
为什么标题我讲这是个文本转“音效”模型,其实是转音频的,但更精确点来说,主要是用来生成一些拟音效果,比如刮风下雨、银针落地的声音、飞机起飞的轰鸣声。
不知道你们看没看过影视配音的场景,各种工具去模拟。
不知道后面影视配音会不会大批量被AI取代。
再讲一个概念问题。TTS大家都知道,文本转语音,给一段文字AI给读出来,像是今天给大家介绍的TangoFlux就是TTA,文本转音频。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
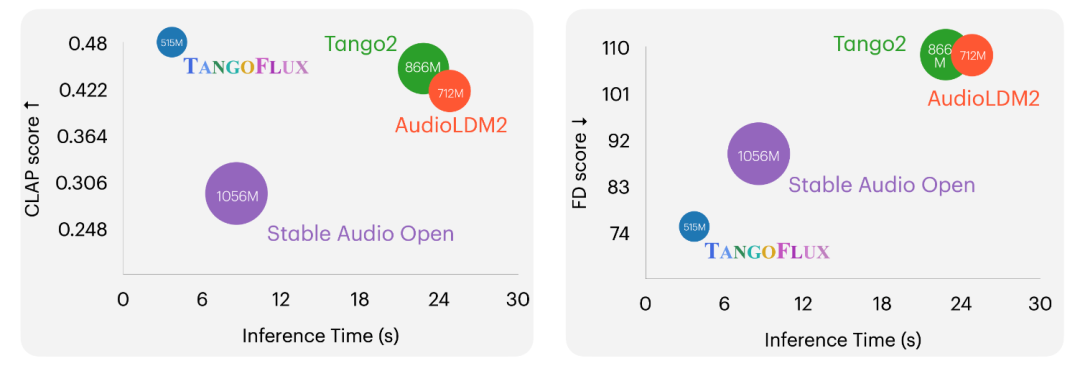
TangoFlux是由新加坡科技设计大学和NVIDIA联合开发的高效文本到音频生成模型。该模型拥有5.15亿参数,能在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。TangoFlux通过流匹配和Clap排名偏好优化(CRPO)技术,解决了传统文本到音频模型在对齐方面的难题,显著提升了生成音频与文本描述的匹配度。与现有顶尖模型相比,TangoFlux在音频质量、生成速度和参数数量上均展现出优越性能。
DEMO
提示词:生成一段烟花表演的声音:烟花在夜空中绽放,发出耀眼的光芒,人群在下方欢呼雀跃,背景中还隐约传来轻柔的音乐,营造出庆祝新年的热闹氛围!
提示词:旋律优美的人类口哨声与自然的鸟鸣声相得益彰
提示词:观众欢呼鼓掌
技术特点
1.高效生成能力:
TangoFlux能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。相比其他模型,它在生成速度上具有显著优势,能够在更短的时间内提供高质量的音频输出,极大地提高了音频生成的效率。
2.流匹配与直流量化流:
该模型采用流匹配框架,特别是直流量化流(Rectified Flows),这是一种从噪声到目标分布的直线路径,能够在减少采样步骤的同时保持音频质量。这种技术使得模型在生成过程中更加高效和稳定,减少了对计算资源的需求.
3.Clap排名偏好优化(CRPO):
TangoFlux引入了CRPO技术,利用CLAP模型作为代理奖励模型,通过迭代生成和优化偏好数据来增强模型的对齐能力。CRPO能够有效地提升生成音频与文本描述的匹配度,使音频内容更加符合用户的意图和期望.
4.多模态扩散变换器架构:
模型基于多模态扩散变换器(MMDiT)和扩散变换器(DiT)构建,结合了文本提示和时长嵌入,能够生成具有不同长度和丰富细节的音频。这种架构使得模型在处理复杂的文本描述和生成多样化的音频内容方面具有更强的能力.
项目链接
https://github.com/declare-lab/TangoFlux
试用链接
https://huggingface.co/spaces/declare-lab/TangoFlux
论文链接
https://arxiv.org/html/2412.21037v1
关注「开源AI项目落地」公众号
(文:开源AI项目落地)