

-
全面回顾了RAG的发展历程,从最初的Naïve RAG到Advanced RAG,再到Modular RAG和Graph RAG,每种范式都有优劣。Agentic RAG作为最新范式,通过引入自主Agent实现了动态决策和工作流程优化。 -
详细探讨了Agentic RAG的基础原则、架构分类、关键应用,实施策略等全栈技术
RAG的发展历程
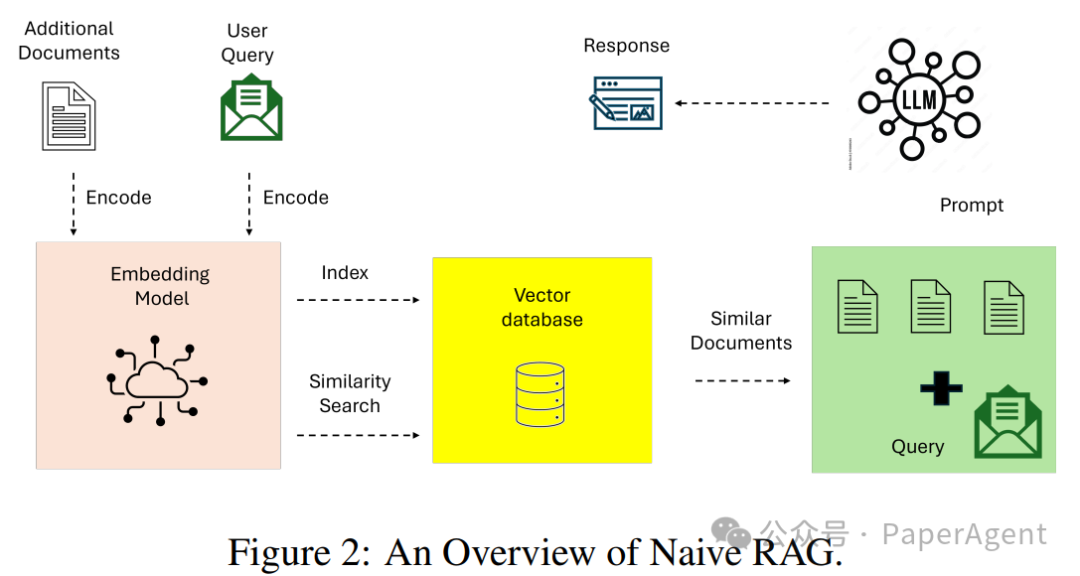
Naïve RAG
-
缺乏上下文感知:由于依赖词汇匹配而非语义理解,检索到的文档常常无法捕捉查询的语义细微差别。 -
输出碎片化:缺乏先进的预处理或上下文整合,常常导致不连贯或过于泛化的回答。 -
可扩展性问题:关键词检索技术在处理大型数据集时常常失败,无法识别最相关信息。
Advanced RAG
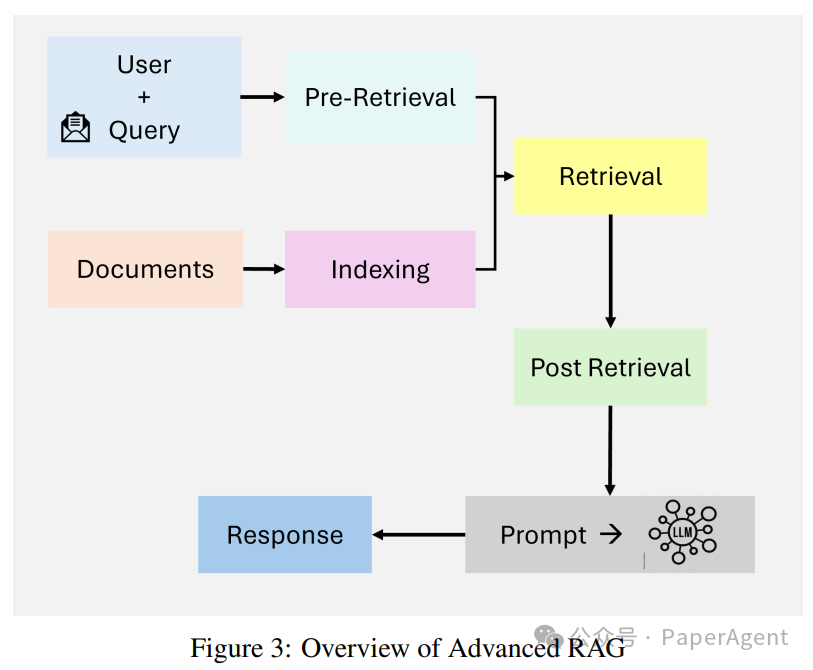
-
密集向量搜索:查询和文档在高维向量空间中表示,实现了用户查询和检索文档之间的更好语义对齐。 -
上下文重排:神经模型重新排序检索到的文档,优先考虑最上下文相关的信。 -
迭代检索:Advanced RAG引入了多跳检索机制,能够对复杂查询进行跨多个文档的推理。
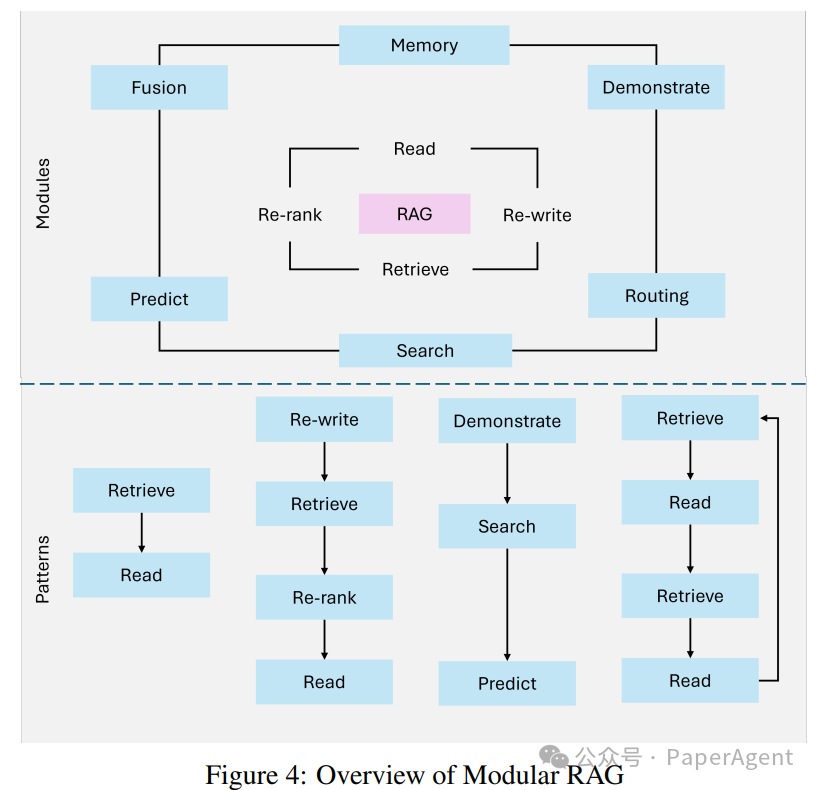
Modular RAG
-
混合检索策略:结合稀疏检索方法(例如稀疏编码器-BM25)与密集检索技术(例如DPR – Dense Passage Retrieval),以最大化不同查询类型的准确性。 -
工具集成:整合外部API、数据库或计算工具,处理专业任务,如实时数据分析或特定领域的计算。 -
可组合的流程:Modular RAG允许检索器、生成器和其他组件独立地替换、增强或重新配置,提供了对特定用例的高度适应性。
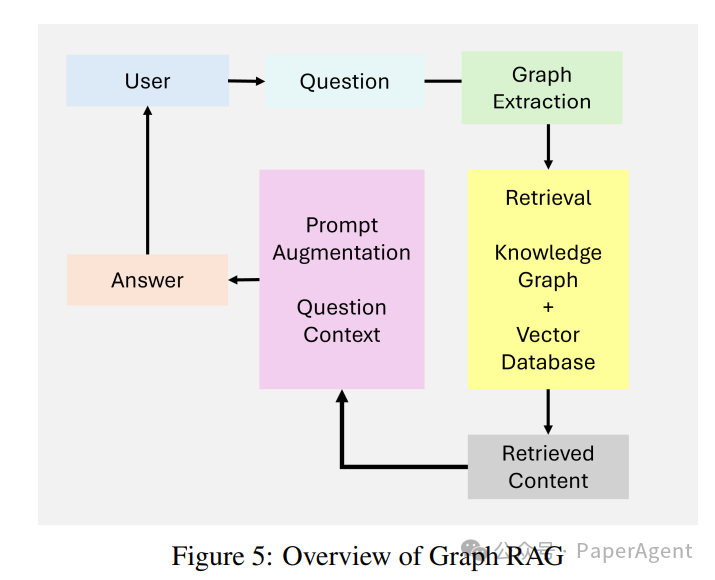
Graph RAG
-
节点连接性:捕获并推理实体之间的关系。 -
层次知识管理:通过基于图的层次结构处理结构化和非结构化数据。 -
上下文丰富:通过利用基于图的路径添加关系理解。
-
可扩展性有限:依赖图结构可能会限制可扩展性,特别是在数据源广泛时。 -
数据依赖:高质量的图数据对于有意义的输出至关重要,限制了其在非结构化或注释不佳的数据集中的适用性。 -
集成复杂性:将图数据与非结构化检索系统集成增加了设计和实现的复杂性。
Agentic RAG
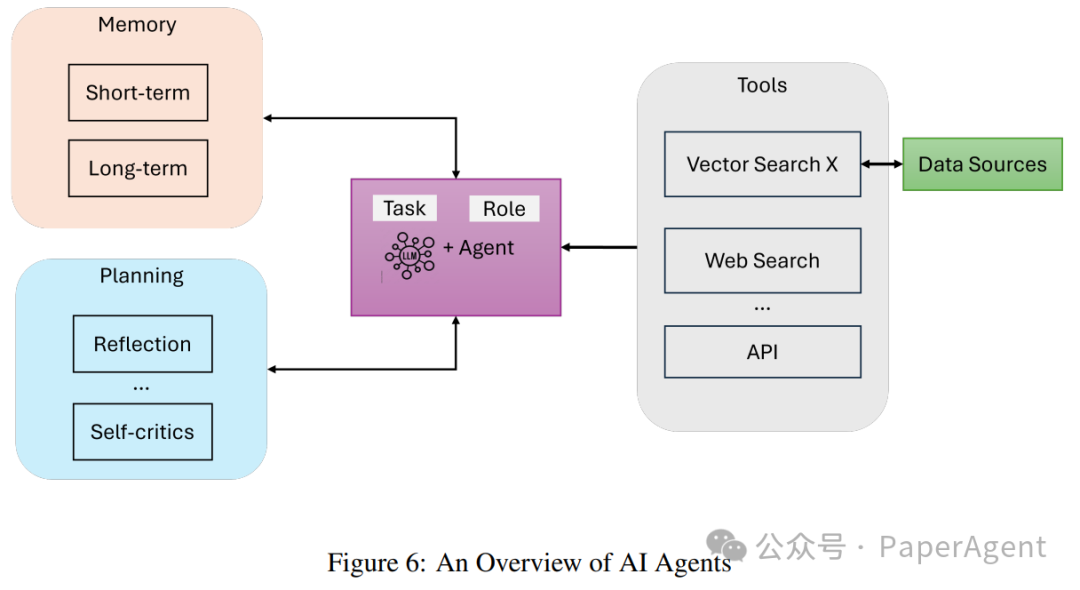
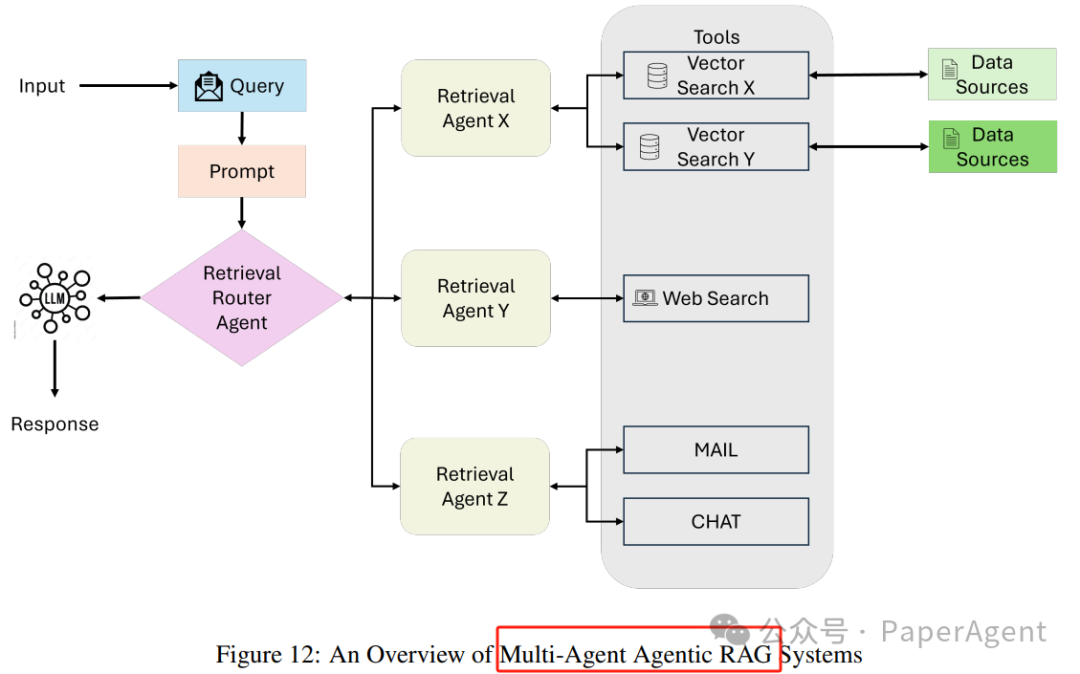
Agentic RAG系统
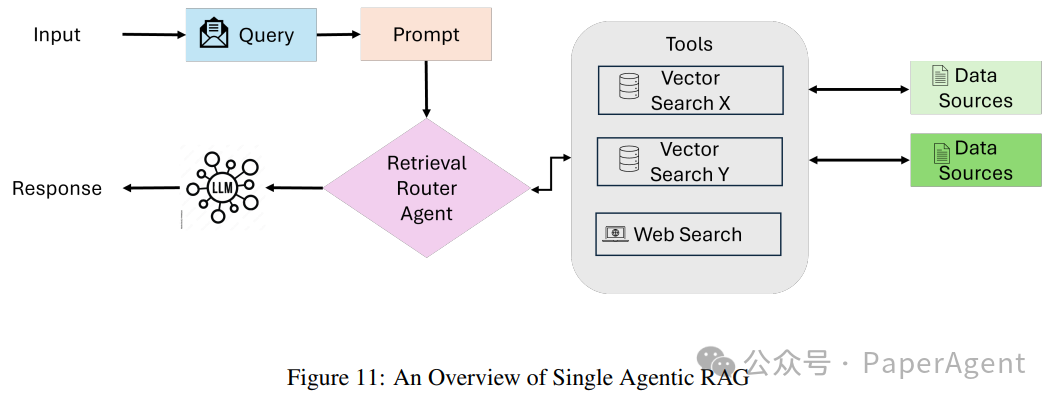
Single-Agent Agentic RAG:路由器
单智能体Agentic RAG系统作为一个集中的决策系统,其中单一Agent管理信息的检索、路由和整合。这种架构通过将这些任务整合到一个统一的Agent中,简化了系统,特别适用于工具或数据源数量有限的设置。
-
查询提交和评估:用户提交查询,协调代理(或主检索代理)接收查询并分析以确定最合适的信息源。
-
知识源选择:根据查询类型,协调代理从多种检索选项中选择:
-
结构化数据库:对于需要表格数据访问的查询,系统可能使用Text-to-SQL引擎与如PostgreSQL或MySQL等数据库交互。
-
语义搜索:处理非结构化信息时,使用基于向量的检索获取相关文档(例如PDF、书籍、组织记录)。
-
网络搜索:对于实时或广泛上下文信息,系统利用网络搜索工具访问最新的在线数据。
-
推荐系统:对于个性化或上下文查询,系统利用推荐引擎提供定制化建议。
-
数据整合和LLM合成:从选定源检索到的相关数据传递给大型语言模型(LLM)。LLM合成收集的信息,将多个来源的见解整合成连贯且上下文相关的回答。
-
输出生成:系统最终生成一个全面的、面向用户的答案,以解决原始查询。此回答以可操作、简洁的格式呈现,可能包括对使用源的引用或引用。
Multi-Agent Agentic RAG
多智能体RAG系统是单智能体架构的模块化和可扩展演变,通过利用多个专门的代理来处理复杂工作流程和多样化的查询类型。与依赖单一智能体管理所有任务(推理、检索和回答生成)不同,此系统将责任分配给多个智能体,每个智能体针对特定角色或数据源进行优化。
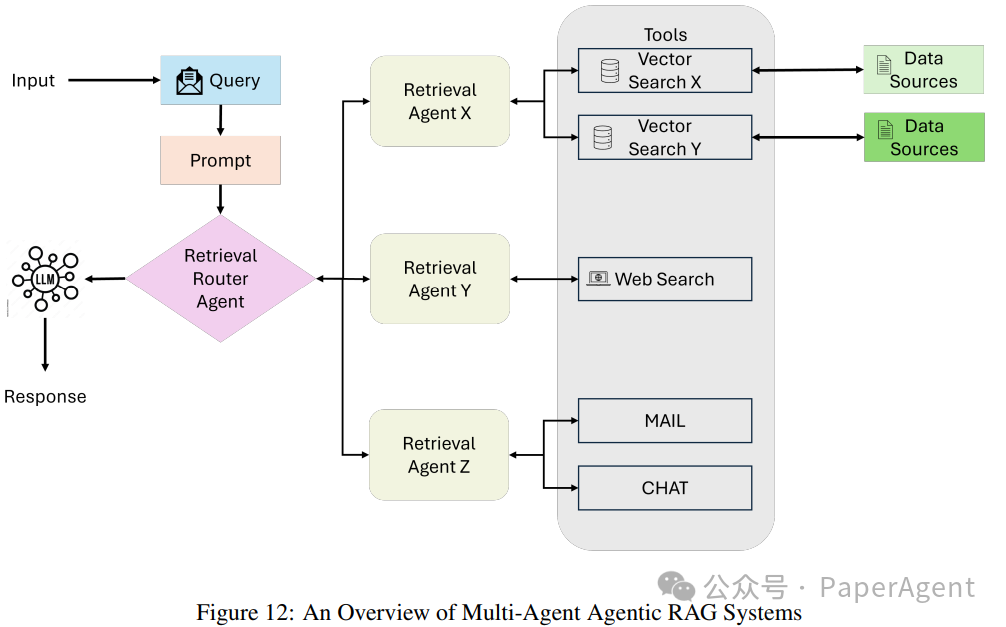
工作流程:
-
查询提交:用户查询被协调代理或主检索代理接收。此代理作为中央协调器,根据查询要求将查询委托给专门的检索代理。
-
专门检索代理:查询在多个检索代理之间分配,每个代理专注于特定类型的数据源或任务。例如:
-
代理1:处理结构化查询,如与基于SQL的数据库(如PostgreSQL或MySQL)交互。
-
代理2:管理语义搜索,检索来自PDF、书籍或内部记录等非结构化数据。
-
代理3:专注于从网络搜索或API检索实时公共信息。
-
代理4:专门从事推荐系统,根据用户行为或配置文件提供上下文感知建议。
-
工具访问和数据检索:每个代理将其查询路由到其域内的适当工具或数据源,例如:
-
向量搜索:用于语义相关性。
-
Text-to-SQL:用于结构化数据。
-
网络搜索:用于实时公共信息。
-
API:用于访问外部服务或专有系统。检索过程并行执行,允许高效处理多样化的查询类型。
-
数据整合和LLM合成:检索完成后,所有代理的数据传递给大型语言模型(LLM)。LLM将检索到的信息合成连贯且上下文相关的回答,无缝整合多个来源的见解。
-
输出生成:系统生成一个全面的回答,以可操作且简洁的格式返回给用户。
层次化 Agentic RAG
层次化Agentic RAG系统采用结构化的多层次方法进行信息检索和处理,增强效率和战略决策制定。代理按层次结构组织,高级代理监督和指导低级代理。这种结构实现了多级决策,确保查询由最合适的资源处理。
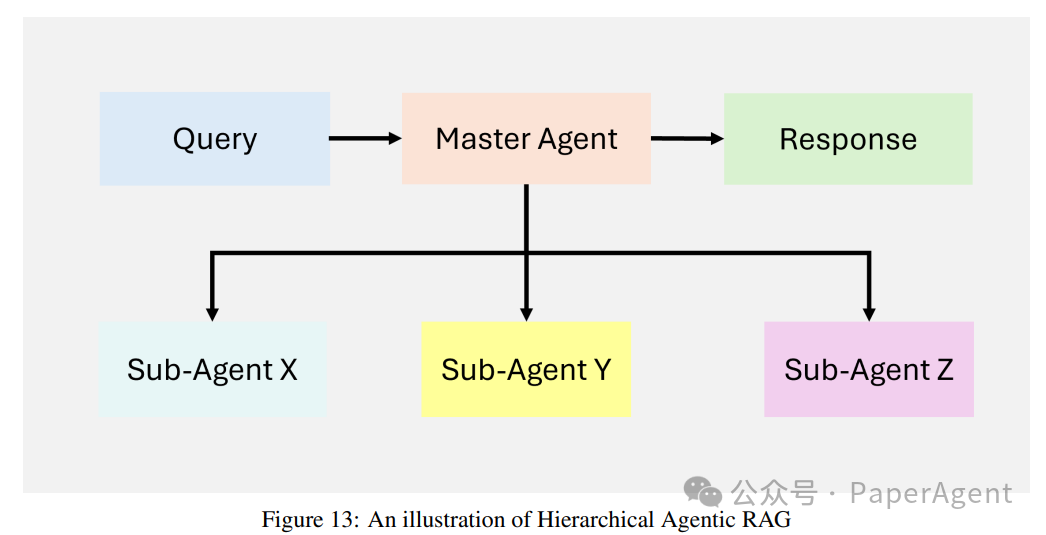
工作流程:
-
查询接收:用户提交查询,由顶级代理接收,负责初步评估和委派。
-
战略决策制定:顶级代理评估查询的复杂性,并决定优先考虑哪些下属代理或数据源。根据查询的领域,某些数据库、API或检索工具可能被认为更可靠或相关。
-
委派给下属代理:顶级代理将任务分配给专门于特定检索方法的低级代理(例如,SQL数据库、网络搜索或专有系统)。这些代理独立执行其分配的任务。
-
聚合和合成:下属代理的结果由高级代理收集和整合,该代理将信息合成连贯的回答。
-
回答交付:最终合成的答案返回给用户,确保回答既全面又上下文相关。
Agentic Corrective RAG
Corrective RAG引入了自我纠正检索结果的机制,增强文档利用并提高回答生成质量。通过将智能代理嵌入工作流程,Corrective RAG确保迭代细化上下文文档和回答,最小化错误并最大化相关性。
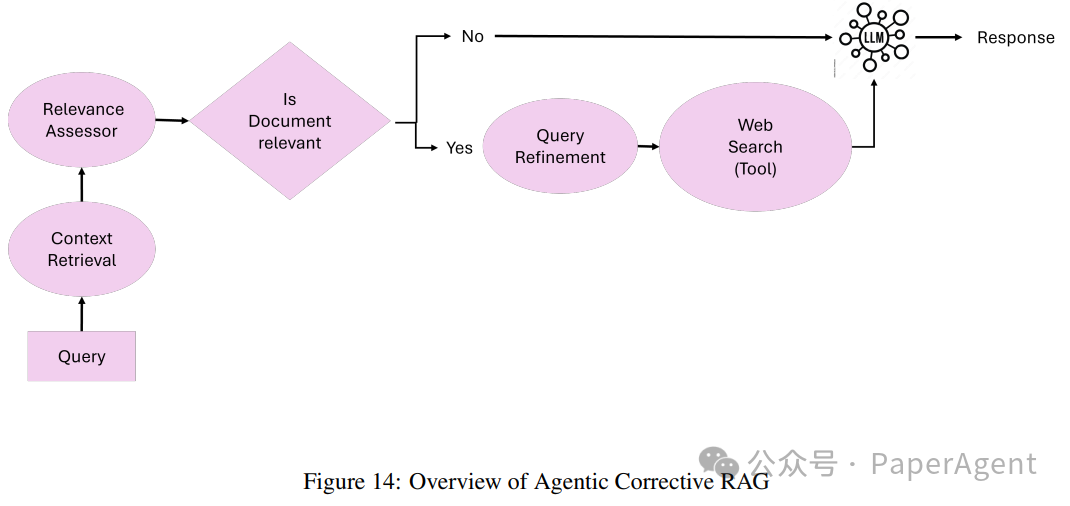
Corrective RAG的核心理念:Corrective RAG的核心原则在于其能够动态评估检索到的文档,执行纠正措施,并细化查询以提高生成回答的质量。Corrective RAG调整其方法如下:
-
文档相关性评估:检索到的文档由相关性评估代理进行评估。低于相关性阈值的文档触发纠正步骤。
-
查询细化和增强:查询由查询细化代理进行细化,该代理利用语义理解来优化检索以获得更好的结果。
-
从外部源动态检索:当上下文文档不足时,外部知识检索代理执行网络搜索或访问替代数据源以补充检索到的文档。
-
回答合成:所有经过验证和细化的信息传递给回答合成代理以生成最终回答。
工作流程:Corrective RAG系统基于五个关键代理构建:
-
上下文检索代理:负责从向量数据库中检索初始上下文文档。
-
相关性评估代理:评估检索到的文档的相关性,并标记任何不相关或模糊的文档以进行纠正措施。
-
查询细化代理:重写查询以提高检索的特异性和相关性,利用语义理解来优化结果。
-
外部知识检索代理:当上下文文档不足时,执行网络搜索或访问替代数据源。
-
回答合成代理:将所有经过验证的信息整合成连贯且准确的回答。
自适应Agentic RAG
自适应检索增强生成(Adaptive RAG)通过根据传入查询的复杂性动态调整查询处理策略,增强了大型语言模型(LLMs)的灵活性和效率。与静态检索工作流程不同,Adaptive RAG使用分类器评估查询复杂性,并确定最适当的方法,范围从单步检索到多步推理,甚至对于简单查询直接跳过检索。
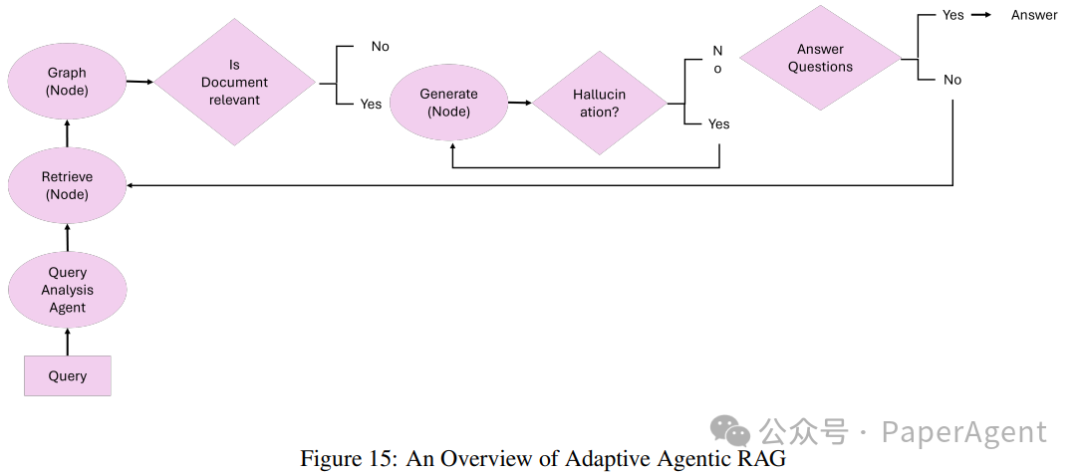
Adaptive RAG的核心理念:Adaptive RAG的核心原则在于其能够根据查询的复杂性动态调整检索策略。Adaptive RAG调整其方法如下:
-
简单查询:对于基于事实的问题,无需额外检索(例如,“水的沸点是多少?”),系统直接使用预存知识生成答案。
-
简单查询:对于中等复杂度的任务,需要最少上下文(例如,“我最新的电费账单状态是什么?”),系统执行单步检索以获取相关详细信息。
-
复杂查询:对于需要迭代推理的多层次查询(例如,“过去十年城市X的人口如何变化,有哪些促成因素?”),系统采用多步检索,逐步细化中间结果以提供全面答案。
工作流程:Adaptive RAG系统基于三个主要组件构建:
-
分类器角色:
-
较小的语言模型分析查询以预测其复杂性。
-
分类器使用从过去模型结果和查询模式派生的自动标记数据集进行训练。
-
动态策略选择:
-
对于简单查询,系统避免不必要的检索,直接利用LLM生成回答。
-
对于简单查询,它执行单步检索过程以获取相关上下文。
-
对于复杂查询,它激活多步检索以确保迭代细化和增强推理。
-
LLM整合:
-
LLM将检索到的信息合成连贯的回答。
-
LLM和分类器之间的迭代交互使复杂查询的细化成为可能。
基于图的Agentic RAG
Agent-G引入了一种新颖的代理架构,将图知识库与非结构化文档检索相结合。通过结合结构化和非结构化数据源,该框架增强了检索增强生成(RAG)系统,提高了推理和检索精度。它采用模块化检索器库、动态代理交互和反馈循环,以确保高质量输出。
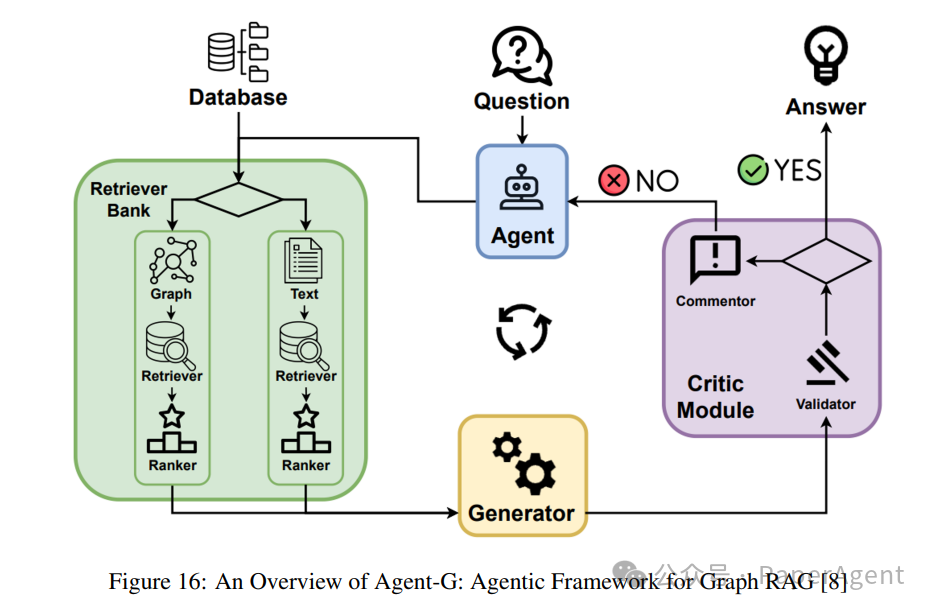
Agent-G的核心理念:Agent-G的核心原则在于其能够动态地将检索任务分配给专门的代理,利用图知识库和文本文档。Agent-G调整其检索策略如下:
-
图知识库:使用结构化数据提取关系、层次结构和连接(例如,医疗保健中的疾病到症状映射)。
-
非结构化文档:传统的文本检索系统提供上下文信息以补充图数据。
-
批评模块:评估检索到信息的相关性和质量,确保与查询一致。
-
反馈循环:通过迭代验证和重新查询细化检索和合成。
工作流程:Agent-G系统基于四个主要组件构建:
-
检索器库:
-
一组专门的代理,专注于检索基于图或非结构化数据。
-
代理根据查询的要求动态选择相关源。
-
批评模块:
-
验证检索到的数据的相关性和质量。
-
标记低置信度结果以进行重新检索或细化。
-
动态代理交互:
-
针对特定任务的代理协作,整合多样化数据类型。
-
确保图和文本源之间的连贯检索和合成。
-
LLM整合:
-
将经过验证的数据合成连贯的回答。
-
批评模块的迭代反馈确保与查询意图一致。
Agentic文档工作流
智能体文档工作流(Agentic Document Workflows, ADW)扩展了传统的检索增强生成(RAG)范式,实现了端到端的知识工作自动化。这些工作流协调复杂的以文档为中心的过程,整合文档解析、检索、推理和结构化输出与智能代理。ADW系统通过维护状态、协调多步工作流,并将领域特定逻辑应用于文档,解决了智能文档处理(IDP)和RAG的限制。
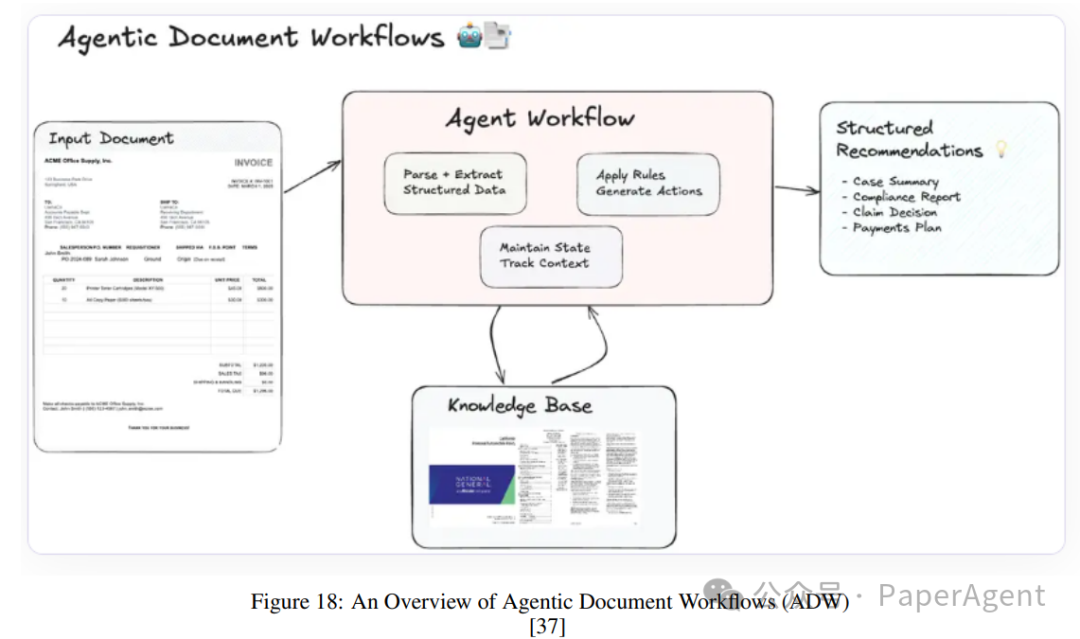
工作流程:
-
文档解析和信息结构化:
-
使用企业级工具(例如LlamaParse)解析文档,提取相关数据字段,如发票号码、日期、供应商信息、明细项和付款条款。
-
将结构化数据组织起来以便于下游处理。
-
跨流程的状态维护:
-
系统维护文档上下文的状态,确保多步工作流之间的一致性和相关性。
-
跟踪文档在各个处理阶段的进展。
-
知识检索:
-
从外部知识库(例如LlamaCloud)或向量索引中检索相关参考文献。
-
检索实时的领域特定指南以增强决策制定。
-
代理协调:
-
智能代理应用业务规则,执行多跳推理,并生成可操作的建议。
-
协调诸如解析器、检索器和外部API等组件,实现无缝整合。
-
可操作输出生成:
-
以结构化格式呈现输出,针对特定用例进行定制。
-
将建议和提取的见解整合成简洁且可操作的报告。
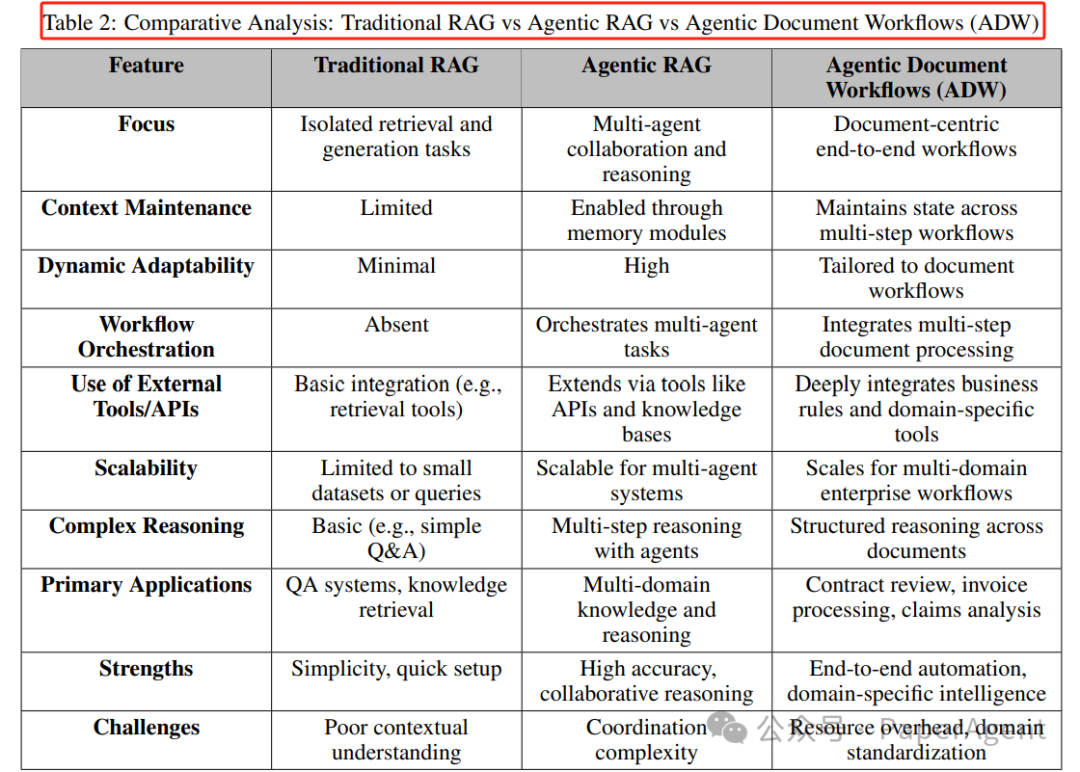
传统RAG与Agentic RAG与Agentic文档工作流(ADW)对比
https://arxiv.org/abs/2501.09136Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
(文:PaperAgent)
RAG技术要上天了!2025年肯定会更厉害,Agentic RAG就是个大神,自主Agent动态决策,未来AI definitely sky!!