

开源大模型的开花板又被击穿了!

MiniMax团队突然放出了一个「重磅炸弹」——MiniMax-Text-01!
这个拥有4百万token上下文窗口的开源模型直接把各路大佬打了个措手不及!
最惊人的是,它不仅能吊打DeepSeek V3,还带来了一系列让人眼前一亮的「黑科技」。
「怪兽」级的参数量
这个「巨无霸」模型究竟有多强?来看看这些数据:
-
总参数量:惊人的456B!
-
每个token激活参数:45.9B
-
训练上下文长度:100万token
-
推理上下文长度:高达400万token!
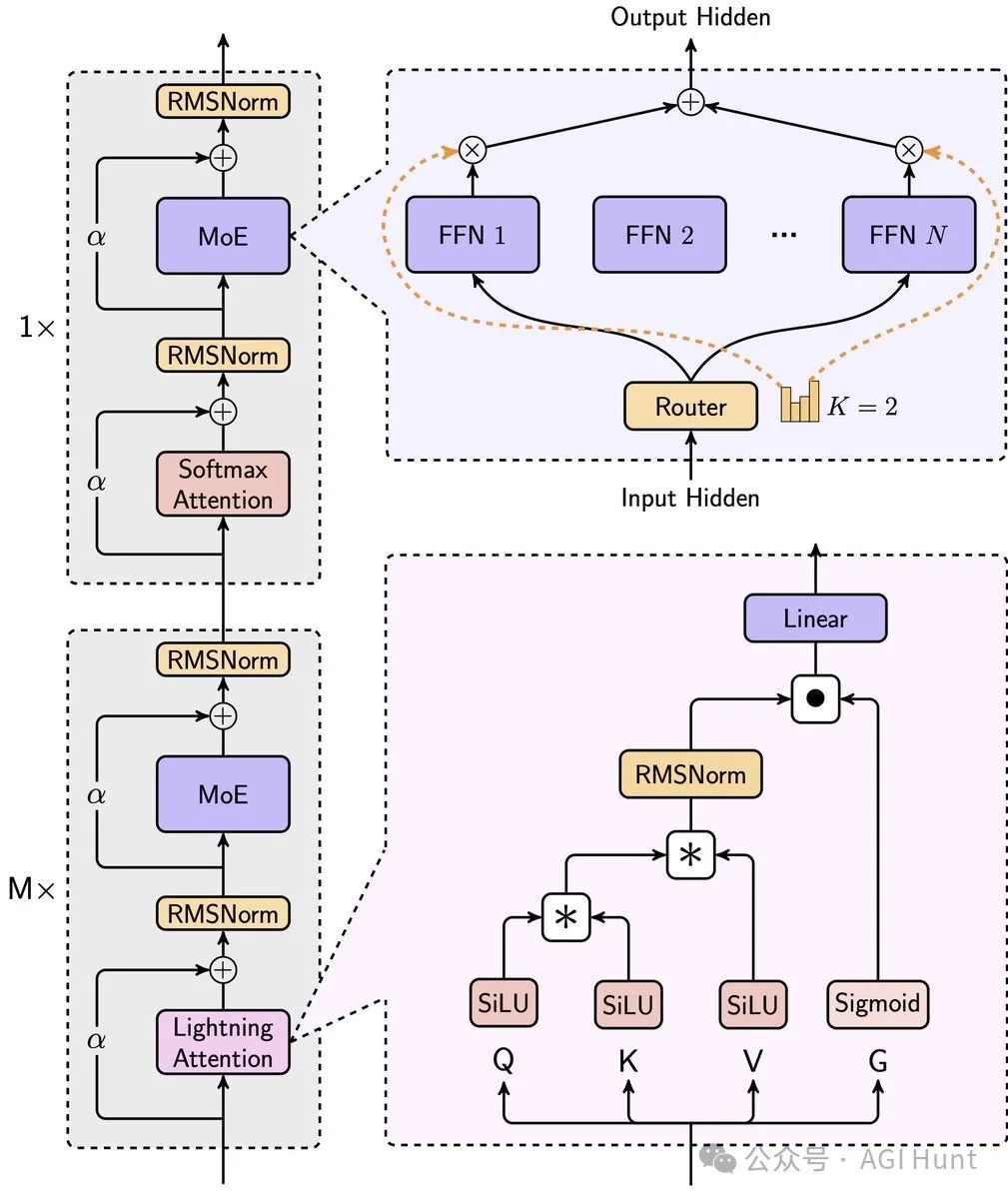
更厉害的是,它采用了一个「混合架构」:
-
Lightning Attention
-
Softmax Attention
-
专家混合系统(MoE)
这些技术的组合让模型既保持了强大的性能,又能高效处理超长文本。
实力有多强?
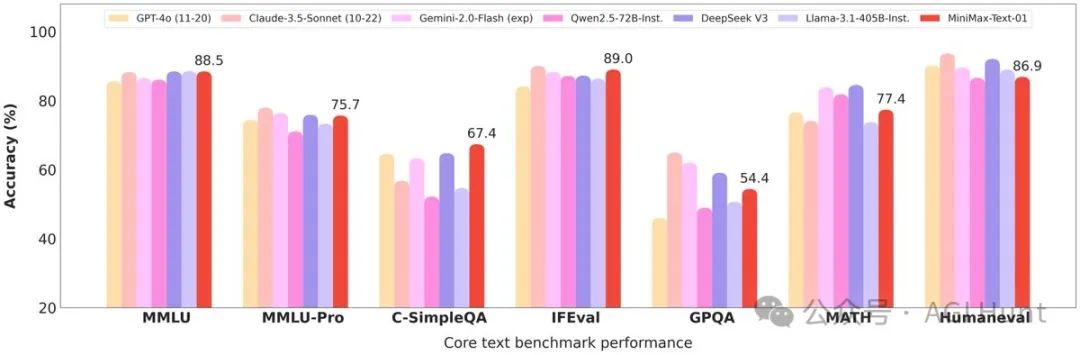
在核心基准测试中,MiniMax-Text-01展现出了令人惊艳的表现:
-
C-SimpleQA:以67.4的成绩登顶榜首
-
MMLU:88.5分,与榜首仅差0.1分
-
IFEval:89.1分,在所有开源模型中位居第二
-
LongBench v2:在长文本理解任务中全面超越GPT-4和Claude
swayaminsync(@swayaminsync)直接感叹:
「4M和商业授权」,这简直是王炸组合!
黑科技加持
为了实现这些惊人的性能,MiniMax团队祭出了三大「秘密武器」:
-
LASP+:线性注意力序列并行化增强版
-
Varlen Ring Attention:可变长度环形注意力机制
-
ETP:专家张量并行
Tyler(@TylerJThomas9)特别指出:
他们巧妙地解决了GPU间通信瓶颈的问题。
而Mark(@MarkOkedoyin)感慨道:
没想到开源模型的引领者居然会是来自中国的团队。
立刻可用!
最激动人心的是,这个「怪兽模型」已经可以直接使用了:
-
模型权重:已在Hugging Face上开放下载
-
在线体验:提供了完整的演示空间
-
商业许可:支持商业使用!
wh(@nrehiew_)也提醒道:
仔细看图表,它在7项测试中有2项超越DeepSeek V3,2项持平,其他略有差距。
无论如何,MiniMax-Text-01的发布无疑为开源大模型领域带来了一股新的活力。
这个集超长上下文、开源共享和商业友好于一体的模型,将为AI应用开发带来无限可能。
相关链接
[1] HuggingFace: https://huggingface.co/MiniMaxAI/MiniMax-Text-01
[2] 体验空间: https://huggingface.co/spaces/MiniMaxAI/MiniMax-Text-01
[3] Github: https://github.com/MiniMax-AI/MiniMax-01
(文:AGI Hunt)