




1.1 核心方法
图像与视频的统一理解:Qwen2-VL 采用混合训练策略,结合了图像和视频数据,确保其在图像理解和视频理解方面的能力。为了最大程度地保留视频信息,视频以每秒两帧的频率进行采样,并通过 2 层深度的 3D 卷积处理视频输入。每张图像被视为两个相同的帧,以便与视频的处理保持一致。
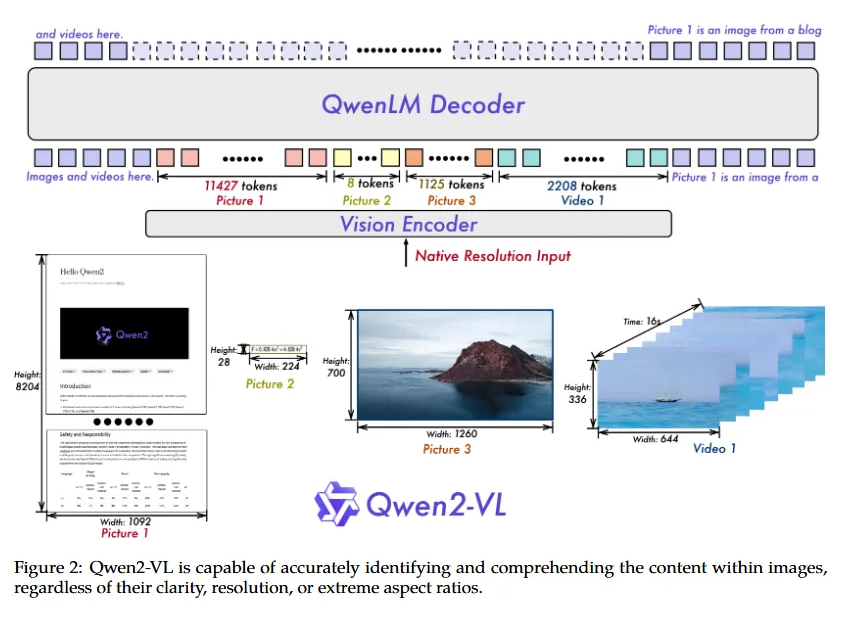
训练阶段概述:
-
在初始预训练阶段,Qwen2-VL 接触到大约 6000 亿个 token,专注于学习图像-文本关系、图像中的文本识别(OCR)和图像分类任务。Qwen2-VL 的 LLM 组件使用 Qwen2 的参数初始化,视觉编码器则使用 DFN 的 ViT 进行初始化,但将原始 DFN 的固定位置嵌入替换为 RoPE-2D。
-
第二阶段预训练:增加了额外的 8000 亿个图像相关的标记,进一步引入更多混合的图像-文本内容,增强视觉与文本信息的交互理解。同时,增加了视觉问答数据集,提升了模型回答图像相关问题的能力。
-
在指令微调阶段,采用了 ChatML 格式构建指令跟随数据集,数据集包括文本对话数据和多模态对话数据,如图像问答、文档解析、图像比较、视频理解等。
数据格式:
-
使用特殊标记来区分视觉和文本输入,<|vision_start|> 和 <|vision_end|> 用于标记图像特征序列的开始和结束。
-
对话数据使用 ChatML 格式,<|im_start|> 和 <|im_end|> 用于标记每个交互的语句。
-
引入了目标定位(Visual Grounding)和引用定位(Referring Grounding)来帮助模型理解图像中特定区域的文本描述。
1.3 实验结果总结
视觉问答
-
Qwen2-VL-72B 在多个视觉问答基准(如 RealWorldQA、MMStar 等)中表现出色,通常超越其他现有模型。
-
在 DocVQA、ChartQA 等任务中,Qwen2-VL 在高分辨率文档和图表理解方面达到了 SOTA 水平,尤其在 OCR 任务中表现突出。
-
Qwen2-VL 在多语言 OCR 任务中超越了其他模型,包括 GPT-4o,展现了其强大的文本识别能力。
-
在 MathVista 和 MathVision 等数据集上,Qwen2-VL 在数学推理任务中的表现超越了其他模型。
-
在多个视频理解基准(如 MVBench、PerceptionTest 等)上,Qwen2-VL-72B 展现了强大的视频理解能力,尤其在处理较长视频时表现优异。
-
Qwen2-VL 在复杂任务(如 UI 操作、机器人控制和卡牌游戏等)中,表现出卓越的功能调用和决策能力,超越了 GPT-4o。
-
增加模型规模和采用动态分辨率策略有助于提升性能,尤其在视频和数学任务中。动态分辨率在减少token数量的同时,保持了优异的任务表现。

Molmo和PixMo

总的来说,本文的改进集中在数据侧,包括了一些数据合成的方法,开放了更高质量得多模态数据等。
2.1 核心方法

模型框架实际上与现有得大多数 MLLM 差别不大,包括了 ViT-L/14 336px CLIP 得 vision encoder,MLP+ 池化作 connector,以及一个大语言模型。
在这两个阶段中,所有模型参数都会进行更新,且不使用强化学习(RLHF)进行训练。
2.2.1 第一阶段:图像描述生成
在此阶段,Molmo 模型通过将视觉编码器与语言模型结合,并加入一个随机初始化的连接器来进行训练,目标任务是图像描述生成。PixMo-Cap 数据集是专门为此阶段收集的,具体过程如下:
-
图像来源:从大约 70 个高层主题(如街头标志、表情包、食物、绘画、网站、模糊照片等)中筛选网络图像。
-
描述收集:每张图片请三位标注者进行至少 60 秒(后期调整为 90 秒)的口头描述。描述内容涵盖图像的基本信息、物体数量、文字内容、物体位置、背景信息以及细节描述等。
-
音频转录与处理:标注者的口头描述会被转录为文本,并通过语言模型进行文本优化(例如去除口语化的痕迹,统一风格)。
-
数据增强:使用这些优化后的文本(如果有四种文本变体,则每个图像使用所有文本进行训练),最终训练了 712k 张图像和约 130 万条描述。
2.2.2 第二阶段:监督微调
图像描述生成后,Molmo 模型会进行监督微调,目标是使模型在实际使用中具备更强的泛化能力。微调数据集包括了常见的学术数据集和多个新的 PixMo 数据集:
-
PixMo-AskModelAnything:收集了 162k 问答对和 73k 图像,目的是使模型能够回答各种可能的用户提问。标注者会先选择一张图像并提问,然后使用模型生成详细描述和答案,最后人工审核和修正答案。
-
PixMo-Points:收集了 2.3M 个问答对,涵盖 428k 张图像,旨在使模型通过指向图像中的具体位置来回答问题。这个数据集帮助训练模型在图像中定位信息,并用指向来解释回答。
-
PixMo-CapQA:生成了 214k 问答对,来源于 165k 张图像的描述。通过使用语言模型生成问答对,以增强模型的回答多样性。
-
PixMo-Docs:通过生成 255k 文本和图表图片,训练模型回答基于文本和图像的复杂问题,共收集了 2.3M 个问答对。
-
PixMo-Clocks:通过生成合成的模拟时钟图像,创建了 826k 个时钟相关的问答对。
-
学术数据集:包括 VQA v2、TextVQA、OK-VQA、ChartQA、DocVQA 等多个知名学术数据集,以及其他补充数据集,如 AI2D、A-OKVQA、ScienceQA 等。
通过上述数据集,Molmo 模型得以在多种视觉-语言任务中进行监督微调,增强了其多模态理解和推理能力。
2.3 实验结果概括
Qwen2-VL 的差异: 尽管 Qwen2-VL 在学术基准测试中表现强劲,但在人类评估中相对表现较差。

英伟达:NVLM

3.1 三种不同的特征融合框架

3.1.1 共享视觉编码器
NVLM 系列模型的所有架构共都使用了一个固定分辨率的视觉编码器(InternViT-6B-448px-V1-5)。图像会被切分为 1 到 6 切块,每个块大小为 448×448 像素,并通过降采样操作将图像 tokens 数量从 1024 减少至 256。这种设计提升了 OCR 任务的性能,同时减少了处理负担。
3.1.2 NVLM-D: Decoder-only模型
NVLM-D 采用传统 decoder-only 架构,使用 2 层 MLP 将预训练的视觉编码器与 LLM 连接。该模型通过联合预训练和监督微调来适应多模态任务,其中视觉编码器在训练过程中被冻结。
3.1.3 NVLM-X: 交叉注意力模型
NVLM-X 使用交叉注意力机制来处理图像 tokens,而不直接将图像 tokens 输入到 LLM 解码器中。此方法避免了潜在的空间关系干扰,特别适用于 OCR 任务。该模型还引入了切块标签,并利用 X-attention 确保每个切块的空间关系被正确处理。
3.1.4 NVLM-H: 混合模型
NVLM-H 结合了NVLM-D 和 NVLM-X 的优点。通过将缩略图像 tokens 与文本 tokens 一同输入到 LLM 进行自注意力处理,同时使用交叉注意力处理图像切块,NVLM-H 在保留高分辨率处理能力的同时,显著提升了计算效率。
-
1-D 扁平化标签:这种标签(例如 <tile_1>,<tile_2>)简单直接,适用于大多数任务,特别是 OCR 任务。 -
2-D 网格标签:通过标签(如 <tile_x0_y0>,<tile_x1_y0>等)表示切片的位置,能够更好地捕捉图像中的空间关系。 -
2-D 边界框标签:这种标签以坐标的形式(如 <box> (x0, y0), (x1, y1) </box>)明确标识每个切片在图像中的具体位置。
虽然 2-D 标签能够提供更多空间信息,但实验结果表明,1-D 标签通常能提供更好的泛化能力,特别是在测试时。在一些数学推理和跨学科推理任务中,1-D 标签也带来了不错的性能提升。
-
NVLM-X:采用了门控交叉注意力机制(gated cross-attention)来处理图像切片。与其他方法不同,NVLM-X 通过切片标签帮助模型理解切片的位置和结构,这使得它在处理高分辨率图像时表现更好。 -
NVLM-D:这个模型没有交叉注意力机制,而是通过解码器直接处理图像切片。这使得它参数较少,但由于需要将所有图像切片拼接后输入模型,导致内存消耗大,训练效率较低。 -
优势对比:NVLM-X 在多模态推理任务和 OCR 任务中比 NVLM-D 有更好的表现,尤其在处理高分辨率图像上。
训练效率与参数效率
-
NVLM-X:在处理高分辨率图像时,通过减少长序列的拼接,显著提高了训练效率,并且有效减少了 GPU 内存的消耗。 -
NVLM-D:由于需要处理长序列的图像切片,内存使用较高,训练吞吐量较低,但在参数数量上相对较少。
3.3 训练策略
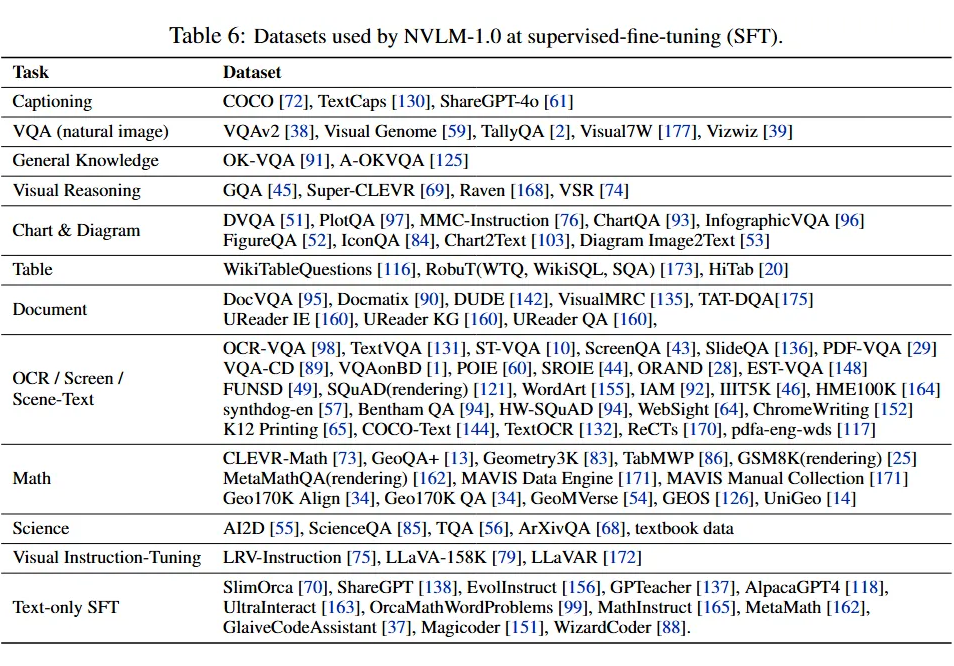
3.3.1 多模态预训练数据

-
图像描述:使用筛选和重新标注后的 LAION-115M 数据集,确保没有不当内容。 -
视觉问答(VQA):自然图像、图表和扫描文档的问答。 -
数学推理:视觉上下文中的数学推理任务。 -
OCR与场景文本识别:涵盖 OCR 任务及其他与文本识别相关的任务。
-
图像描述数据集:如 COCO、TextCaps,还包括 ShareGPT-4o(提供详细图像描述)。 -
自然图像的VQA:包括 VQAv2、Visual Genome,主要关注物体布局、计数、物体级对齐等。 -
图表、图示、表格、文档图像理解:包括 DVQA、PlotQA、WikiTableQuestions、DocVQA 等数据集。 -
OCR任务:涵盖 OCR-VQA、TextVQA、ScreenQA 等数据集,专注于提升 OCR 相关任务表现。 -
数学推理任务:包括 CLEVR-Math、GeoQA+、Geometry3K 等多模态数学推理数据集,显著提高了数学推理能力。
3.3.3 仅文本 SFT 数据
为了保持 LLM 骨干的文本任务表现,并防止灾难性遗忘,NVLM 还设计了一个高质量的仅文本 SFT 数据集,并将其融入到多模态微调阶段。与之前的开源多模态 LLM 不同,NVLM 的文本 SFT 数据集经过了严格筛选和清理,从而确保在文本任务上的表现不受影响。
-
一般类别:如 ShareGPT、SlimOrca、EvolInstruct、GPTeacher、AlpacaGPT4、UltraInteract 等。 -
数学类别:如 OrcaMathWordProblems、MathInstruct、MetaMath 等。 -
代码类别:如 Magicoder、WizardCoder、GlaiveCodeAssistant 等。
3.4 实验结果概述
Note: :所有的实验结果比较均不包含 Qwen2VL。
NVLM-D 1.0 72B:在 OCRBench(853分)和 VQAv2(85.4 分)上表现最佳,远超其他开源和商业模型。它在 MMMU(59.7 分)上的表现也优于所有领先的开源模型。虽然在 AI2D、TextVQA 等任务上略逊于 InternVL-2-Llama3-76B,但依然显著超越其他开源模型,如 Cambrian-1 和 LLaVA-OneVision。
NVLM-H 1.0 72B:在 MMMU(60.2 分)和 MathVista(66.6 分)上表现最好,超过了如 GPT-4o、Gemini Pro 等多款顶尖模型,展示了卓越的多模态推理能力。
NVLM-X 1.0 72B:作为跨注意力机制的模型,NVLM-X 取得了非常优秀的结果,接近尚未发布的 Llama 3-V 70B。同时,其训练和推理速度比 Decoder-only 模型更快。


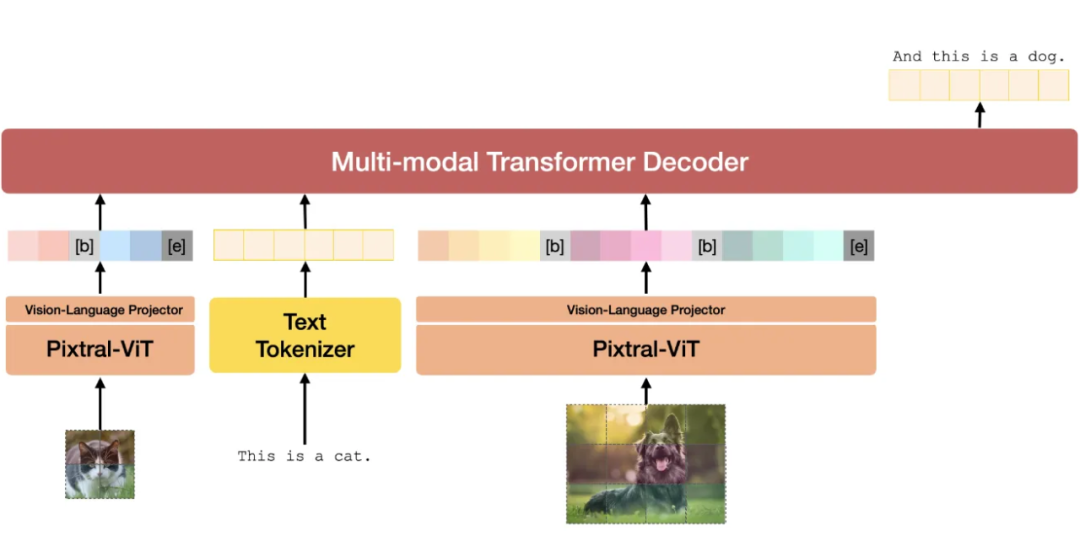
Pixtral 12B的架构
4.1.2 视觉编码器
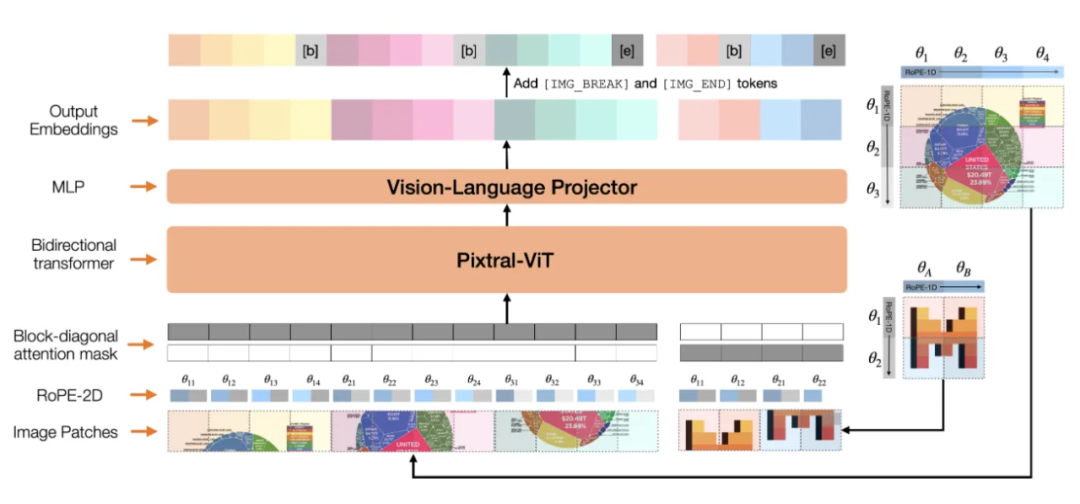
为了让 Pixtral 12B 能够处理图像,开发了全新的视觉编码器 Pixtral-ViT。这个编码器的目标是能够处理各种分辨率和纵横比的图像。Pixtral-ViT 包含了 4 个关键改进:
[IMAGE BREAK] 令牌:为了帮助模型区分相同数量补丁但不同纵横比的图像,在图像行之间加入了 [IMAGE BREAK] 令牌,并在图像序列末尾加上了 [IMAGE END] 令牌。
FFN 中的门控机制:代替标准的前馈神经网络(FFN)层,在注意力模块的隐藏层中使用了门控机制。
序列打包:为了在单次批处理中高效处理图像,图像会沿着序列维度展平,并将其拼接。通过构造块对角掩码,确保来自不同图像的补丁不会发生注意力泄漏。
RoPE-2D:用相对旋转位置编码(RoPE-2D)代替传统的学习型和绝对位置编码来处理图像补丁,这样可以更好地适应不同图像大小。
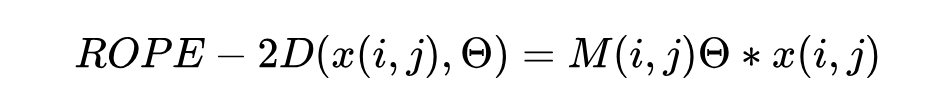
其中,M(i,j)Θ 表示一个与图像位置相关的旋转矩阵。通过此方法,模型能根据补丁的相对位置进行计算,而非依赖绝对位置,从而更好地处理各种图像分辨率和纵横比。
4.2 训练数据没有提及
4.3 实验总览
Pixtral 12B 的表现接近更大规模的开源模型,如 Qwen2-VL 72B 和 Llama-3.2 90B,在公共排行榜上取得了接近这些大型模型的成绩。
在常见的纯文本基准测试中,Pixtral 12B 并没有为了处理多模态任务而牺牲文本理解能力。也就是说,Pixtral 不仅能够处理文本任务,还能处理视觉任务,而且两者之间并不互相妥协,展现了很强的多任务处理能力。


5.1 技术细节
ARIA 采用了细粒度混合专家(MoE)架构,这种架构在大语言模型中逐渐成为计算高效的首选。MoE 的核心思想是将 Transformer 中的每个前馈层(FFN)替换为一组专家,每个专家与 FFN 结构相同。每个输入 token 只会路由到部分专家进行处理,从而实现计算效率的提升。
对于多模态任务,ARIA 采用了大规模的专家数量和较小的 FFN 隐藏维度(与标准 FFN 相比)。具体而言,ARIA 的每个 MoE 层有 66 个专家,其中 2 个专家在所有输入中共享,用于捕捉常见的知识,而每个 token 通过路由模块激活 6 个专家。这种设计能够帮助 ARIA 在处理来自不同数据分布的多模态输入时,充分发挥专家特化的优势。
5.1.2 视觉编码器
-
ViT:ARIA 的 ViT 能够接受按原始长宽比处理的图像,并将其分割为多个 patches,从而保留图像中固有的信息结构。图像根据分辨率被分类为三种类型:中分辨率(最长边为 490 像素)、高分辨率(最长边为 980 像素)和超高分辨率(图像动态分解为多个高分辨率图像)。
-
投影模块:该模块将 ViT 输出的图像嵌入序列转换为视觉 token。投影模块由一个交叉注意力层和一个 FFN 层组成,交叉注意力层使用可训练的向量作为查询,并将图像嵌入作为键。针对不同分辨率的图像,分别使用 128 个查询(中分辨率图像)和 256 个查询(高分辨率图像),最终生成的视觉 token 传递给 MoE 解码器进行处理。
5.2 训练流程
5.2.1 语言预训练
ARIA 的第一阶段是语言预训练,使用大量的语言数据进行 MoE 解码器的训练,loss 为 next token prediction loss。此阶段的上下文窗口长度为 8K tokens。
第二阶段进行 MoE 解码器和视觉编码器的多模态预训练。此阶段的目标是使模型具备广泛的多模态理解能力,同时保持或提升语言理解能力。
语言数据:包含 1 万亿 tokens 的高质量子集,覆盖了代码、推理和知识等主题。
-
交织的图像-文本网页数据:从 Common Crawl 提取并过滤网页,确保图像和文本的质量,最终筛选出 190B 交织图像-文本 tokens。 -
合成图像描述:通过小型模型重写网页图像的 alt 文本,生成更长、更具描述性的图像描述,共为 300M 张图像创建了70B多模态 tokens。 -
文档转录与 QA:使用 OCR 方法将文档图像转录为文本,并使用语言模型生成问题-回答对,增强模型对文本内容的理解,总数据量为 102B tokens。 -
视频描述与 QA:从多个来源收集了 440 万段视频,为每段视频生成逐帧密集描述,并用语言模型生成问题-回答对,总视频数据包含 35B tokens。
5.2.3 多模态长序列预训练
在此阶段,ARIA 进行长序列预训练,扩展模型的上下文窗口至 64K tokens。此阶段使用语言和多模态长序列数据,包括长视频、长文档以及由短序列数据合成的长序列。
数据:包括 12B 语言 tokens 和 21B 多模态 tokens,其中 69% 的数据为长序列。该阶段增加了 RoPE 基础频率超参数从 100K 到 5M。
5.2.4 多模态后训练
最后阶段是多模态后训练,主要聚焦于改善模型的问答和指令跟随能力。此阶段使用高质量的开源数据集和人工标注的数据集,覆盖多模态、代码、数学和推理等领域。
5.3 实验总结
ARIA 在多模态、语言和编码任务上,表现优于其他开放模型(如 Pixtral-12B 和 Llama3.2-11B)。
ARIA 在遵循指令(例如执行复杂任务)方面优于其他开放模型,表现突出。

总结
近期多模态大模型的发展依然很快,很多的大公司开出了自己的新模型,但是架构方面依然以 Llava 的架构居多,虽然英伟达讨论了其他架构的优势,但是仍然不是主流的观点。除此之外,各家在视觉编码器,训练数据上都下了很大功夫,包括搜集更多的数据,寻求更高的标注质量,做到完全开源等。
更多阅读

#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

(文:PaperWeekly)