

《Current Best Practices for Training LLMs from Scratch》是由Weights & Biases(W&B)提供的一份关于从头开始训练大型语言模型(LLMs)的权威指南。这份白皮书深入剖析了LLMs训练的最佳实践,内容覆盖了从数据收集与处理、模型架构选择、训练技巧与优化策略,到模型评估与部署等各个环节。
核心内容:
-
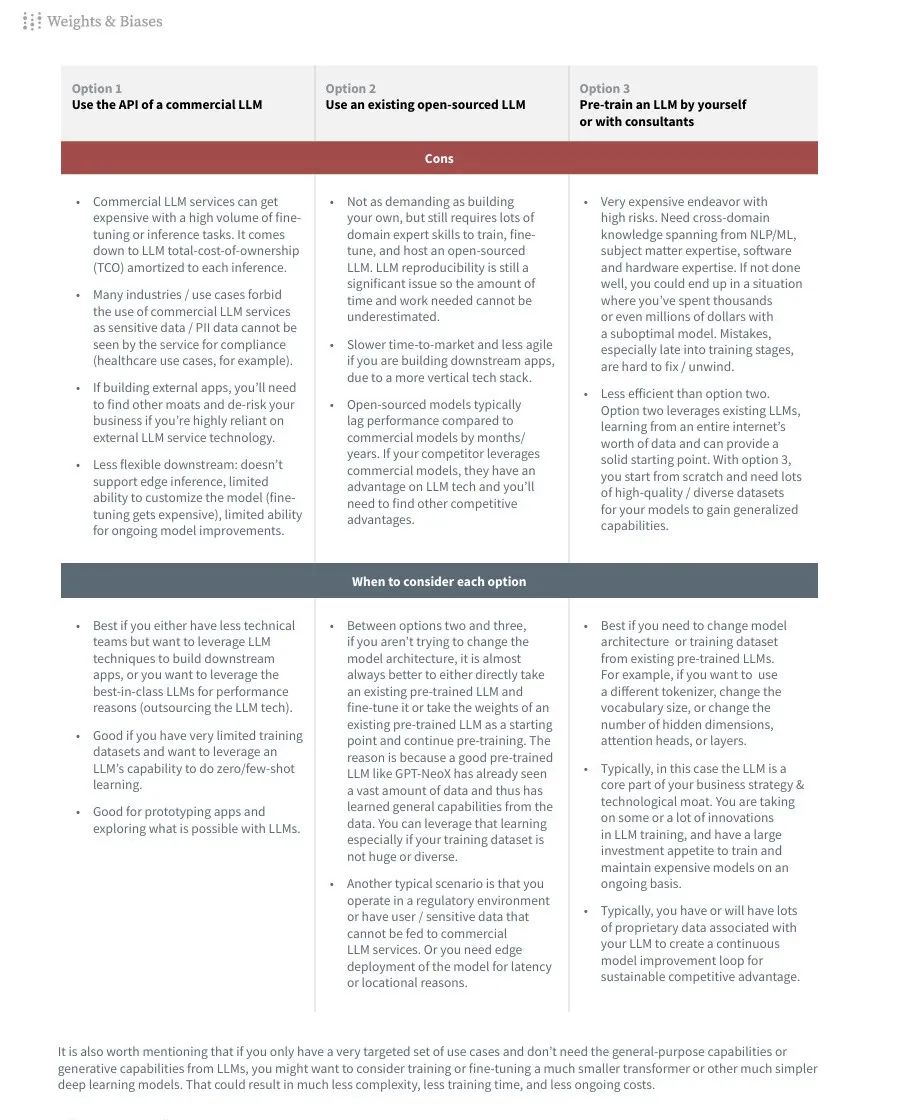
是否从头开始训练LLM:指南首先讨论了是否应该自己从头开始训练一个LLM,还是使用现有的商业API或开源LLM。
-
训练LLM的三种基本方法:
-
使用商业LLM的API,例如GPT-3。
-
使用现有的开源LLM,例如GPT-J。
-
自己预训练LLM,可以是自己管理训练或雇佣LLM顾问和平台。
-
模型和数据集的扩展性:介绍了LLMs的扩展性,包括模型大小和训练数据量的平衡,以及如何根据训练计算预算和推理延迟要求确定模型和数据大小的最佳组合。
-
并行训练技术:讨论了在训练过程中可能使用的并行技术,如张量并行、数据并行和流水线并行。
-
训练中的挑战和策略:包括硬件故障、训练不稳定性等问题,以及如何应对这些问题的策略,例如批大小、学习率调度、权重初始化等。
-
基于人类反馈的强化学习(RLHF):介绍了如何通过人类反馈来优化模型性能,特别是在模型表现出不期望的行为时。
01
资源目录
阅读这份白皮书,读者将能够掌握LLMs训练的基本原理和关键技术,了解如何收集、处理和优化训练数据,学会选择合适的模型架构和训练策略,掌握训练过程中的优化技巧和性能提升方法,以及了解如何评估LLMs的性能并将其部署到实际应用中。
扫码领取资源
长按识别下方二维码,添加微信领取
添加时备注:大模型白皮书(资源编码)
即可获得网盘下载地址

(如遇添加频繁请等会再试)
如需其他AI相关资料,请扫码索取~
02
大模型前沿系列课
大语言模型的迅猛发展引起了世界各国学术界高度重视,掌握大模型发展俨然是人工智能未来的趋势,大型语言模型(LLM)的发展正朝着更大规模、更专业和更安全的方向发展,同时也在探索如何更好地集成到各种业务流程和应用中。
所以我联合多位QS前50大佬做了最新的大模型实战系列课,原价699元,现在0元领取!
扫码解锁最新大模型实战课
(如遇添加频繁请等会再试)
如需其他AI相关资料,请扫码索取~

03
大模型顶会idea
写论文最怕的就是没有创新点,“创新点”是一篇论文的灵魂,而因为这个理由拒稿意味着整篇论文的价值被否定。
很多同学陷入了写论文困境,其实很大原因是因为创新点不足,特别是已经很多创新不足被拒稿的同学,要花费大量的时间来重新立意,然后从头开始去重建自己的论文逻辑。

我整理了QS前50名大佬的部分现成顶会大模型idea,很多现有大模型idea可冲一区,让大佬直接带飞!拼手速!手慢无!
1V1与大佬meeting
速抢你的顶会idea
滑动查看大模型idea

04
大模型限时免费用
沃恩智慧是人工智能科研辅导行业中唯一一家受邀参会的公司,沃恩也在会上展示了他们的沃研Turbo大模型。
这次我给大家申请到特别的福利——沃恩智慧研发的沃研Turbo大模型限时免费使用福利,直接扫码,获取限时免费福利!
扫码解锁最新大模型实战课
(如遇添加频繁请等会再试)
如需其他AI相关资料,请扫码索取~
(文:PaperWeekly)