
人脸修复 (FR) 是图像和视频处理中的一个重要领域,专注于从质量下降的输入中重建高质量的肖像。尽管图像 FR 取得了进展,但视频 FR 仍然相对未被充分探索,这主要是由于与时间一致性、运动伪影和高质量视频数据有限相关的挑战。此外,传统的人脸修复通常优先考虑提高分辨率,可能不会过多考虑面部着色和修复等相关任务。
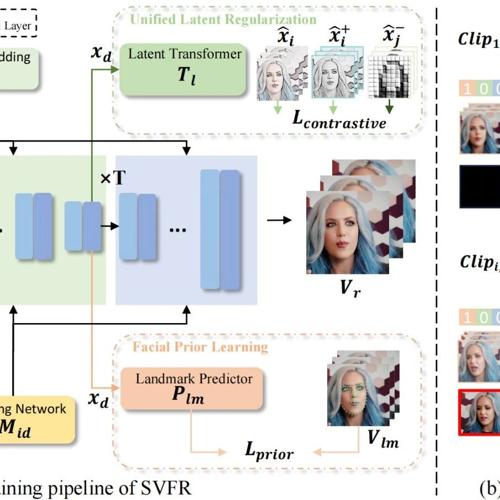
在本文中,我们提出了一种用于广义视频人脸恢复 (GVFR) 任务的新方法,该方法集成了视频 BFR、修复和着色任务,我们通过经验证明这些任务可以相互受益。我们提出了一个统一的框架,称为稳定视频人脸恢复 (SVFR),它利用稳定视频扩散 (SVD) 的生成和运动先验,并通过统一的人脸恢复框架整合特定于任务的信息。引入了可学习的任务嵌入以增强任务识别。同时,采用了一种新颖的统一潜在正则化 (ULR) 来鼓励不同子任务之间的共享特征表示学习。为了进一步提高恢复质量和时间稳定性,我们引入了面部先验学习和自参考细化作为用于训练和推理的辅助策略。
所提出的框架有效地结合了这些任务的互补优势,增强了时间连贯性并实现了卓越的恢复质量。这项工作推动了视频 FR 的最新进展,并为广义视频人脸恢复建立了新的范式


参考文献:
[1] http://wangzhiyaoo.github.io/SVFR/
(文:NLP工程化)
视频人脸修复?这技术怕是要比AI生成图片难无数倍,看看论文标题都得先理解一遍吧
人脸修复技术又一次证明了AI的强大,视频修复更上一层楼!