
项目简介
-
Agent Laboratory 是一个端到端的自主研究工作流程,旨在协助您作为人类研究人员实现您的研究想法。Agent Laboratory 由由大型语言模型驱动的专业代理组成,支持您完成整个研究工作流程——从进行文献综述和制定计划,到执行实验和撰写综合报告。
-
该系统并非旨在取代您的创造力,而是为了补充它,使您能够专注于创意和批判性思维,同时自动化重复且耗时的任务,如编码和文档编写。通过适应不同水平的计算资源和人类参与,Agent Laboratory 旨在加速科学发现并优化您的研究生产力。
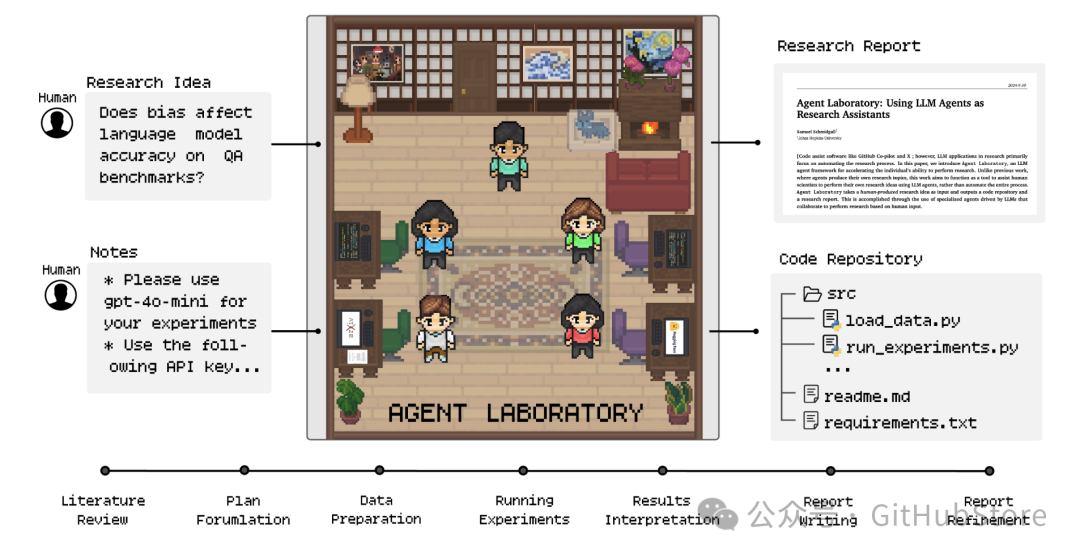
🔬 Agent Laboratory 如何工作?
-
Agent Laboratory 包含三个主要阶段,系统地引导研究过程:(1)文献综述,(2)实验,(3)报告撰写。在每个阶段,由大型语言模型驱动的专业代理协作完成不同的目标,整合了如 arXiv、Hugging Face、Python 和 LaTeX 等外部工具以优化结果。这一结构化的工作流程始于独立收集和分析相关研究论文,经过协作计划和数据准备,最终实现自动化实验和综合报告生成。论文中讨论了具体代理角色及其在这些阶段的贡献。

🖥️ 安装
Python 虚拟环境选项
-
克隆 GitHub 仓库:首先使用以下命令克隆仓库:
git clone git@github.com:SamuelSchmidgall/AgentLaboratory.git
2. 设置并激活 Python 环境
python -m venv venv_agent_lab-
现在激活此环境:
source venv_agent_lab/bin/activate3. 安装所需库
pip install -r requirements.txt4. 安装 pdflatex [可选]
sudo apt install pdflatex-
这使得代理能够编译 latex 源代码。
-
[重要] 如果由于没有 sudo 权限而无法运行此步骤,可以通过将
--compile_latex标志设置为 false 来关闭 pdf 编译:--compile_latex=False -
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA"或者,如果您没有安装 pdflatex
python ai_lab_repo.py --api-key "API_KEY_HERE" --llm-backend "o1-mini" --research-topic "YOUR RESEARCH IDEA" --compile_latex=False
5. 现在运行 Agent Laboratory!
提高研究成果的技巧
[技巧 #1] 📝 确保写下详尽的笔记!📝
写下详尽的笔记非常重要,帮助您的代理理解您在项目中希望实现的目标,以及任何风格偏好。笔记可以包括您希望代理执行的任何实验、提供 API 密钥、希望包含的特定图表或图形,或任何您希望代理在进行研究时了解的内容。
这也是您让代理知道它可以访问的计算资源的机会,例如 GPU(数量、类型、内存大小)、CPU(核心数量、类型)、存储限制和硬件规格。
为了添加笔记,您必须修改 ai_lab_repo.py 中的 task_notes_LLM 结构。以下是我们的一些实验中使用的笔记示例。
task_notes_LLM = [{"phases": ["plan formulation"],"note": f"You should come up with a plan for TWO experiments."},{"phases": ["plan formulation", "data preparation", "running experiments"],"note": "Please use gpt-4o-mini for your experiments."},{"phases": ["running experiments"],"note": f"Use the following code to inference gpt-4o-mini: \nfrom openai import OpenAI\nos.environ["OPENAI_API_KEY"] = "{api_key}"\nclient = OpenAI()\ncompletion = client.chat.completions.create(\nmodel="gpt-4o-mini-2024-07-18", messages=messages)\nanswer = completion.choices[0].message.content\n"},{"phases": ["running experiments"],"note": f"You have access to only gpt-4o-mini using the OpenAI API, please use the following key {api_key} but do not use too many inferences. Do not use openai.ChatCompletion.create or any openai==0.28 commands. Instead use the provided inference code."},{"phases": ["running experiments"],"note": "I would recommend using a small dataset (approximately only 100 data points) to run experiments in order to save time. Do not use much more than this unless you have to or are running the final tests."},{"phases": ["data preparation", "running experiments"],"note": "You are running on a MacBook laptop. You can use 'mps' with PyTorch"},{"phases": ["data preparation", "running experiments"],"note": "Generate figures with very colorful and artistic design."},]
[技巧 #2] 🚀 使用更强大的模型通常会带来更好的研究 🚀
在进行研究时,模型的选择会显著影响结果的质量。更强大的模型往往具有更高的准确性、更好的推理能力和更优秀的报告生成能力。如果计算资源允许,优先使用先进的模型,如 o1-(mini/preview) 或类似的最先进大型语言模型。
然而,在性能和成本效益之间取得平衡也很重要。虽然强大的模型可能会产生更好的结果,但它们通常更昂贵且运行时间更长。考虑选择性地使用它们,例如用于关键实验或最终分析,同时在迭代任务或初步原型设计中依赖较小、更高效的模型。
当资源有限时,通过在您的特定数据集上微调较小的模型或将预训练模型与特定任务的提示相结合来优化,以实现性能与计算效率之间的理想平衡。
[技巧 #3] ✅ 您可以从检查点加载之前的保存 ✅
如果您丢失了进度、互联网连接中断或子任务失败,您始终可以从先前的状态加载。 您的所有进度默认保存在 state_saves 变量中,该变量存储每个单独的检查点。只需在运行 ai_lab_repo.py 时传递以下参数
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA" --llm-backend "o1-mini" --load-existing True --load-existing-path "save_states/LOAD_PATH"
[技巧 #4] 🈯 如果您使用非英语语言运行 🈲
如果您使用非英语语言运行 Agent Laboratory,没问题,只需确保向代理提供一个语言标志,以便用您喜欢的语言进行研究。请注意,我们尚未广泛研究使用其他语言运行 Agent Laboratory,因此请务必报告您遇到的任何问题。
例如,如果您使用中文运行:
python ai_lab_repo.py --api-key "API_KEY_HERE" --research-topic "YOUR RESEARCH IDEA (in your language)" --llm-backend "o1-mini" --language "中文"
[技巧 #5] 🌟 还有很大的改进空间 🌟
这个代码库还有很大的改进空间,因此如果您进行了更改并希望帮助社区,请随时分享您所做的更改!我们希望这个工具对您有帮助!
项目链接
https://github.com/SamuelSchmidgall/AgentLaboratory
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)