作者|王艺
编辑|王博
“今年年初我们让GPT-3水平的模型上了端,9月份让GPT-3.5水平的模型上了端,未来会让GPT-4o及更高水平模型上端。”在上个月举办的2024甲子引力年终盛典上,面壁智能联合创始人、CEO李大海说。
一个月后的今天,面壁智能就把GPT-4o水平的模型MiniCPM-o 2.6带到了端侧。
而现在距离OpenAI GPT-4o的发布,也就过去了8个月。
作为面壁智能最新一代端侧模型,MiniCPM-o 2.6的参数量仅有8B,采用了全面对标GPT-4o的“全模态实时流式视频理解+高级语音对话”技术,不仅支持视频、语音、文本输入以及语音、文本输出,还具备人类级别的低延迟实时交互。
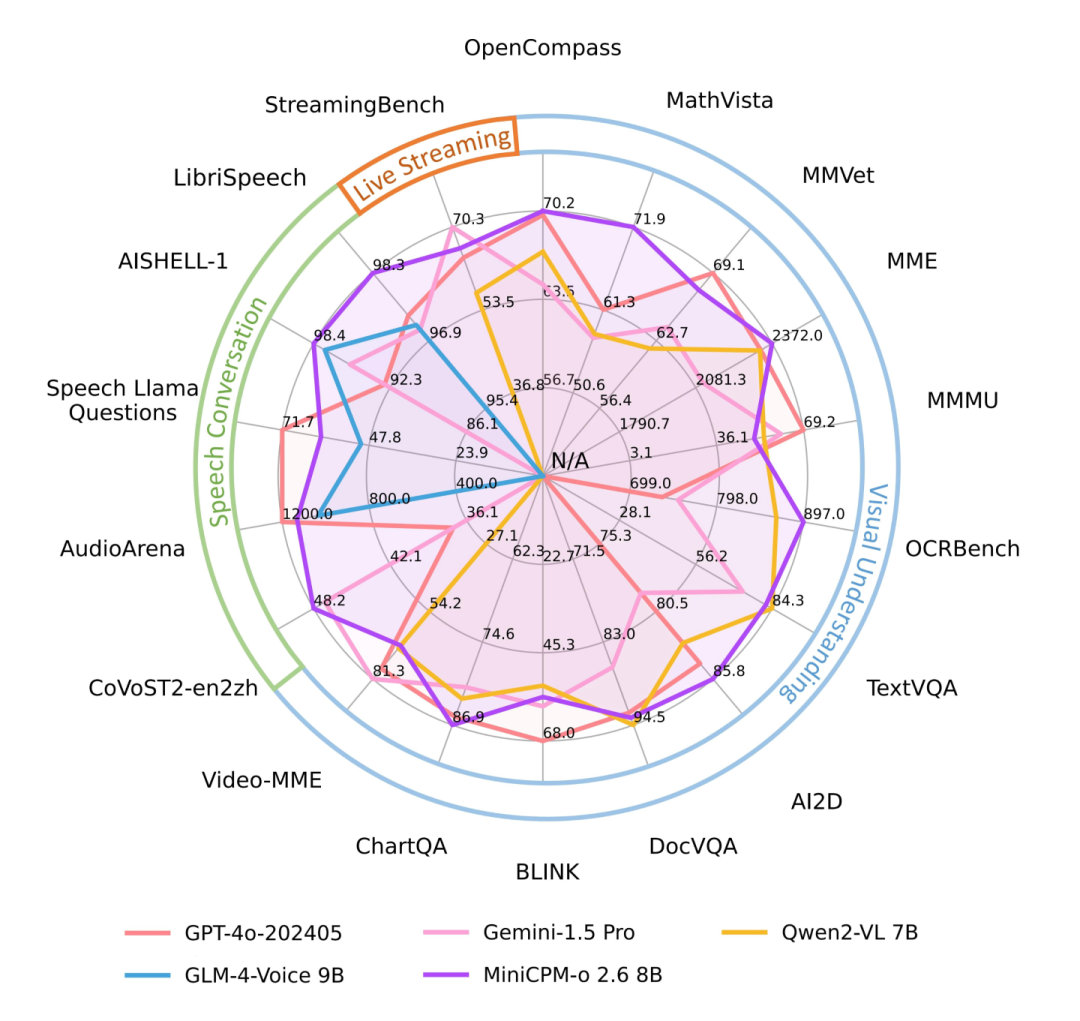
基于VLMEvalKit等工具包的评测结果显示,MiniCPM-o 2.6取得了实时流式全模态开源模型SOTA(当前最佳),性能比肩GPT-4o、Claude-3.5-Sonnet;在语音方面,取得了理解、生成开源双SOTA;而在此前就较为擅长的视觉领域,MiniCPM-o 2.6也有优异的表现。
“MiniCPM-o 2.6吹响了端侧全模态的号角,”在今天的媒体沟通会上李大海说,“我们希望用面壁的模型帮助设备厂商,让他们的用户得到更好的体验。”
1.端侧GPT-4o水平模型,成色如何?
既然声称是“端侧GPT-4o”,那就有必要好好比一比。
首先是参数量。OpenAI目前并未公布GPT-4和GPT-4o的真实参数量,此前有人推测其参数量远超GPT-3的175B参数,不过近期也有爆料文章援引一篇微软在医学领域的论文称:GPT-4参数量约为1760B、GPT-4o参数量约为200B、GPT-4o mini参数量约8B。
巧合的是,MiniCPM-o 2.6的参数量也是8B,不过MiniCPM-o 2.6对标的是参数量远高于它的GPT-4o。
接下来看看实际测试情况。
以GPT-4o主打的视频理解功能为例,GPT-4o发布后,不少模型也上了视频理解功能,比如Claude-3.5-Sonnet、Gemini 1.5 Pro等。
然而,「甲子光年」了解到,市面上主流的视频理解模型很多是对静态“照片”的理解,仅在用户提问后才开始对视频进行静态的图片抽帧,缺乏对前文情境的感知,无法捕捉用户提问之前的画面。
MiniCPM-o 2.6则可以实现对用户提问之前画面和声音的“持续感知”,通过持续对实时视频和音频流进行建模的方式,MiniCPM-o 2.6做到了让模型对视频的“观测理解”更接近人眼的自然交互。
比如在三仙归洞、记忆卡牌等游戏中,MiniCPM-o 2.6不仅能猜中游戏中小球藏到了哪个杯子,还能记住翻牌游戏中相似图案卡片的细节。
在音频的理解上,MiniCPM-o 2.6不仅能做到理解人们说话的声音,更是对翻书、倒水、敲门声等背景音也能精准识别,而这是GPT-4o这样的模型“听不到”的。
此外,在人机对话场景,MiniCPM-o 2.6能生成具备丰富情感和语气表达的真人质感音频,不仅延迟更低,还能够克隆别人的音色。比如输入一段文字,MiniCPM-o 2.6生成了惟妙惟肖的模仿特朗普和麦当劳叔叔说话的声音。
MiniCPM-o 2.6还能在被打断后及时作出反应、并用不同的情绪、语调回复。
最后看看榜单成绩。
在实时流式视频理解能力的代表榜单StreamingBench上,MiniCPM-o 2.6实现了比肩GPT-4o、Claude-3.5-Sonnet的分数。
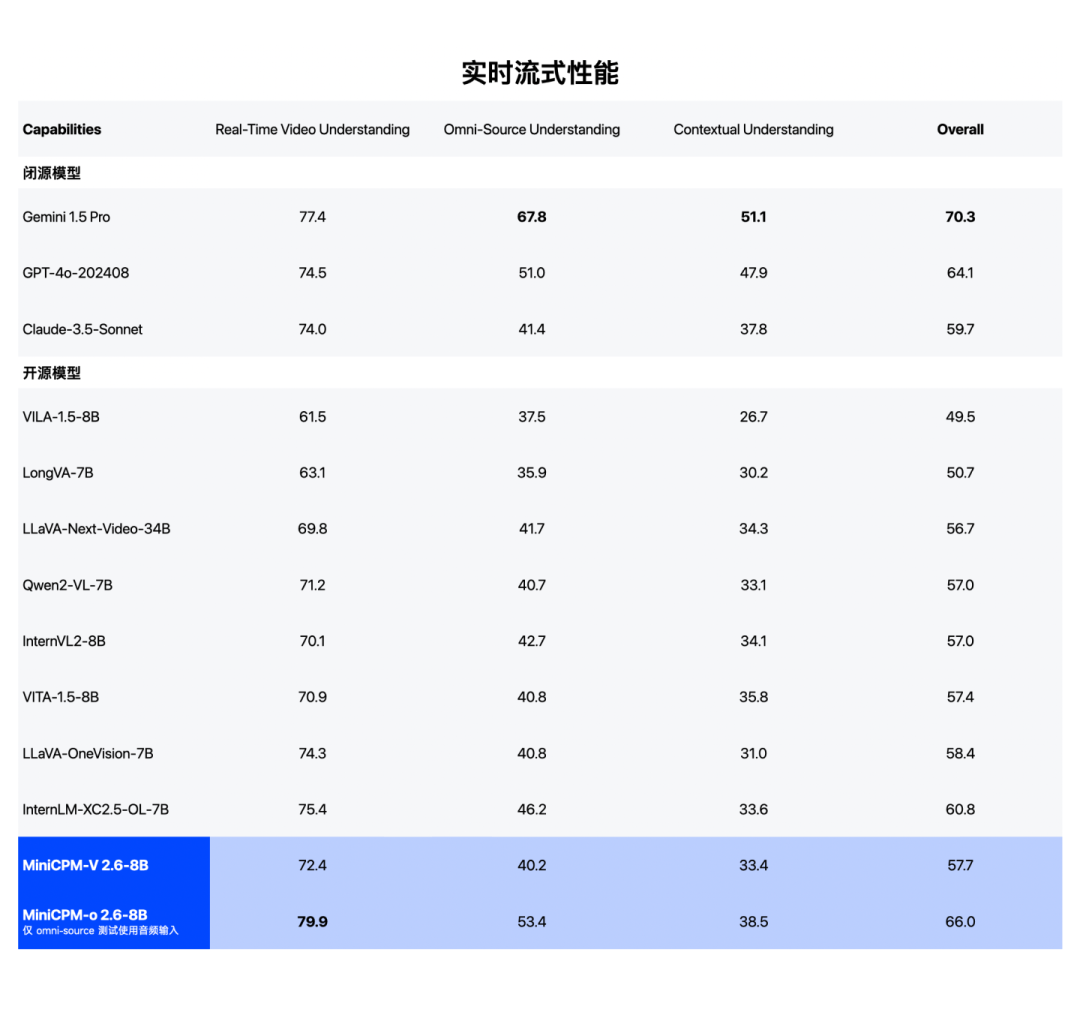
实时流式视频理解能力比肩GPT-4o、Claude 3.5 Sonnet。(注:GPT-4o API 无法同时输入语音和视频,目前定量评测输入文本和视频)
在语音理解方面,MiniCPM-o 2.6的得分超越了Qwen2-Audio-7B-Instruct,实现通用模型开源SOTA(包括ASR、语音描述等任务);在语音生成方面,MiniCPM-o 2.6超越GLM-4-Voice 9B,实现通用模型开源SOTA。
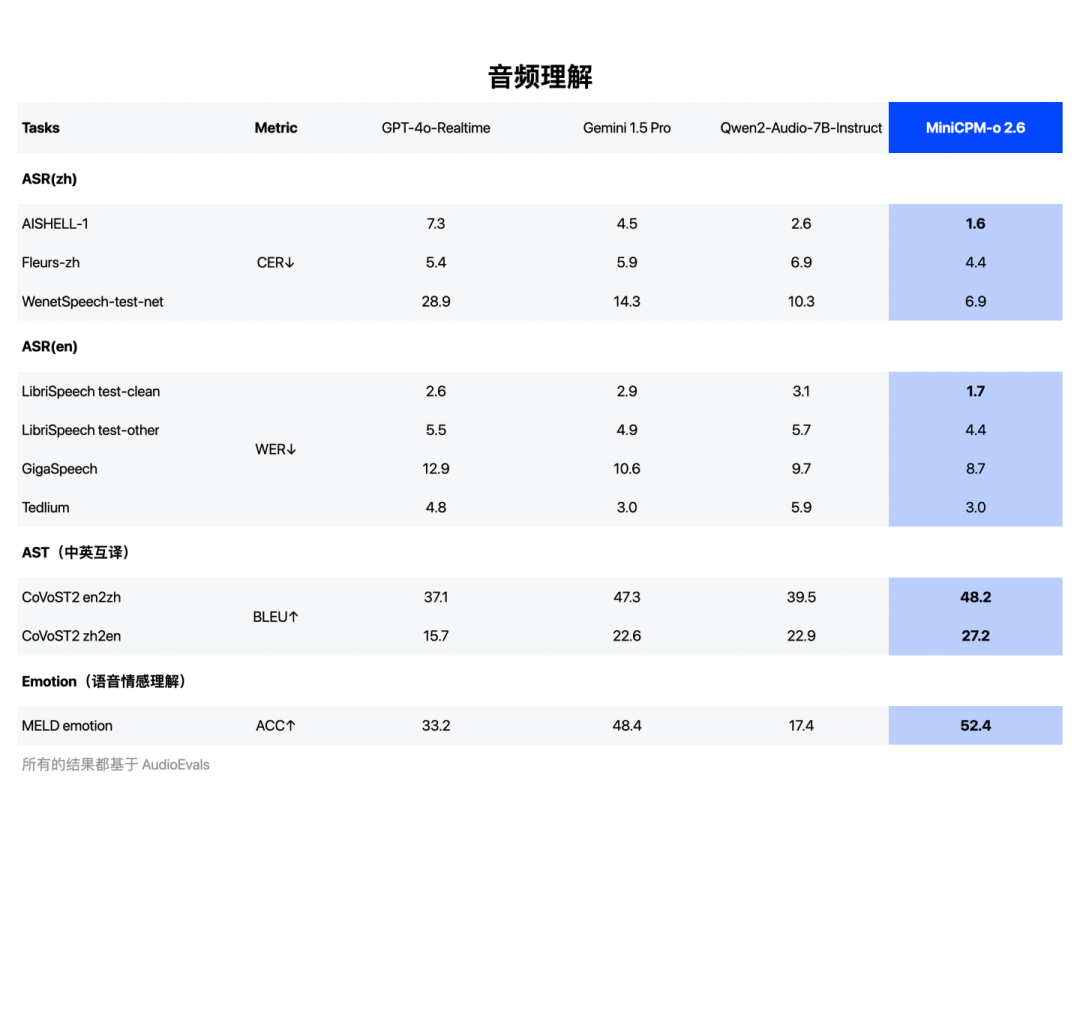
音频理解能力SOTA,超越Qwen2-Audio 7B-Instruct
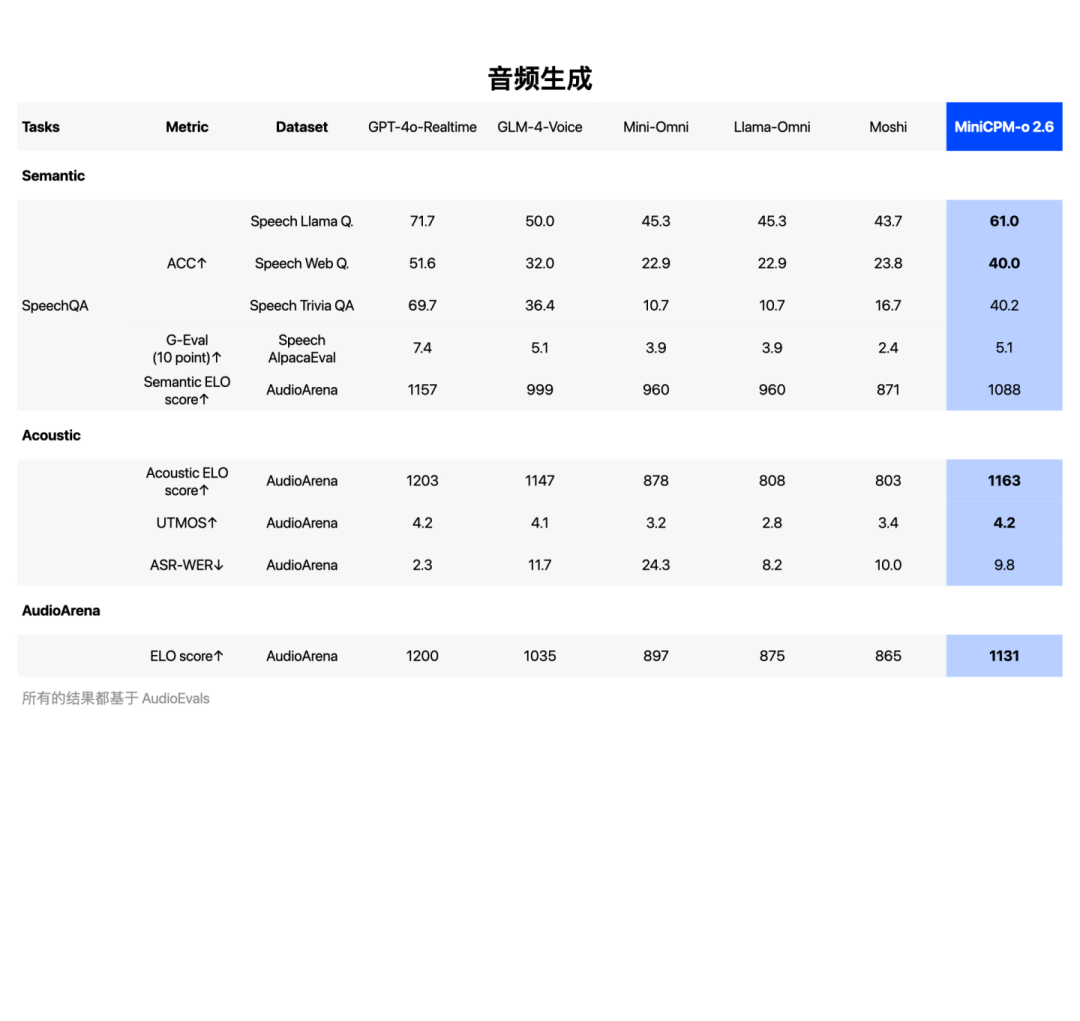
音频生成能力SOTA,超越GLM-4-Voice 9B
MiniCPM-o 2.6视觉理解能力也达到端侧全模态模型最佳水平。
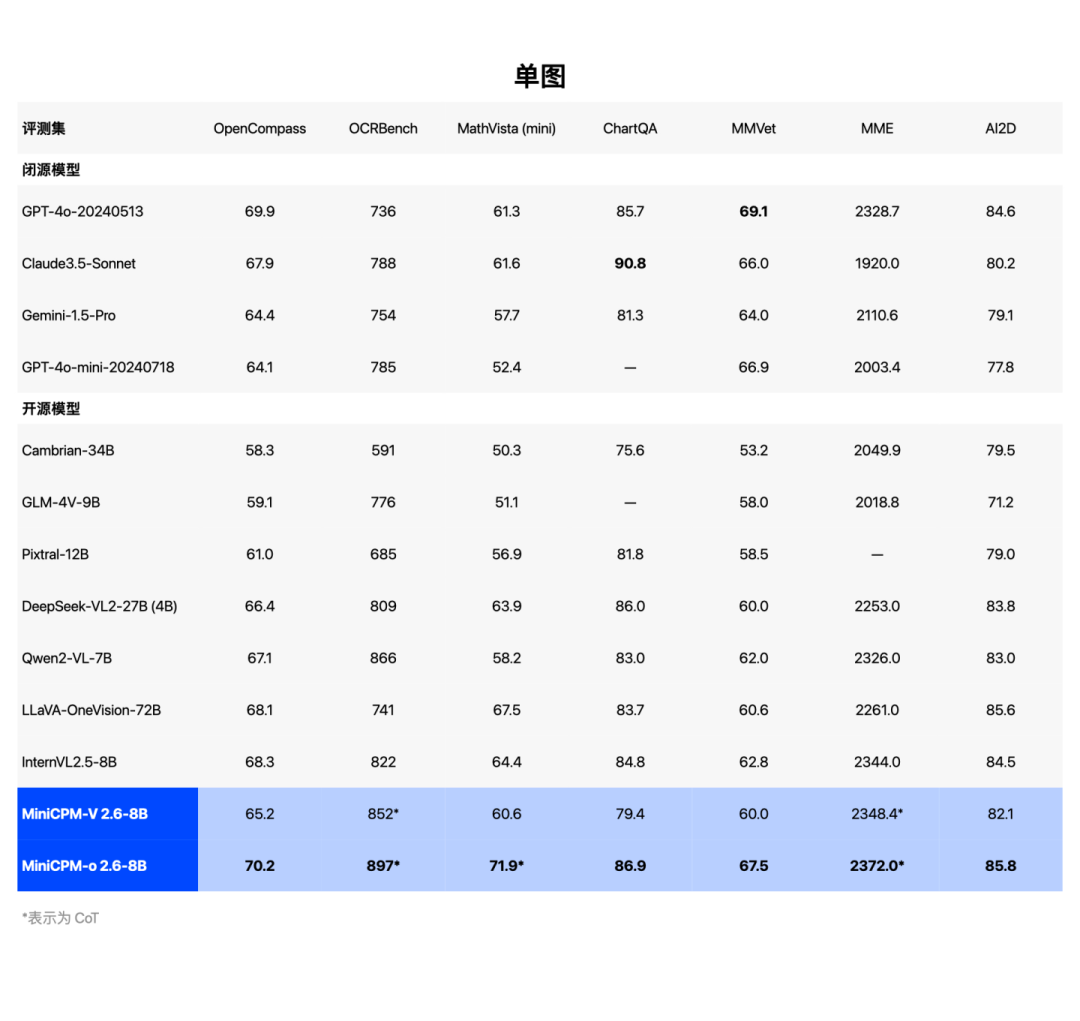
视觉理解能力SOTA,超越 GPT-4o、Claude-3.5-Sonnet
「甲子光年」发现,为了证明MiniCPM-o 2.6图片理解和推理能力,面壁智能特意在其Github上放了两个案例。
第一个是解数学题的场景。给MiniCPM-o 2.6一张两个函数曲线相交的图,让其求交点坐标,它给出了完整的函数公式、解题步骤和准确的结果。

第二个是调整自行车座椅的场景。MiniCPM-o 2.6不仅给出了“安全提示”“使用合适的工具”“松开螺栓”等步骤,更是在测试人员提出二次确认的时候准确指出了螺栓的位置,还在测试人员上传的工具箱图片中找出了合适的扳手。
多模态模型的训练并不是一桩易事,除了需要处理多种类型的数据,模型结构复杂、参数量大难压缩之外,模态之间的语义鸿沟和时间同步问题也是困扰很多训练团队的难题。
那么,面壁智能MiniCPM-o 2.6是如何将多模态模型的参数量压缩到8B的同时,还成功将各个模态对齐、并实现高效理解和生成的?
2.面壁智能的秘籍
MiniCPM-o 2.6基于SigLip-400M、Whisper-medium-300M、ChatTTS-200M和Qwen2.5-7B构建,共8B参数,通过端到端方式训练和推理。
传统的语音和视频模型多采用级联工作方式,如语音模型中,模型在处理声音时会先把声音转换为文本,然后对文本进行处理输出声音;视频模型中,也有团队先使用ViT提取视频帧特征,再通过级联网络(如RNN或另一个 Transformer)进行时序建模。
然而,级联的工作方式会造成信息的损耗,比如丢失掉声音本身富含的不同音色、声调和情绪信息,或者丢掉部分视频帧,这些都会让模型的音视频理解和生成效果大打折扣。
比如说“啊”,不同的声调表达的意思是完全不同的,就更别说一些“阴阳怪气”的表达,光看文字是无法准确理解的。
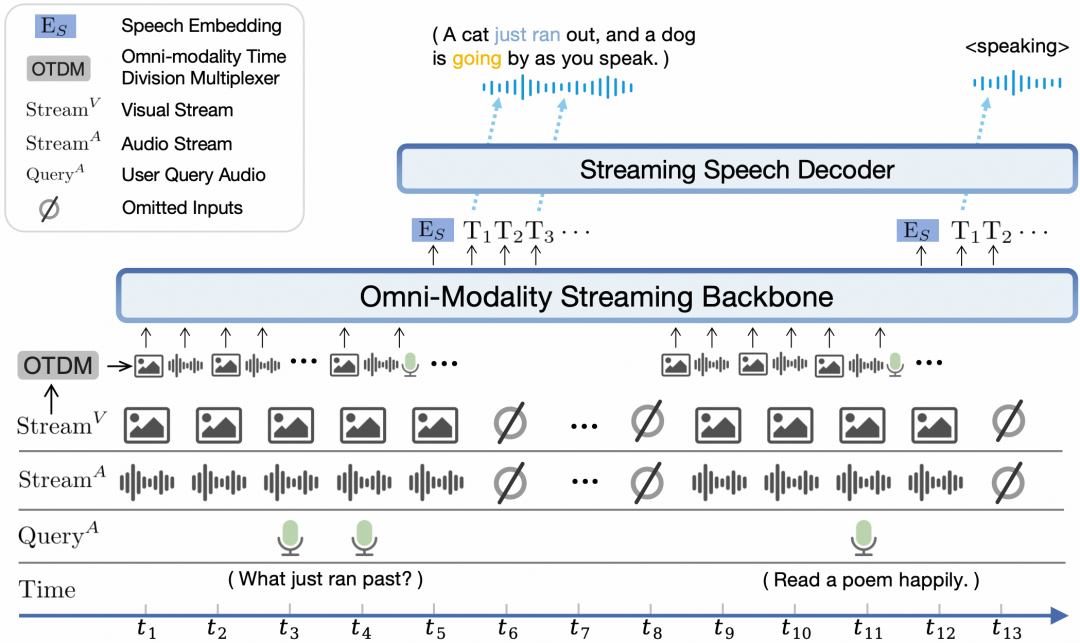
为了避免上述问题,面壁智能技术团队采用了端到端、全模态的训练架构,通过将不同模态的离线编/解码器改造为适用于流式输入/输出的在线模块,让语音和视频信息充分被模型理解和利用。
MiniCPM-o 2.6采用ViT等模型进行视觉和语音编码,用自回归语音解码模块实现语音生成。整体模型以端到端方式,通过连续稠密表示连接,实现端到端的联合学习,从而支撑较高的模型能力上限。
「甲子光年」制图
通过这种架构,视觉及语音输入中非自然语言可描述的模态信息,也可通过端到端方式传递到语音生成的内容中,从而实现了生成内容的较高自然度和可控性。
MiniCPM-o 2.6模型架构
“全模态流式机制”也是面壁智能打造MiniCPM-o 2.6的秘籍。
面壁智能针对大语言模型基座设计了时分复用的全模态流式信息处理机制,将平行的不同模态的信息流拆分重组为周期性时间片序列,实现了低延迟的模态并发。
具体而言,面壁智能首先将时间域切分成周期循环的时间切片,在每个时间切片中,分别对视觉和音频输入信号进行流失编码,并对主动输出语义时机进行判断,并通过基座模型对用户语音结束时机进行高级语义判断,从而避免了用户输入语音后的长时间回复等待。
尤其是在端侧,用户对模型响应速度会更加敏感,多一秒的等待都可能会失去用户。
「甲子光年」查阅了Github上MiniCPM-o 2.6的介绍资料,还发现了这两个“秘籍”之外的“巧思”。
面壁技术团队设计了新的多模态系统提示,包含传统的文本系统提示词、和用于指定模型声音的语音系统提示词,模型可在推理时灵活地通过文字或语音例控制声音风格,并支持端到端的声音克隆和音色创建等高级能力。
这也是MiniCPM-o 2.6能够模仿特朗普演讲、在打碎花盆、修复花盆的情境下能够用慌张、激动和惊恐的语气表达的原因。
值得一提的是,针对视频理解任务中“冗余信息过多”的难题,MiniCPM-o 2.6沿用了MiniCPM-V系列模型中的超高多模态像素密度技术,可以通过对视频帧的极致压缩,让模型以更低的成本看更多的帧,从而最大程度获取视频的信息。
通常的视频理解模型需要2000~2500个Token才能编码一张180万像素的图片,而MiniCPM-o 2.6只需使用640个Token就可以编码一张同规格的图片。
“这还只是一张图片,如果是视频的话,在这么大的Token开销下,模型很快就会爆显存。”清华大学博士后、MiniCPM-o技术负责人姚远介绍,这也是为什么很多模型只能接受单帧、或者极少数帧的原因。
MiniCPM-o 2.6能够处理比较长的视频,除了基于模型原生记忆、存在上下文的context之外,还会通过RAG的方式管理输入的Token。“每看完一部分就集成起来,这也是符合技术发展规律的,因为模型不可能储存一天的视频信息,只要能够高效地找到准确的信息、满足用户的需求就可以。”姚远说。
3.应用场景在哪里?
在刚刚结束的CES 2025上,AI硬件获得了极高的关注度,而与AI硬件密切相关的端侧模型,也进入了更多人的视野。
把更高效低成本的大模型,放到离用户最近的地方,一直是面壁智能追求的目标。
就在上周,李大海前往CES 2025现场,展示了MiniCPM端侧模型在实际设备上的运行效果,以及在AI Phone、AI PC、智能座舱、智能家居与具身机器人等领域的落地案例。
面壁智能也是为数不多的参加今年CES的国内大模型企业。
在CES现场,李大海很直接地对「甲子光年」表示:“端侧模型在2025年必然会迎来一个非常大的爆发。”
他还分享道,在CES上看到了大模型赋能的AI定义汽车、具身智能、AIPC、AI眼镜、AI玩具,大模型跟主流和新兴硬件结合,正在飞入千家万户、千行百业,“我仿佛看到了10年之后,大模型‘无处不在’的未来。”
而在上个月,面壁智能还提出了大模型的密度定律(Densing Law)——模型能力随时间呈指数级增长,2023年以来能力密度约每3.3个月翻一倍(详见《对话面壁智能刘知远:Densing Law是大模型能力的另一个度量衡|甲子光年》)。
面壁智能通过追求更高原创性的、更加前沿的探索,在Densing Law指引下,让模型能力密度跨越规模应用的一个又一个阶梯,打开一个又一个巨大市场。
一方是广阔的AI硬件市场,一方是越来越高效的端侧模型,面壁智能端侧模型的落地场景呼之欲出。
在今年举行的媒体沟通会上,李大海很坚定地认为“端侧模型+AI硬件”是未来发展的方向,未来的每一个硬件都应该是智能化的。
具体到合作方式上,李大海介绍:“第一,我们会跟各种能力强的AI芯片公司合作,让面壁的模型跑在这些芯片上;第二,基于跟芯片结合的基础能力,去赋能更多的设备,MiniCPM-o 2.6将重点关注具身化属性较强的设备。”
“具身化属性”与具身智能相关,智能汽车和机器人就是具身化属性很强的设备,其关键是在没有人类指导的情况下,产品能自主理解他们所处的物理和环境限制,自主做出决策并执行行动。
2024年下半年,面壁智能MiniCPM端侧模型加速落地,先后与华为云、加速进化机器人、大象机器人、梧桐科技、长城汽车、联发科技、百度智能云、英特尔建立合作关系,业务版图延伸至智能座舱,机器人、端云协同等多个领域。
可以看出,面壁智能并没有局限在手机端,而是瞄准了更多的智能终端。「甲子光年」分析,这背后有两点原因:一是包括苹果在内的各家手机厂商都在自研端侧模型;二是AI手机上跑的模型目前还比较“初级”,手机还无法实现真正具身智能产品那样的“灵活性”和“自主性”。
“智能体绝大部分被动的信息都是通过视觉和听觉完成的,面壁的模型是一个全模态的模型,不仅有文字,还能通过视觉和听觉感知世界,让设备像人一样感知周围的环境,因此我们要落地的具身化设备和AI手机是两个完全不同的物种。”李大海在媒体沟通会上说。
“要有灵魂,”在上周的CES上,李大海对「甲子光年」说,“最重要的是,它能够很好地去感知环境,跟环境互动,做出反应,同时还有记忆,这些结合在一起,它就是有灵魂的。”
(封面图来源:「甲子光年」CES 2025现场拍摄)
(文:甲子光年)