聚合前,先与图像中的不同局部窗口进行交互,从而实现对全局特征的编码。
苹果认为,端侧和云端模型配合可以满足广泛的性能和部署需求。设备端模型经过优化,能够以最低资源消耗实现低延迟推理;而服务器端模型则专为复杂任务设计,提供了高精度和可扩展性。
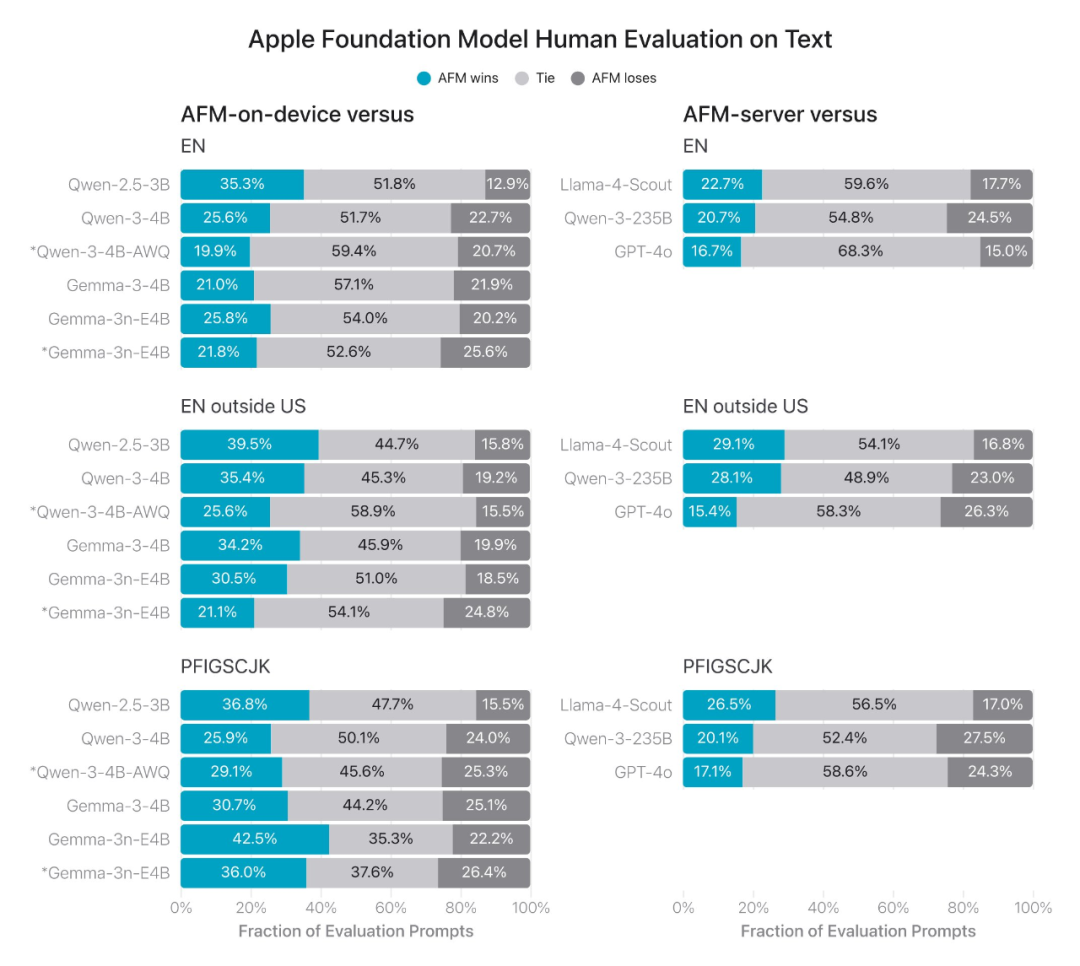
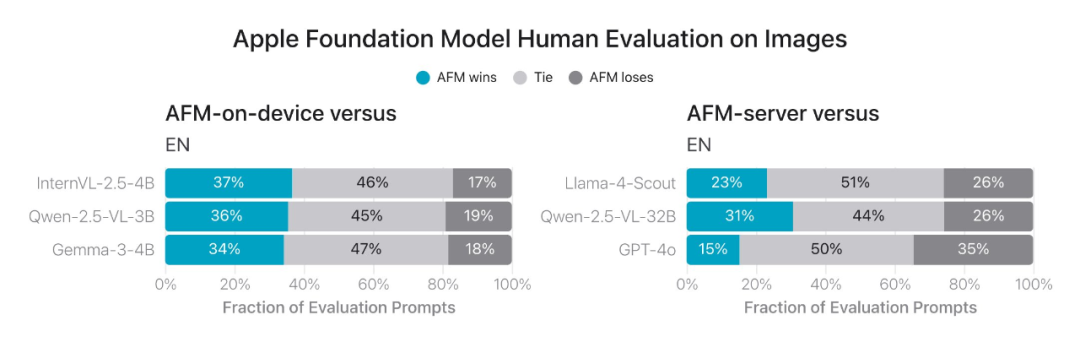
在人工评估基准中,苹果的模型在跨语言、文本和视觉模式上都具有不错的竞争力,甚至优于同等规模的最佳开源模型。
在技术报告中,苹果还介绍了全新推出的 Swift 核心的基础模型框架,其中集成了引导式生成、约束式工具调用和 LoRA 适配器微调三大功能模块,开发者仅需几行代码即可轻松实现这些功能的集成。
该框架让开发者能够借助约 30 亿参数的设备端语言模型,着手打造可靠且具备量产级品质的生成式 AI 功能。作为 Apple Intelligence 的核心,它在摘要、实体提取、文本理解、优化、简短对话、创意内容生成等多样化文本任务中表现卓越。不过苹果表示,虽然已针对设备端模型进行了专门优化,但它并非为通用知识问答而设计。苹果鼓励应用开发者利用该框架为 APP 定制实用功能。
苹果表示,Apple Intelligence 模型的最新进展始终遵循「负责任的人工智能」的理念,通过内容过滤、地区定制评估等安全防护措施,并依托私有云计算等创新技术,切实保障用户隐私安全。
在技术报告发布之后,庞若鸣不忘感谢了所有贡献者,其中包括模型、后训练、多模态、框架 / API、项目管理人员,同时把接力棒交给了苹果 AI 的下一任负责人 Zhifeng Chen 和 Mengyu Li。
此前据媒体报道,庞若鸣加入 Meta 后,苹果大模型团队将由陈智峰(Zhifeng Chen)负责,不过团队的管理架构将更加分散。
陈智峰 2000 年本科毕业于复旦大学,后于普林斯顿大学、伊利诺伊大学香槟分校获得硕士、博士学位。在加入苹果之前,陈智峰曾在谷歌长期工作,参与过 TensorFlow、Gemini、神经机器翻译系统、Palm 2 等重要研究。他和庞若鸣、吴永辉均是 Google Brain 早期的重要成员。
参考内容:
https://www.bloomberg.com/news/articles/2025-07-07/apple-loses-its-top-ai-models-executive-to-meta-s-hiring-spree

©
(文:机器之心)