

400多刀就能训练一个可以挑战o1的开源大模型?
Berkeley 做到了!

UC Berkeley的天才们再次证明:成本并不是限制AI发展的关键。
他们发布的Sky-T1-32B-Preview模型在多个基准测试中与OpenAI的o1-preview平分秋色。
让我们来揭秘这个「平民版o1模型」背后的技术细节。
强悍的性能指标
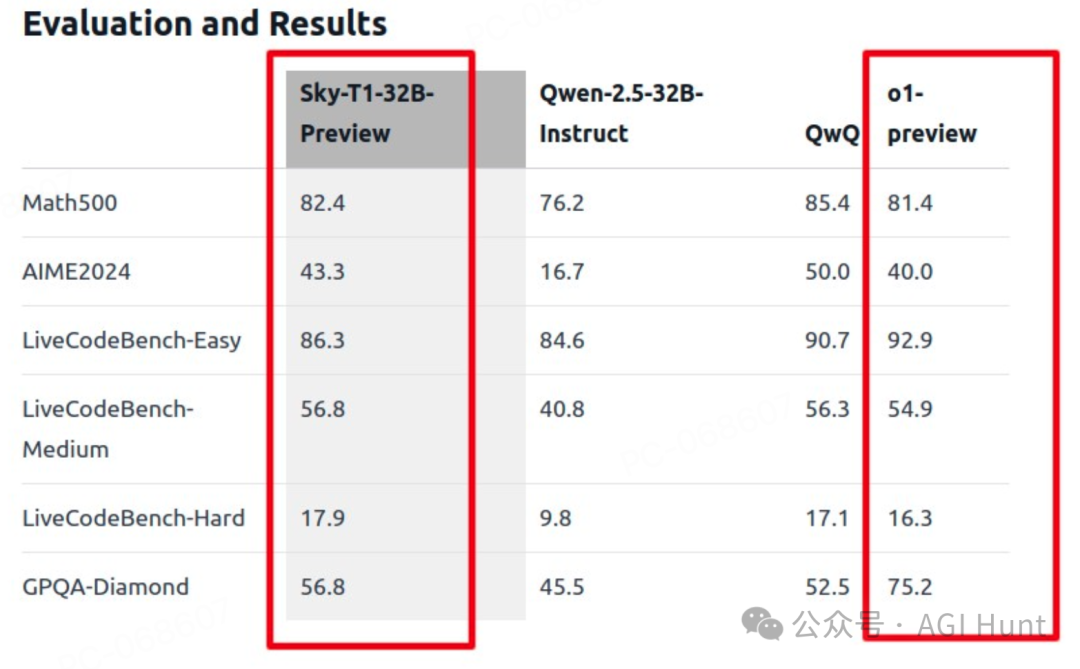
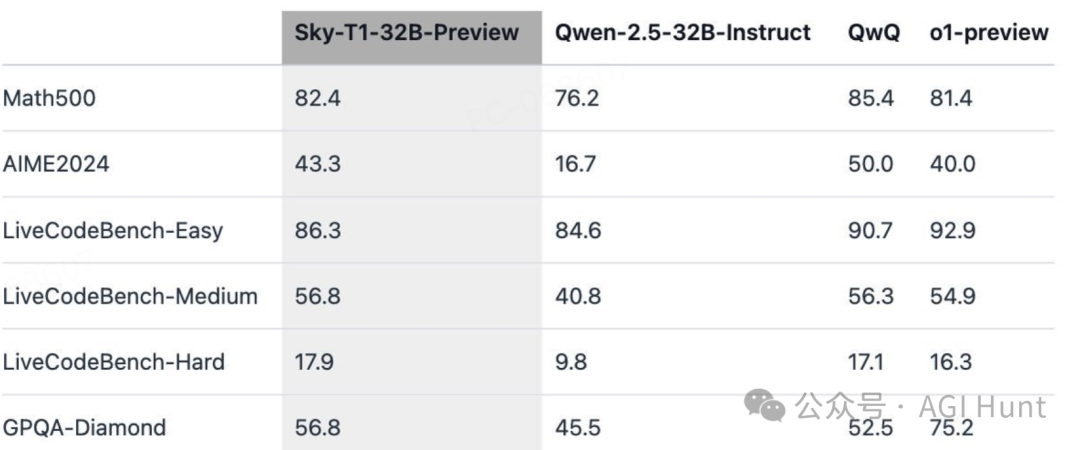
从评估结果来看,Sky-T1不仅没有辱没Berkeley的名声,反而展现出惊人的实力:
-
Math500测试中得分82.4,不仅超过了Qwen的76.2分,还高于o1-preview的81.4分
-
AIME2024考试中得分43.3,与o1-preview的40.0分不相上下
-
LiveCodeBench系列测试中表现出色:
-
Easy级别:86.3分 -
Medium级别:56.8分 -
Hard级别:17.9分 -
GPQA-Diamond中拿到56.8分,虽然低于o1的75.2分,但已经超越了基础模型
训练方法大揭秘
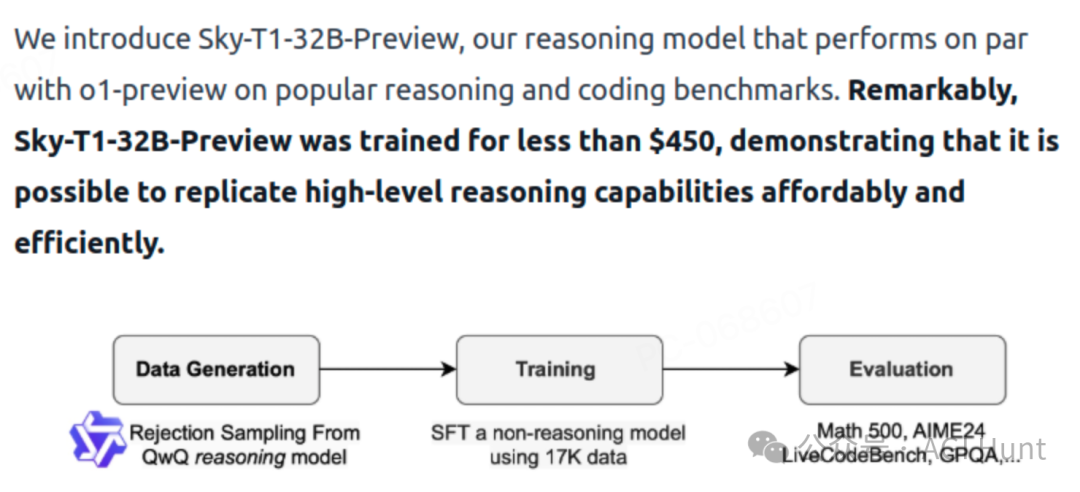
Berkeley的研究团队采用了三步走战略:
第一步:数据是关键
他们使用了一个巧妙的数据筛选机制:
-
使用QwQ-32B-Preview生成初始数据
-
采用拒绝采样提升数据质量
-
通过GPT-4o-mini重写数据格式
-
最终筛选出17K条高质量数据:
-
5K条来自APPs和TACO的编程数据 -
10K条来自AIME、MATH和NuminaMATH的数学题 -
1K条来自STILL-2的科学和谜题数据
第二步:高效训练
团队选择了Qwen2.5-32B-Instruct作为基础模型,采用以下参数:
-
3轮训练
-
学习率1e-5
-
批次大小96
-
使用DeepSpeed Zero-3 offload
-
8台H100 GPU
-
19小时训练时间
-
总成本不到450美元
第三步:全面评测
研究过程中,团队发现了几个重要规律:
模型规模很重要:
-
7B和14B的小模型效果不理想
-
以Qwen2.5-14B为例,在LiveCodeBench上只从42.6%提升到46.3%
-
32B以下的模型容易出现重复内容
数据配比很关键:
-
单纯用3-4K数学题训练,AIME24准确率达43.3%
-
加入编程数据后,准确率降到36.7%
-
最终通过均衡数据,在两个领域都取得了好成果
开源造福社区
NovaSky团队完全开源了所有资源:
-
基础设施:集成了数据构建、训练和评估的完整代码库
-
训练数据:17K条精选数据集
-
技术报告:包含wandb训练日志
-
模型权重:完整的32B模型参数
未来展望
Berkeley团队表示,这只是他们在开源推理模型领域的第一步。他们计划:
-
开发更高效的模型
-
探索新技术提升测试时的效率和准确性
这个项目证明了:高水平AI研发不需要天价预算。
它为众多想要进入AI领域但苦于资源限制的研究者和开发者带来了新的希望。
相关链接
技术博客
Sky-T1: Train your own O1 preview model within $450
https://novasky-ai.github.io/posts/sky-t1/
模型权重
https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
(文:AGI Hunt)