



论文链接:
代码链接:

研究背景与挑战
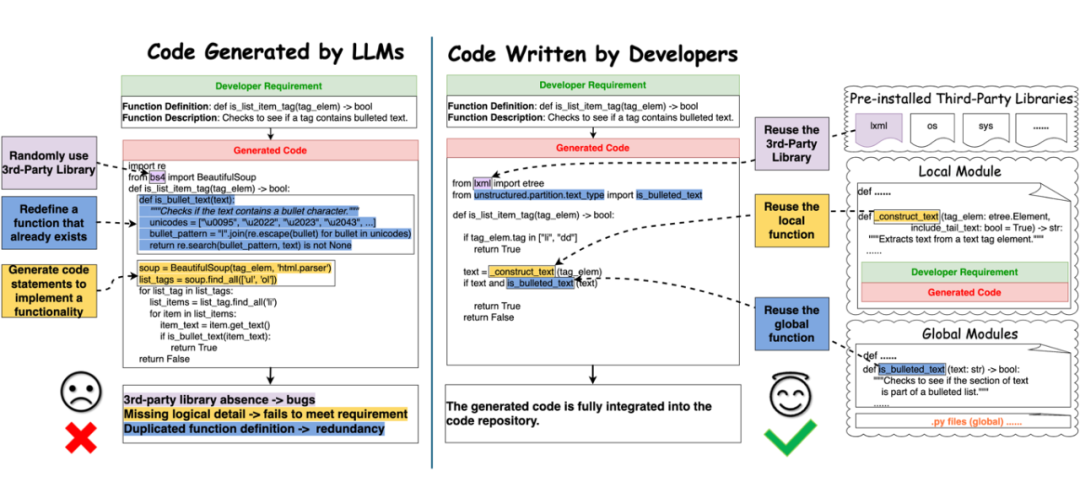
近年来,大语言模型(LLMs)如 ChatGPT、GitHub CoPilot 和 Codex,在代码生成领域取得了令人瞩目的进展。它们能够根据开发者的需求(例如自然语言描述或函数定义)自动生成代码。然而,与人类开发者编写的代码相比,LLMs 生成的代码仍存在显著差距。
-
局部信息(Local Information):当前代码文件中的上下文信息,例如函数签名、变量定义及模块的路径(如完全限定名,FQNs)。
-
全局信息(Global Information):代码库中其他文件中的函数及其依赖关系。例如,开发者可以从其他模块导入现有函数,而不是从零开始编写相同功能的代码。
-
第三方库信息(Third-Party Library Information):代码库中预先安装的第三方库。通过直接访问这些库,可以复用已有功能而无需额外依赖。
-
缺乏功能约束:不能正确复用代码库中的局部或全局函数;
-
冗余代码:重复实现代码库中已有的功能;
-
依赖错误:随机引用第三方库,可能导致依赖冲突或代码无法运行。
相比之下,经验丰富的开发者在编写代码时会充分利用代码库中的本地信息、全局函数及预先安装的第三方库(Code Written by Developers),从而生成与项目需求高度匹配的高质量代码。
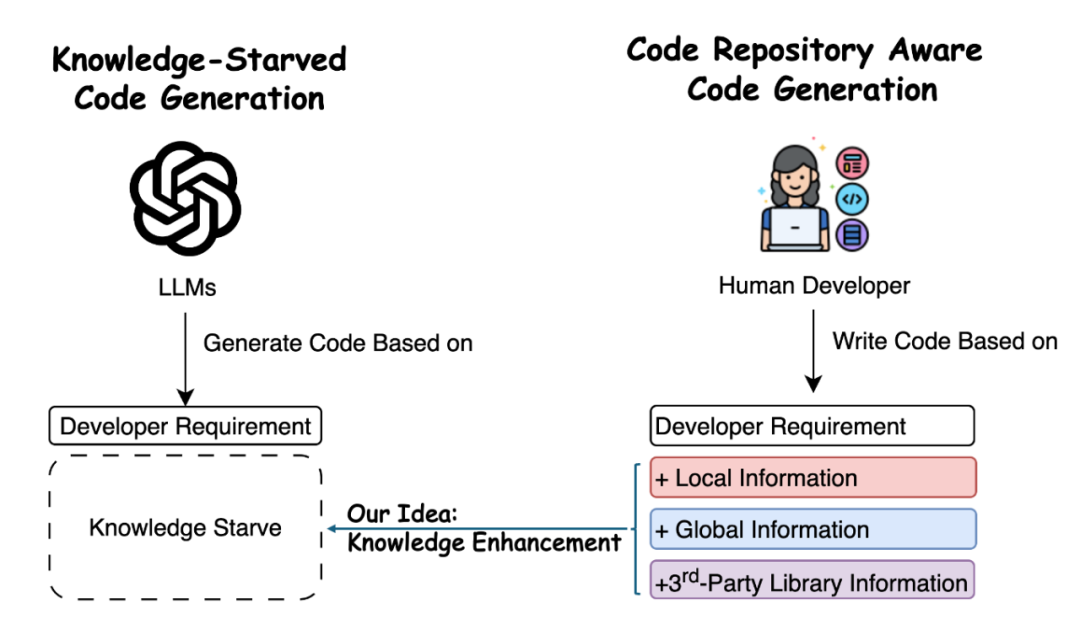
总的来说,如上图所示,与经验丰富的程序员相比,LLMs 在生成代码时由于缺乏对代码库中关键信息的理解,导致生成的代码往往难以满足实际需求。因此,为了实现高质量的代码生成,有必要对 LLMs 进行知识增强(Knowledge Enhancement)。通过为模型提供全面的代码库上下文信息,可以帮助 LLMs 更准确地理解代码库结构,并有效利用其中的知识生成代码。

A³-CodGen框架介绍

-
知识构建(Repository Knowledge Base Construction):从代码库中系统性挖掘函数库(function base)和第三方库(third-party library base),为后续的知识检索提供支持。
-
三类代码库知识检索(Three Types of Repo-Aware Knowledge Retrieval):检索当前文件的局部信息(local module)、全局信息(function base 中的 global 信息)以及第三方库信息,并将其组织为结构化知识。
-
代码生成(A³-CodGen):将三种代码库知识融合为提示(prompt)输入 LLM,生成符合上下文的代码。

实验评估与关键发现
-
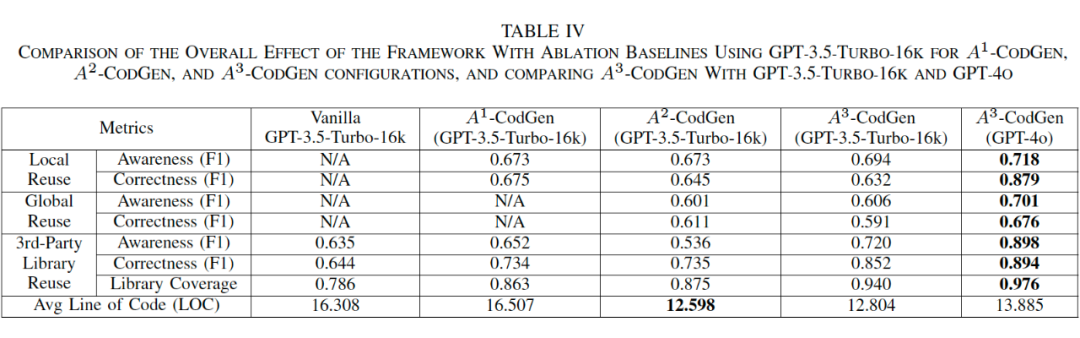
无知识增强(Vanilla):不提供额外知识,仅依赖模型原始能力。
-
局部知识增强(A¹-CodGen):提供局部信息增强。
-
局部+全局知识增强(A²-CodGen):同时提供局部与全局信息增强。
-
全面知识增强(A³-CodGen):提供局部、全局及第三方库信息增强。
-
三种知识类型(局部、全局、第三方库)均显著提升了 LLMs 在代码生成任务中的复用能力。
-
通过将基础模型从 GPT-3.5 升级为 GPT-4o,我们进一步验证了框架效果随模型能力提升而增强。
-
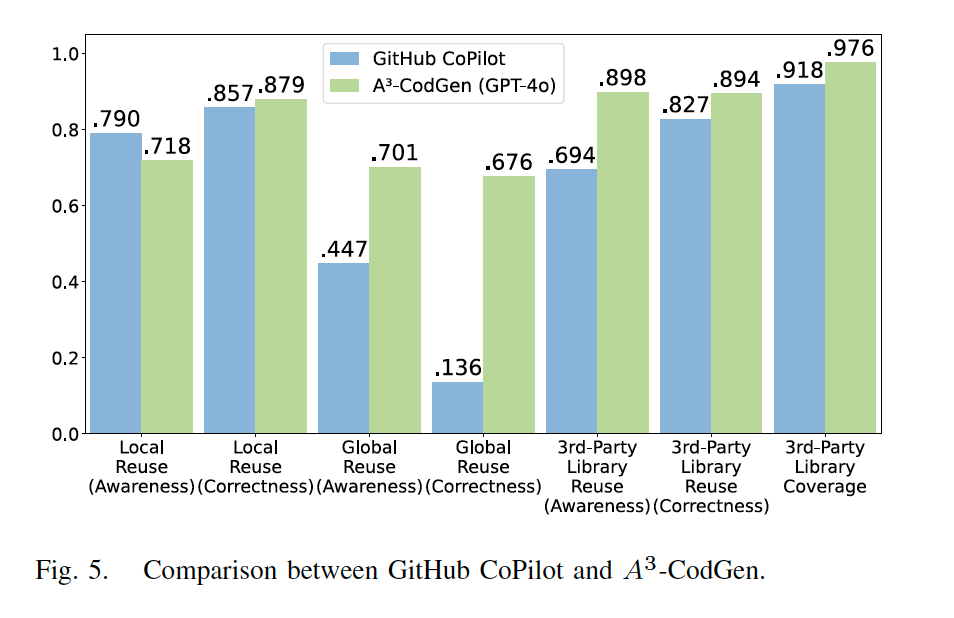
局部复用:CoPilot 在局部信息复用方面表现优异,但在全局和第三方库信息复用方面存在明显不足。
-
全局复用:CoPilot 能够利用邻近标签页的上下文信息实现一定程度的全局感知(global-aware),但由于无法获取未打开标签页中的全局信息,生成的代码难以正确复用这些全局资源。相比之下,A³-CodGen 通过检索和结构化处理全局函数,显著提高了全局信息复用的能力。
-
第三方库复用:A³-CodGen 在感知能力、正确性和覆盖率方面全面优于 CoPilot。A³-CodGen 能够识别并利用代码仓库中所有预安装的第三方库,而 CoPilot 则随机选择第三方库,导致较高的错误率。

讨论与未来发展
代码生成任务的新范式:传统的代码生成任务主要聚焦于根据特定需求自动生成满足功能要求的代码,诸如 GitHub CoPilot 和 ChatGPT 等工具在这一领域已取得显著成就。
然而,现实世界中的代码生成需求远超功能实现本身——它需要生成与项目上下文兼容的代码,同时充分利用已有知识,以提升代码的可读性、可维护性和实用性。因此,我们希望本研究能够为这一新兴但重要的代码生成话题提供新的启示。
面向代码生成的知识工程:LLMs 对提示(prompts)高度敏感,设计良好的提示对于生成高质量代码至关重要。然而,过于零散或过长的提示既不实际,也可能降低模型的生成效率。因此,我们建议从代码库中提取语义丰富的知识,以引导模型生成更具方向性和上下文感知的代码。
然而,如何选择性地融合不同类型的知识仍然是一个重要挑战。这种融合方式可能直接影响模型对不同知识类型的感知能力。实验结果表明,提供多样化的信息并不总能改善模型性能;但同时,我们发现,当模型被提供全局感知和第三方库信息时,其复用本地函数的能力却显著增强。
这一现象揭示了不同类型代码知识之间可能存在的隐性相互作用,也表明未来的研究需要更加关注如何高效提取、组织和利用知识,从而最大程度地激发 LLMs 的潜力。

总结
(文:PaperWeekly)