跳至内容
【新智元导读】马斯克建超算速度,被中国这家公司用120天复刻了。119个集装箱,像搭积木一样拼出一座算力工厂。这不是科幻电影,而是浪潮信息交付的惊艳答卷。一个全新的AI时代,正在这里拉开序幕。
上面这座算力工厂,采用了浪潮信息专为AI时代提出的预制化AIDC解决方案。
他们以「搭积木」方式,向世界诠释了惊人的基建速度。
它不仅将长达18个月的建设周期,大幅缩短至4个月,甚至还实现了高效节能、弹性扩容、按需定制、便捷运维等技术创新。
更为重要的是,这座算力工厂能够完全满足scaling大模型的算力需求。
不论是训练,还是应用部署,预制化AIDC解决方案全面支持了AI大模型创新研发和应用。
算力,就是这个AI时代的「命门」。众所周知,AI大模型对算力的需求,远超乎所有人的想象。
不论是OpenAI、微软,还是谷歌等科技巨头们坚信的是,scaling law仍在继续。
2024年12月,堪称过去一年AI含金量最高的一个月,从中便可瞥见一二。
OpenAI十二天Devday连更,为所有人送上了满血版o1、o1 Pro、Sora、高级语音功能,以及初次亮相的o3系模型。
与之激烈对打的谷歌,更是战绩连连,凭借Gemni 2.0 Flash、Veo 2直接杀出重围。
迈入2025年,Grok 3、Llama 4、完整版Gemni 2.0等众多模型,也即将迎来新一轮大战。
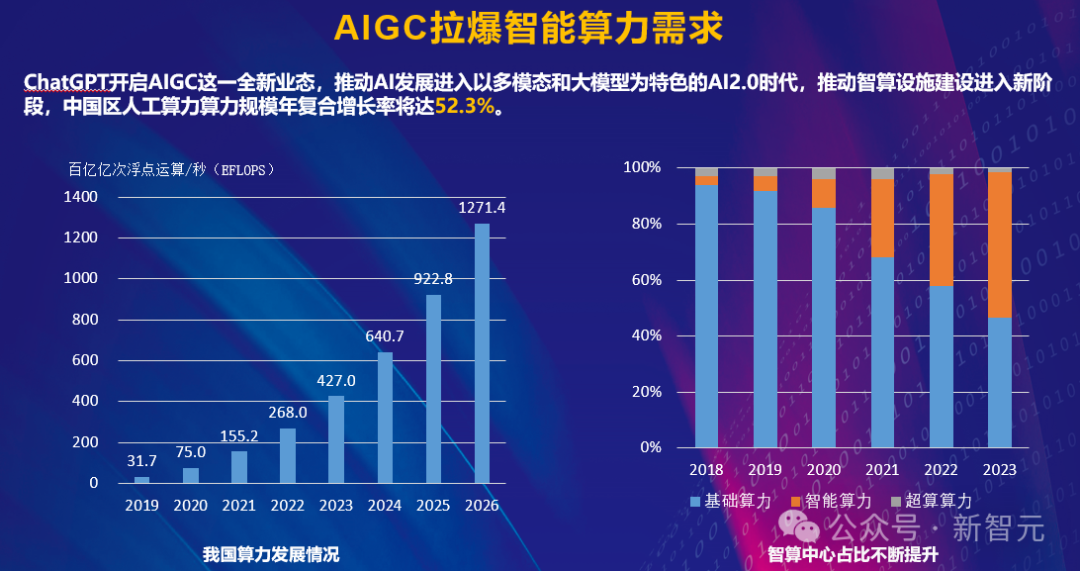
可以预见的是,每一代新模型都在疯狂「吃」算力,训练参数呈指数级增长。这种疯狂扩张的态势,让人不禁要问:我们的数据中心基建,还能支撑多久?
实际上,当前的数据中心正面临着最核心的「三重困境」。
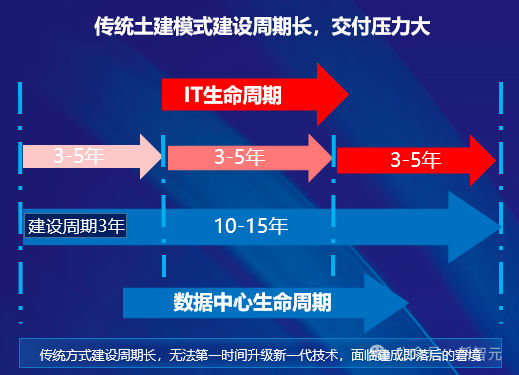
一般来说,传统数据中心的建设是一个复杂的工程,需要经过设计、土建、机电安装、调试等多个阶段。其中,光规划和建设就要3-5年时间,占到了整个生命周期的约1/3。
老黄同样说过,「建造一个超算通常需要3年的规划时间,外加1年设备交付和调试时间」。
而我们所看到的,马斯克10万块GPU建设速度,甚至即将要建的100万块GPU搭建的超算,也只是个例。
3年,这一时间跨度,对于快速发展的AI时代显得尤为漫长。
比如,3年前规划的数据中心普遍采用5-10kW/标准柜,而如今单台AI服务器的功耗就已突破10kW。
显而易见,AI迭代与基建建设的速度,严重不匹配,导致数据中心还未建成就已落后于时代。
同时,这种「建设慢,需求快」的矛盾,不仅影响了产业发展速度,还直接影响了投资方资金回报周期,形成了恶性循环。
其次,随着算力需求的暴增,数据中心的能耗问题也愈发突出。
AI大模型训练的耗电量,堪比一个小城市的用电量。而这样比比皆是的报道,也早已家喻户晓。
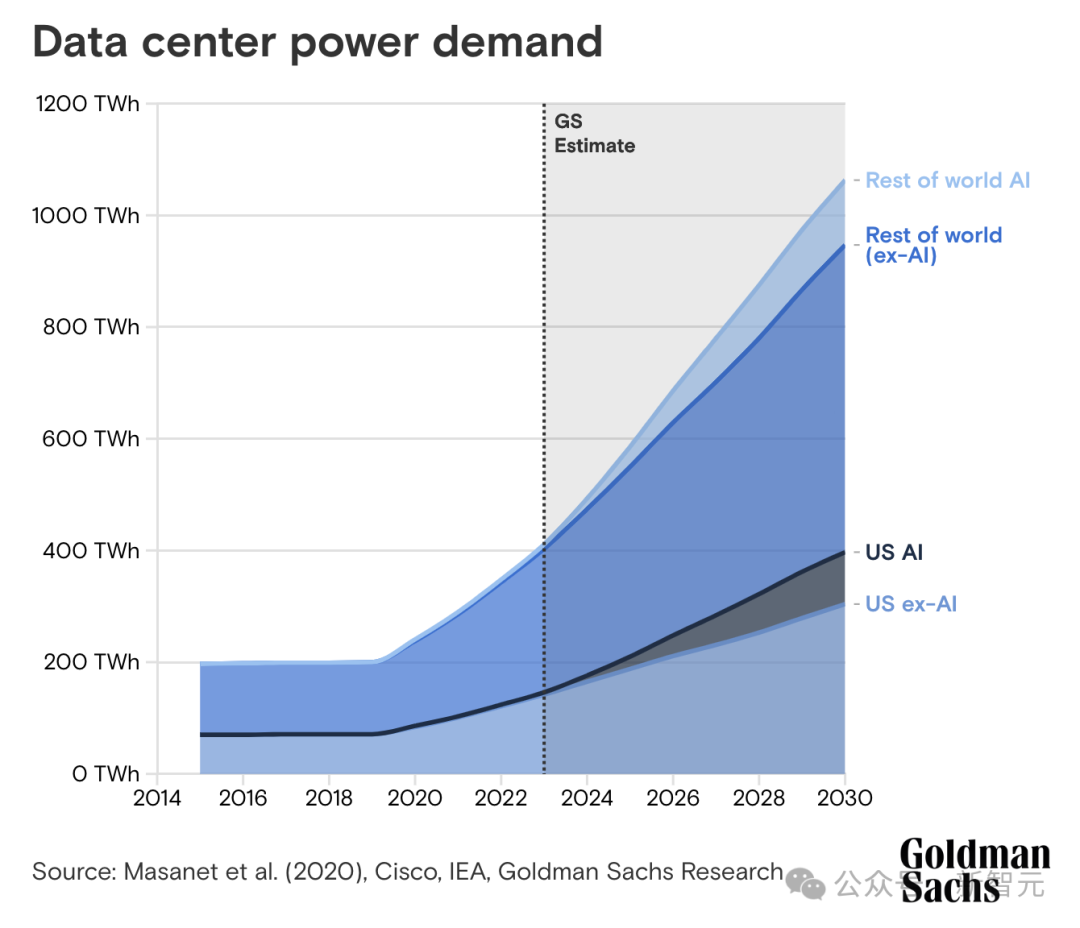
平均而言,ChatGPT查询所需的电力是谷歌搜索的近10倍。高盛研究估计,到2030年,数据中心的电力需求将增长160%。
从2023年-2030年,AI数据中心功耗的增长将达到每年200Twh
从芯片设计方面来看,CPU热设计功率(TDP)在过去十年几乎翻倍,GPU热设计功耗从2008年不足200W飙升至现如今1000W。
再加上,集群越来越大,高密度服务器部署来带的散热压力,与日俱增。
与此同时,信通院发布的《中国绿色算力发展研究报告(2024年)》显示,我国数据中心的平均电能利用效率(PUE)在2023年时为1.48,而新的国家政策规定,新建数据中心的PUE不得超过1.25。
如何保持高性能计算的同时,达到节能标准,已经成为一大难题。
而当前,智算中心需要探索的是,与绿色电力深度融合,实现能源高效利用,让算力向智力有效转化。
不仅如此,AI快速迭代对数据中心的灵活性,提出了更高的要求。
然而,传统数据中心的固定架构,限制了升级空间,无法及时采用新一代技术,难以快速响应业务需求的变化。
另一方面,数据中心还将面临建成即落后、供不应求的窘境,投资回报率难以保障。
针对这些挑战,这些年,一些企业打造的预制模块化数据中心应用而生,并将成为主流模式。
根据规模不同,可分为单元级(Unit)、包间级(Pod)、建筑级(Stack Cube)、园区级(Base)等细粒度。
在AI时代下,我们就需要专为AI而生的预制化AIDC。
算力工厂是一种创新的数据中心全生命周期服务模式,核心是通过规(划)、建(设)、运(营)一体化的「交钥匙」工程。
其总体架构自下而上,由算力底座、算力支撑、算力运营三部分组成。
算力底座
元脑「算力工厂」这座智算中心采用创新的预制化AIDC解决方案,仅需119个预制化集装箱单层拼接,4个箱体即可实现千卡规模AI算力。
正如之前所述,它书写了惊人搭建速度的传奇,直接将同等规模数据中心的建设周期,从18个月缩减至4个月。
因为采用了预制化集装箱建设方式,同等规模数据中心的建设周期从18个月缩减至4个月,工期缩短了近80%。
因为创新地应用了液冷、光伏、储能、余热回收等节能技术,提高了散热及能源利用效率,PUE可降至1.1以下,全年节省电费近2亿元,运营成本大幅降低。
预制模块化叠箱体系建设模式可根据业务规模,分期高效地进行水平及竖向扩容,有效节省前期投入成本。
同时,八种模块化的功能箱体可根据不同场景、规模灵活组合,并按照功率区段分区部署,实现风冷/液冷、AI/通用/高密度等多种形态灵活兼容,匹配智算算力、通用算力、边缘算力等多种应用场景。
元脑算力工厂包含了数据处理、AI大模型、业务应用、研发测试等多个集群,为全球服务器压力测试、大模型开发应用等多种业务应用,提供了绿色高效的算力支撑。
算力运营
如前所述,在大模型时代,算力需求呈爆发式增长,但高效运营AI算力却面临着诸多的挑战。
该如何调度资源?如何控制成本?如何保障算力平台稳定性和可用性?如何让AI算力性能持续优化?
在大规模AI训练场景下,算力资源调度堪称一大难题。
一方面,不同AI任务对于算力需求各不相同;另一方面,如何在多用户、多任务场景在实现资源最优分配,避免算力的浪费,都是亟待解决的问题。
不仅如此,随着算力规模的扩大,运营成本也会随之攀升。诸如电力消耗、运维人员等各方面成本,都是企业面临的挑战。
另外,对于企业级AI应用来说,对算力平台稳定性提出了高标准、高要求。
然而,集群规模扩大管理只会愈加复杂,硬件出现故障的风险就会增加,随之带来的是系统性能波动频繁,数据安全隐患增高。
还有需要考虑到的一点是,AI算力性能必须持续优化。这当中也涉及到了多个层面,比如硬件协同优化、软件架构改进、算法效率提升等等。
为了应对这些挑战,元脑算力工厂为企业提供了全方位的运营方案。
AI基础设施管理平台面向金融、通信、互联网等多行业的数据中心,可实现前所未有的一体化管理。
平台突破性解决了IT基础设施管理与动力环境管理割裂的痛点,带来了全新的管理体验。
首先,它实现了智算中心全生命周期的统一纳管,运维效率提升100%。
平台还创新实现了高密单排微模块2D/3D、核心制冷部件远程调控等5大功能,安全性能飙升30%,为超大规模数据中心稳定高效运行提供重要保障。
作为深度学习开发平台,AIStation能够为企业客户提供强大的开发支持。
比如,统一管理和精细调度AI计算资源,全面整合计算资源、训练数据和开发工具。
不仅如此,AIStation还提供了完整的AI软件栈和敏捷标准化的开发流程,降低资源投入同时,大大提升开发效率。
基于系列平台的创新与整合,对于企业来说,算力的高效稳定运营也不再是难题。
既然有了这样一个堪称「黑科技」含量最高的解决方案,对于大模型时代下的训练和部署,意味着什么?
当前,AI大模型正在经历着前所未有的进化:从单一语言模型走向多模态;突破长文本限制;引入MoE架构;强化学习能力不断提升。
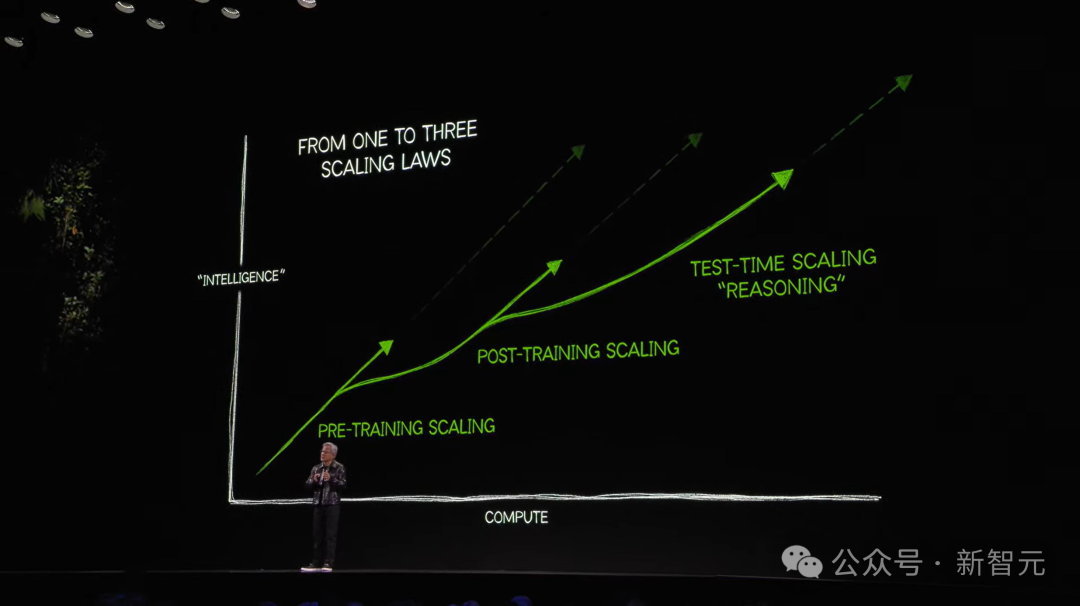
不仅如此,大模型进化Scaling Law仍在继续,老黄还在CES大会上首次提出了AI时代三个Scaling Law。
这暗示着,大模型的突破未来有着更加广阔的空间,唯一的限制,就是如何构建出强大的算力基础设施。
如今,AI大模型的参数规模已经从千亿级别攀升到了万亿级别。AI大模型厂商纷纷投建大规模算力资源,压缩大模型训练周期。
显而易见的是,随着算力规模的不断扩展,单颗芯片的性能瓶颈愈发明显,整个AI系统的通信效率成为焦点之一。
大型AI模型训练过程中,网络通信通常占据整体训练时间的20%到40%,这造成了大量算力资源浪费,优化网络通信效率,成为AI大模型发展的关键议题。
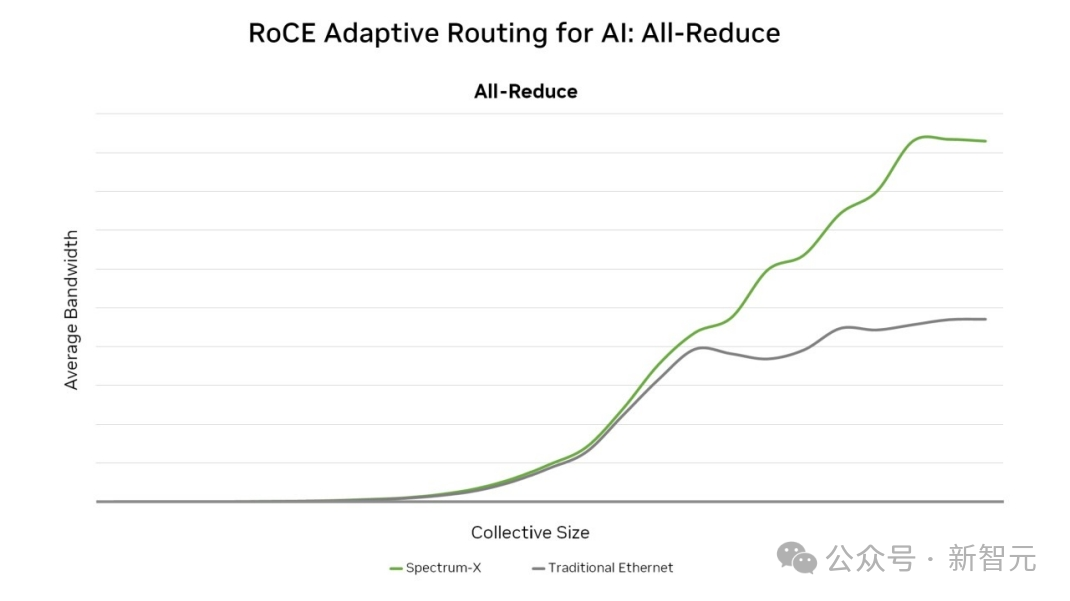
然而,目前的传统RoCE网络面临着网络性能不足、难以满足多样化AI系统网络需求、部署周期长、可靠性低、管理难度大等问题。
对此,元脑算力工厂采用了专门面向生成式AI打造的超级AI以太网交换机——X400,大幅降低网络通信占比,革命性地提升了大规模GPU训练性能;同时,采用浪潮信息 ICE智能云引擎,实现智能化的网络管控。
这,就成为了新型的AI训练网络解决方案,打造业界领先的AI Fabric。
超级AI以太网交换机X400,采用AR自适应路由、RTT CC拥塞控制、亚毫秒级故障自愈等技术,拥有高性能(高吞吐量、高带宽、低延迟)、高可靠性、快速部署、灵活拓展等核心优势。同时,它还具备多租户隔离、多业务并发支持的能力,以应对AI模型训练的复杂需求。
性能方面,X400的吞吐量达到了业界最高的51.2T,较上一代产品提升了4倍。在4U空间可提供128个400Gb/s的高速网络端口,相比传统RoCE网络性能提升了1.6倍。
值得一提的是,其对AI网络的带宽利用率可达95%以上,同时还可将通信时延降低30%。
综上,X400的应用将大幅提升大模型的训练效率,缩短训练时长,降低训练成本。
此外,在 AIGC 时代,网络管理已不再是传统的设备配置与监控,而是面向未来的智能化、自动化以及可视化的平台。
浪潮信息ICE智能云引擎正是这一趋势下的先行者,基于数字孪生技术,打造网络虚拟仿真和优化验证平台,并利用人工智能技术实现自动化管理和智能化监控,提升管理效率与故障响应速度,让企业在复杂环境中实现高效、可靠的网络运维,助力企业充分释放AIGC潜能。
系统性创新,三层无缝衔接
算力基础设施有了之后,如何解决算力与应用之间断层问题?
在此之前,浪潮信息早已给出了完美的解决方案——企业大模型开发平台「元脑企智」EPAI。
它犹如一座「桥梁」,通过提供软件栈及综合服务,赋能算力挖潜、模型优化和应用开发。
这次,元脑算力工厂直接搭载了EPAI,连接了多元算力、多元模型、应用层,直接加速LLM应用落地。
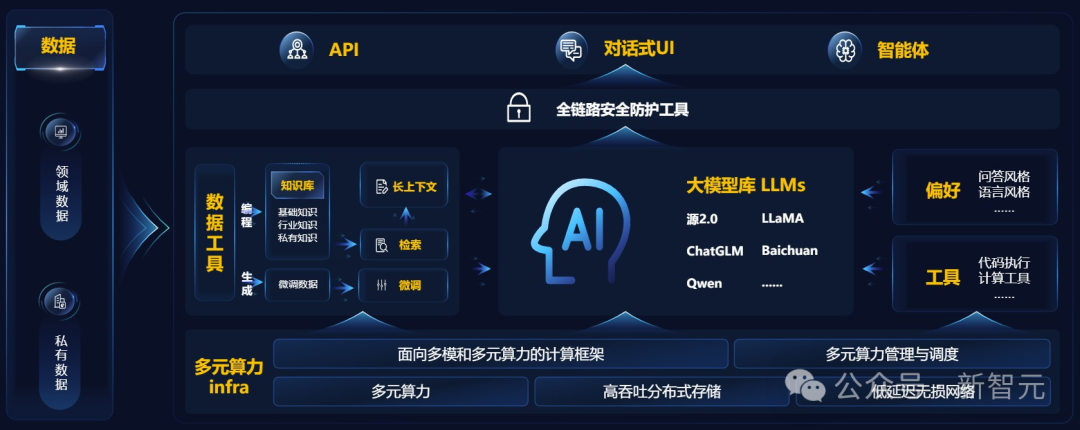
EPAI可实现百万token、千亿参数、领域大模型的高效微调,可以更好地适应具体行业场景下的任务需求,快速打造领域LLM。
与此同时,它还提供面向多元多模的计算框架,让LLM应用在跨算力平台上无感迁移。
这个过程,就降低了多模、多元的适配与试错成本,为企业用户根据实际场景需求,选择开发部署适合自己的大模型,提供了极大便利。
通过EPAI,企业可以高效地开发部署生成式AI应用,打造智能生产力。
在AI时代浪潮下,算力基建正成为决定创新速度、深度的关键要素。
基于预制化AIDC解决方案的算力工厂,不仅仅是一次技术创新,更是对这整个产业发展模式的革新。
算力工厂重新定义了算力释放的价值与效率,实现了基建与算力的强绑定,是以算力为中心来确定建设模式和内部的算力模组,所有设计都是算力的一部分,实现了投入即产出。
这一次,浪潮信息向世界真正展现了,中国速度与中国智慧的完美融合。
(文:新智元)













这简直太牛了!预制化AIDC方案完美诠释了算力工厂的力量,119个集装箱 mere的效率碾压传统模式。PUE降到1.1、液冷系统无缝对接、全场景扩展,这是硬核操作,王炸!