


痛点
-
企业如何构建适合自己领域的大模型?
-
如何灵活地根据业务需要来生成评测集,进而充分发挥企业内部数据的价值?
-
如何通过标准化人工评测流程来减少人工的主观性?
-
如何自动化地发现评测集生成过程中的低质量的 QA 对和评分?

我们建立了一套依赖于争议度分析和评分波动分析来自动纠正人工的主观性错误的人工评测框架 “LalaEval”,可以成功根据业务场景来动态生成高质量的 QA 对,进而指导领域大模型的构建和大模型的迭代优化。
2.1 特点
1. 建立了端到端的领域大模型评测体系,弥补货运领域大模型评测空白。
2. 定义了框架设计、题库建设、评分、结果输出等各个环节的关键步骤,使方案在不同领域可拓展性高。
3. 使用单盲测试原理,保证评分客观、公正。
4. 建立了评分争议度、题目争议度、评分波动性三大分析框架,自动化实现评分结果质检、低质量 QA 对二次识别和评分波动原因量化归因。

论文链接:
LalaEval 一共分为五部分:领域范围界定、能力指标构建、评测集生成、评测标准制定、结果统计分析。下图是这五个部分如何部署运作的总览。
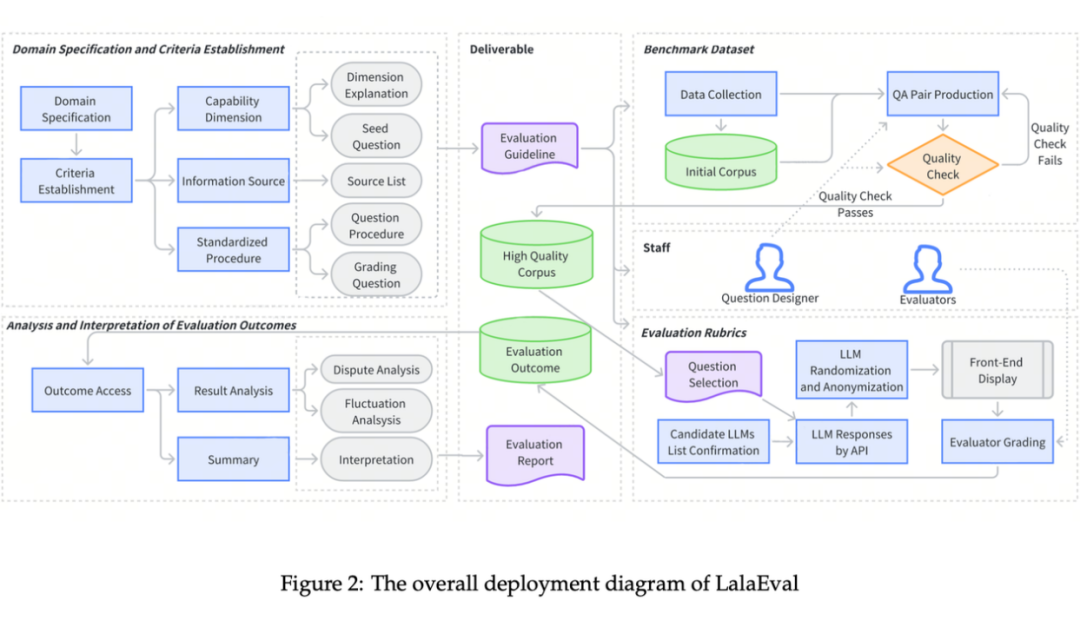

领域范围界定
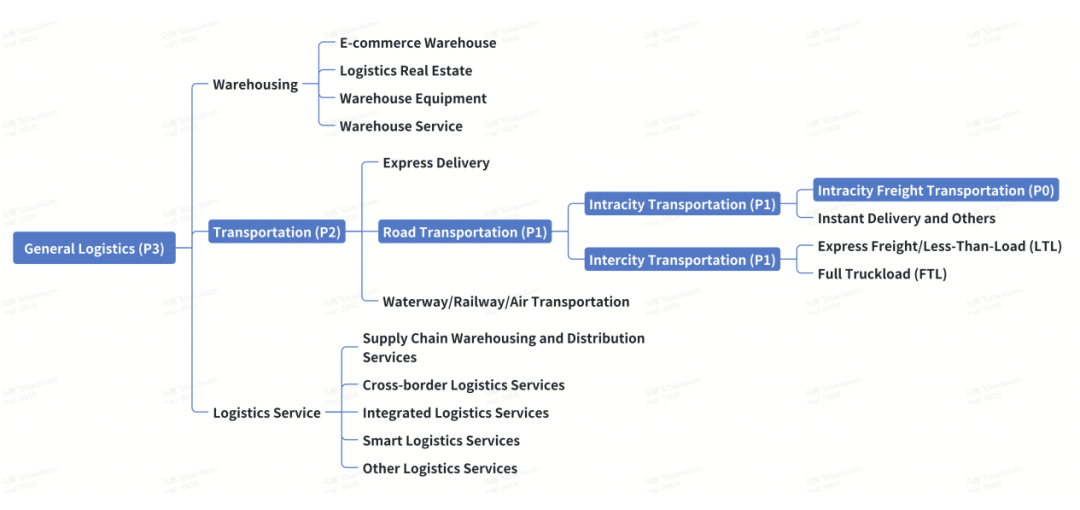
3.1 后向归纳法
遵循 MECE 原则(Mutually Exclusive, Collectively Exhaustive 相互独立,完全穷尽), 从最底层的子领域(例如,Intracity Freight Transportation,同城货运)逐步上升到包含更广泛的子域。
我们的核心业务是“同城货运”,所以“同城货运”优先级最高(P0),后续构建评测集中所占的数量比重也最高;距离“同城货运”越远,优先级越低。

能力指标构建
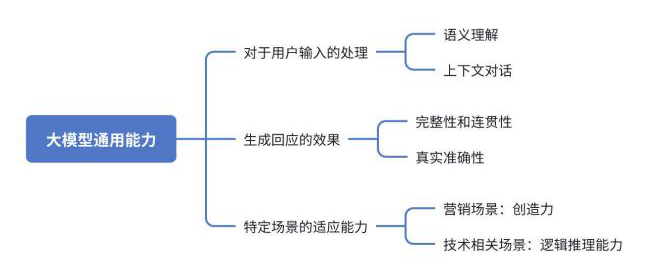
4.1 通用能力
选取指标的逻辑
具体指标
-
语义理解 -
上下文对话 -
回答的完整性和连贯性 -
事实准确性 -
创造力 -
逻辑推理
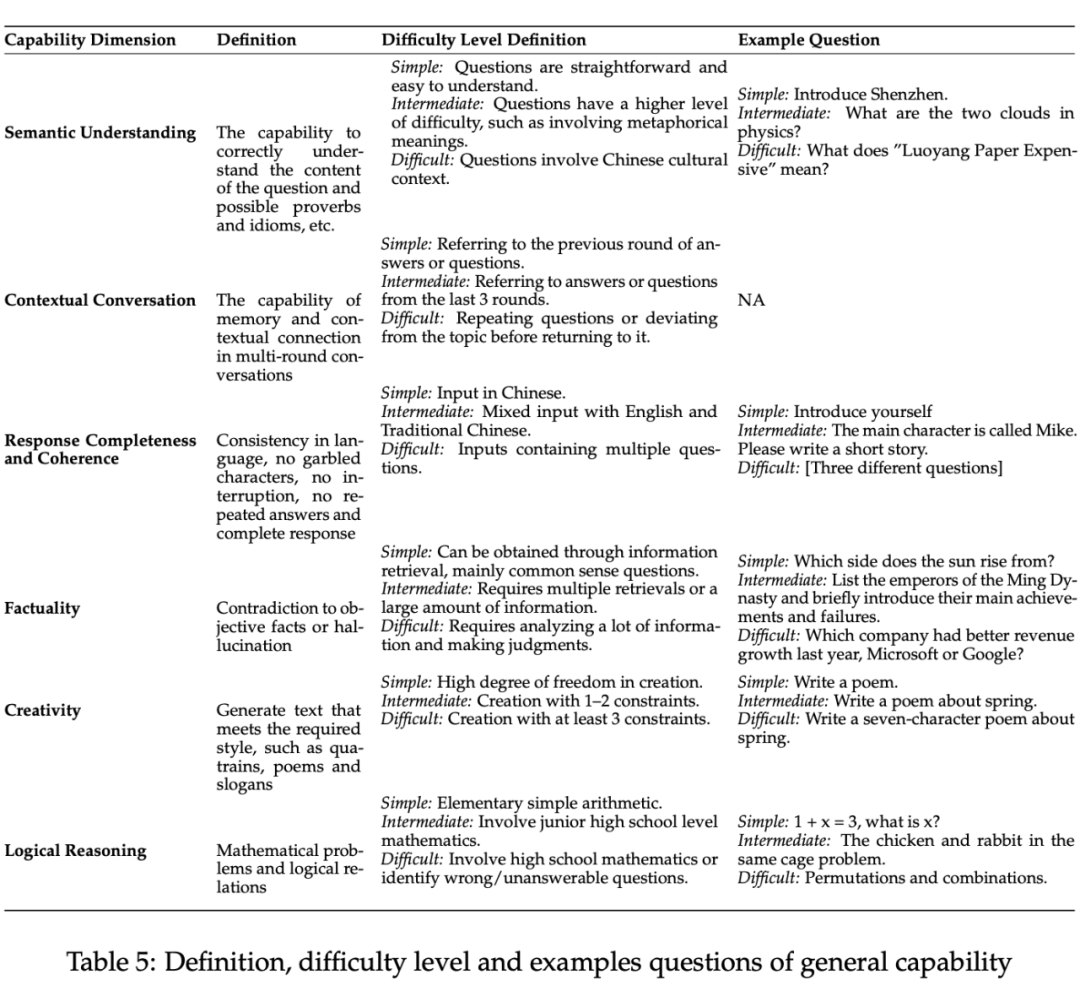
选取指标的逻辑
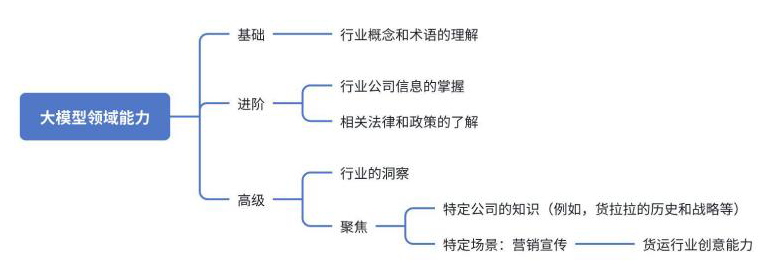
具体指标
-
概念和术语理解
-
公司信息
-
法律和政策知识
-
行业洞察
-
公司特定知识
-
物流环境中的创造能力
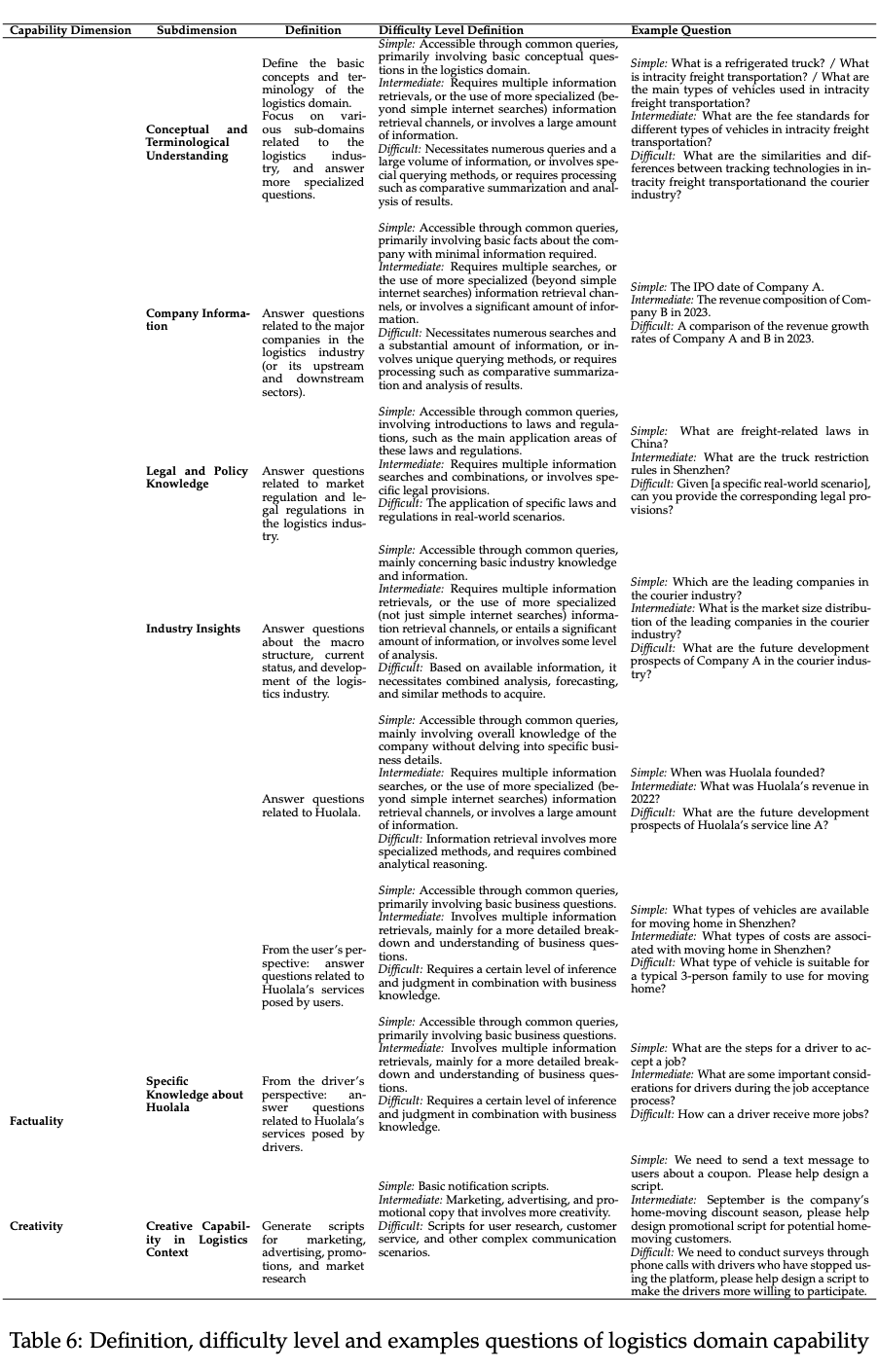

根据领域范围的界定,按领域整理信息源,确保原始语料来源可追溯,质量达标。
-
问答计划的制定:规划所需数量的 QA 对,并按难度级别和能力维度进行分类。
-
出题人的选择:应具备深入理解评测框架的能力。
-
QA 对的创建:一个 QA 对需要包含:一个问题、对应的标准答案、信息来源。确保可追溯性和可信度。
5.3 质检和入库
进行全面的 QA 对质量检查,未能达标的 QA 对要进行改进。

评测标准制定
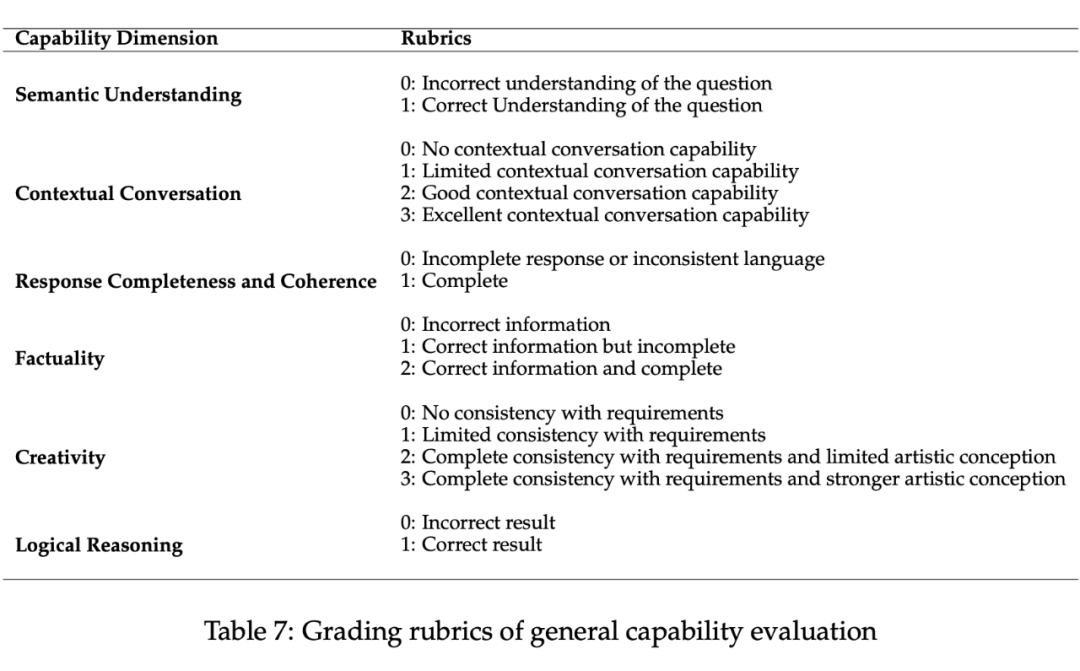
6.1打分标准
具体标准:
1. 评分标准为 0~3 分
-
0 分:有错误信息
-
1~3 分:衡量回答的正确性、完整性、创造性等
细则如下:

我们采用单盲评测来保障公平性,不同模型生成的回应是以随机顺序呈现给评测员。

评测员的选拔:评估员应从具有领域专业知识的候选人池中选出。
培训方法:采用基于示例的培训方式。
试评测:此过程中,应判断是个别评估员的问题,还是评估标准存在模糊之处。
评测质量保证:对于题目评分不一致的评测员,提供更多示例以帮助澄清评测标准,直至达标。
部署标准:评测员在试评测中达到一致性阈值后,才会将其部署到实际生产环境中。

结果统计分析
7.1 评分计算
1. 汇总的得分表格如下,AS_jki 为在 j 能力维度下,评测员 i 对于问题 k 的打分,取值范围 [0, 3]。

-
针对模型 q 的能力维度 j (比如模型 GPT-4 的语义理解能力)来说,模型得分 Score(qj) = 模型的总得分(所有评测员对于所有题目的评分直接加和)除以分数上限。这将 Score(qj) 归一化到 [0, 1] 区间内,如果任何评测员对于任何题目都给出满分:Score(qj) = 1 。模型总得分 Score(q) 为 Score(qj) 的平均。
7.2 争议度分析
-
如果一个评测员的打分与“多数人的打分”不一致,就视为“争议打分”,找出“争议打分”较多的评测员,如果判断确实是评测员的问题,则进行二次宣导,考虑当次打分作废。
-
评分人争议度 = “争议打分”的数量 / 这个评分人的总打分数量
-
“题目争议度”由“题目歧义度”和“争议打分比例”加权平均而来。 -
如果一个 QA 对,一半人打出了“争议打分”,也就是对于某个题目 k 和某个模型 q 的回答:“多数人的打分”数量 ≈ “争议打分”数量,这道题就被认为是“歧义”。“题目歧义度” = 遍历每个模型的回答,被认为“歧义”的次数。 -
“争议打分比例” = 这个题目遭遇到的“争议打分”的数量 / 被打分的总数量 -
列出争议度前几的题目,如果 QA 对的质量不达标,则将题目作废,并对出题人就出题标准进行二次宣导。
7.3 评分波动分析
若同一模型前后两次评测产生了较大的分数变化,则需要对变化做出归因及解释。
1. 波动原因拆解:按照 MECE 原则,拆解成 4 种原因——题目本身变化、模型自身回答变化、同一评分人的评分不一致、评分人变更。
2. 应对措施:
-
题目本身变化:若评分波动源于引入新题目,可能是这些新题目与先前题目存在显著差异。此时需分析和优化具体题目,以确保题目的质量和一致性。
-
模型自身回答变化:若同一题目,模型的回答发生变化,这可能表明题目在大模型的理解中存在歧义。此时需对题目进行优化,以消除歧义。
-
同一评分人的评分不一致:需与评分人进行深入沟通,找出评分差异的根本原因,并进行必要的修正。
-
评分人变更:若评分人发生变更,需对新评分人进行系统化培训,确保其熟悉评分标准和流程。
3. 按「QA 对的 Q 和 A 是否相同」、「评分人是否相同」可拆解成 6 种情况。分别计算这 6 种情况下前后两次评分差异,再进行一定聚合,便可量化 4 种波动原因对总评分变化的贡献。
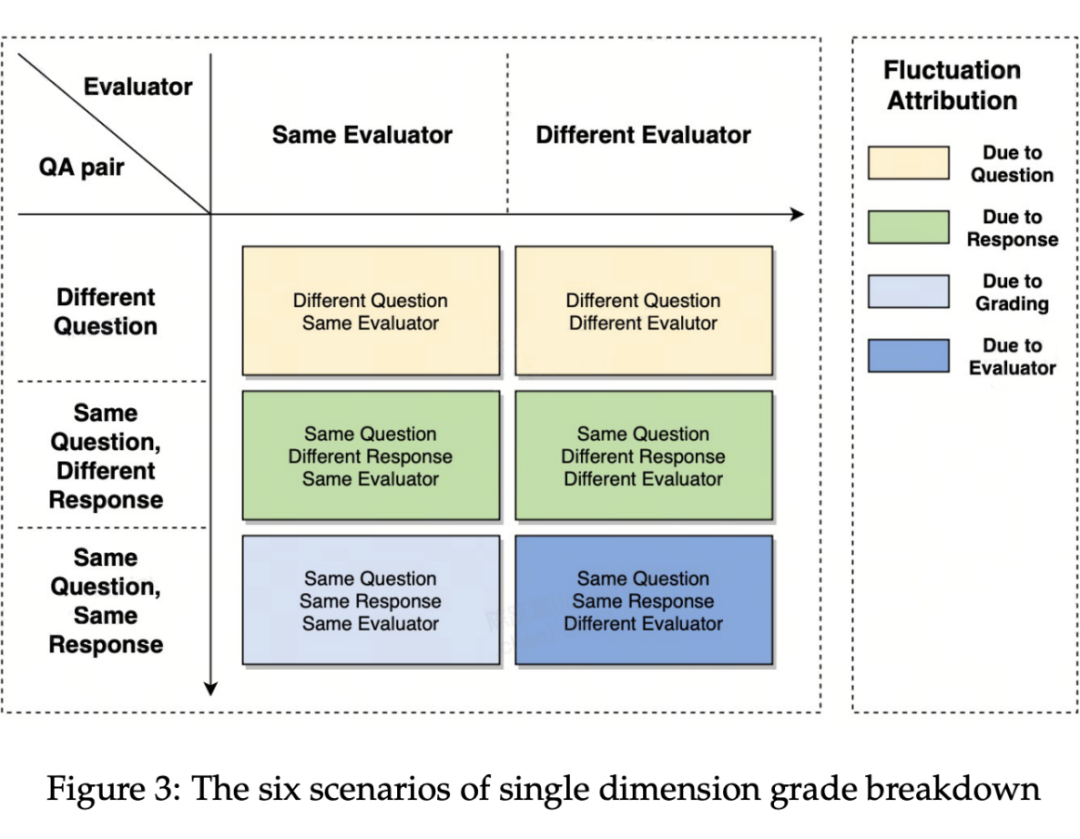

结果呈现
参与测评的模型包括 OpenAI 的 GPT-4(无网络访问)、百度的文心一言(有网络访问),PLLM1/2/3 是基于 ChatGLM2-6B 基础模型的不同版本,分别通过网络访问、RAG,和两者的组合进行微调。
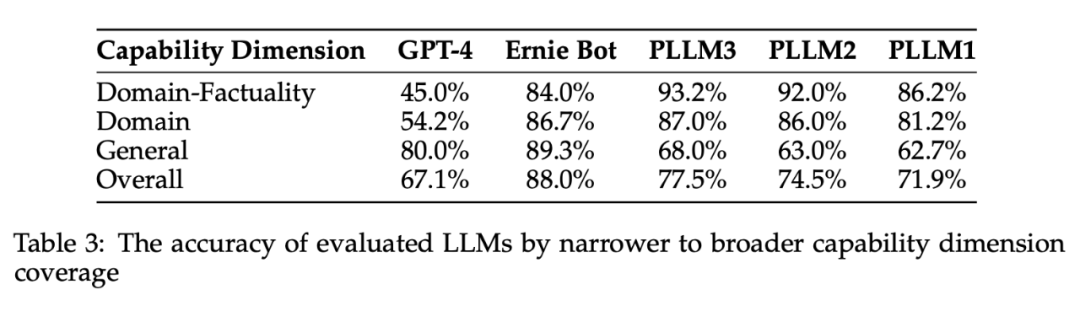
8.1 评估结果
1. 模型的准确性(Table 3):在不同能力维度上取得非零评分的回答比例。
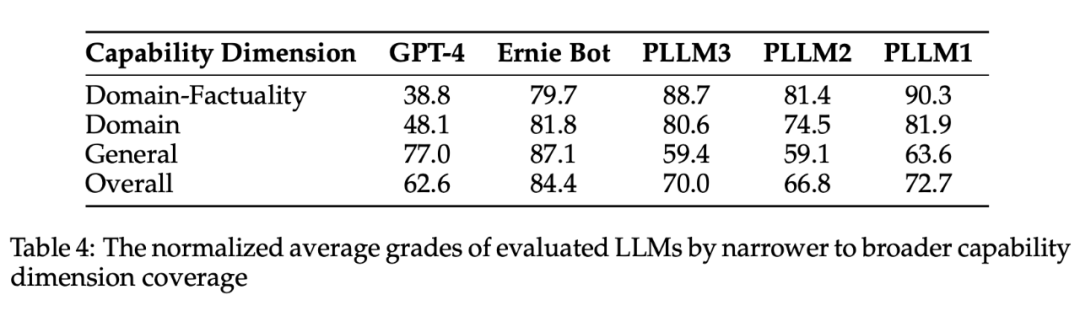
2. 归一化后的平均分数(Table 4):
3. 按比例将分数归一化到 [0, 100](Table 9):
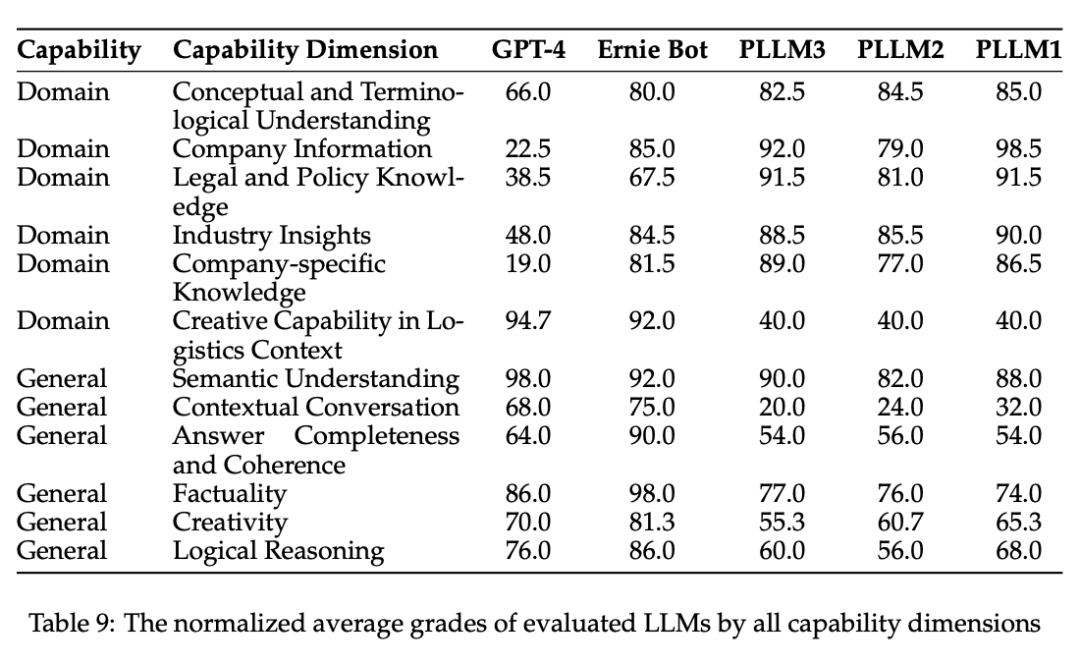
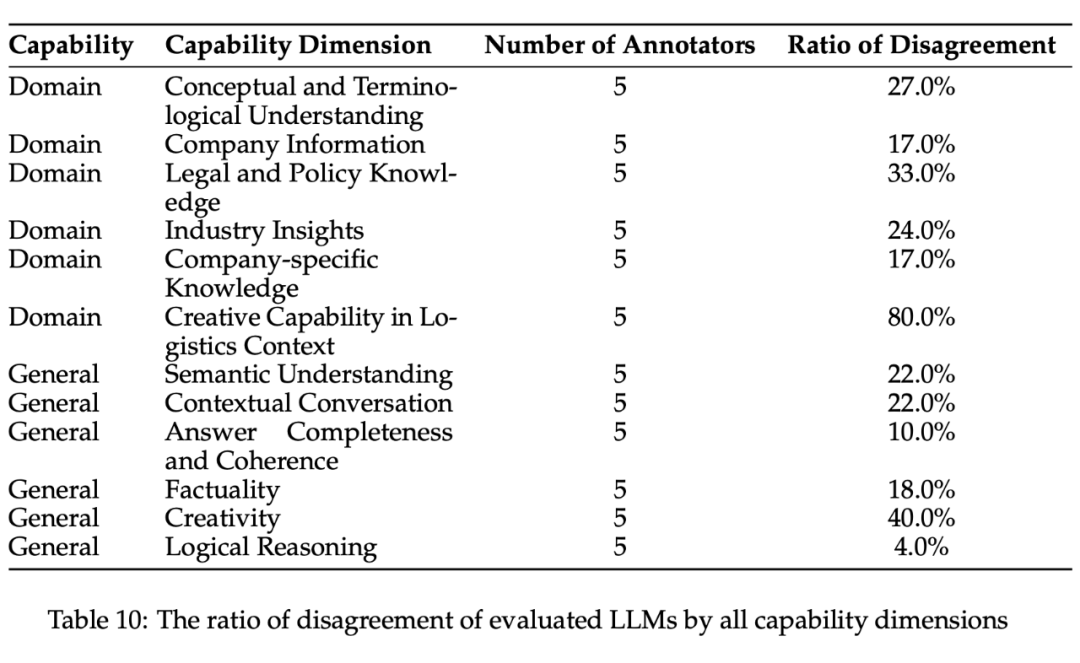
4. 各个能力维度的分歧度(Table 10):分歧度越高,说明评测员的打分越难形成一致的共识。创造力相关的能力分歧度最高,说明每个人对于创造力的理解不一致。

总结
领域范围界定:MECE 原则、后向归纳法、定性优先级划分。
能力指标构建:6 个通用能力指标,6 个领域能力指标。
评测集生成:原始语料积累、QA 对生成、质检和入库。
评测标准制定:打分标准(0~3分)、单盲测试、评测员的培训。
结果统计分析:评分计算、争议度分析(评分人和题目)、评分波动分析。
(文:PaperWeekly)