


2025年4月1日,百度飞桨(PaddlePaddle)框架3.0正式版发布。
飞桨框架3.0全新发布 “自动并行训练、编译优化、推理加速、科学计算支持、国产硬件适配” 是这次的核心升级方向,为开发者提供了高性能、低成本的开发工具。干货满满!

飞桨框架3.0在性能层面实现了全方位突破,成为大模型开发、部署的效率标杆。
训练端,动静结合自动并行技术大幅简化分布式策略开发,Llama2-13B训练性能达2055.8 tokens/秒,较竞品提升28.3%,代码量减少96%;神经网络编译器CINN通过一阶段编译与智能算子融合,使RMSNorm等关键算子速度提升4倍,PaddleX系列模型平均性能提升27.4%。
推理端,依托FP8/4bit量化与硬件指令级优化,DeepSeek R1单机吞吐突破2000+ tokens/秒,MTP投机解码技术提升吞吐144%;长序列首token生成速度优化37%,资源消耗降低50%。
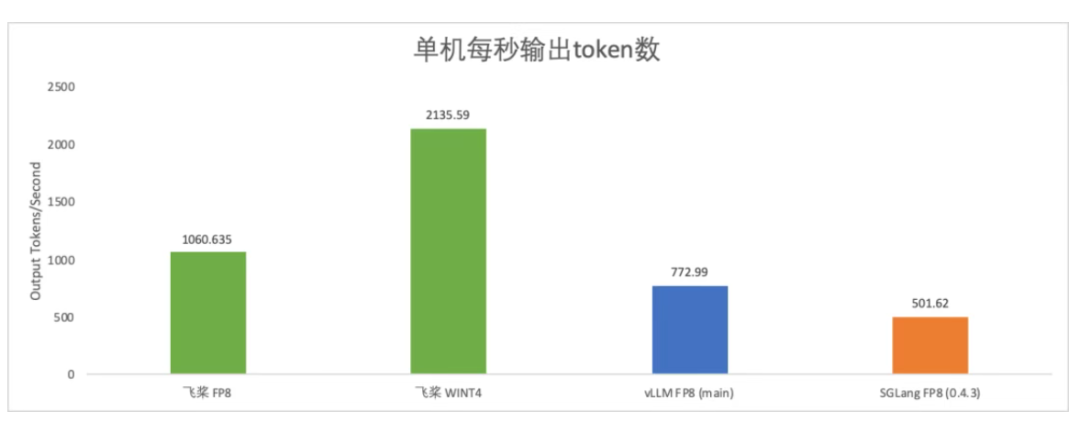
4比特量化单机高速推理部署方案
飞桨框架3.0在量化推理领域实现重大突破,全面支持Weight Only INT8/INT4量化技术,为不同硬件环境提供灵活高效的部署选择。

-
Hopper架构适配:支持DeepSeek V3/R1满血版及蒸馏版模型的FP8推理,充分释放Hopper GPU的TensorCore潜力。
-
A800高性能部署:通过Weight Only INT8量化技术,在A800 GPU上实现高精度、低时延推理,兼顾性能和能效。
-
单机极简部署:基于Weight Only INT4量化方案,飞桨框架3.0首次支持大模型单机无损压缩部署,彻底消除跨机通信开销。实测相比传统2机部署方案,单机部署在相同并发量下推理速度提升101%~128%,为中小规模场景提供“零通信损耗、极致性价比”的落地范式。
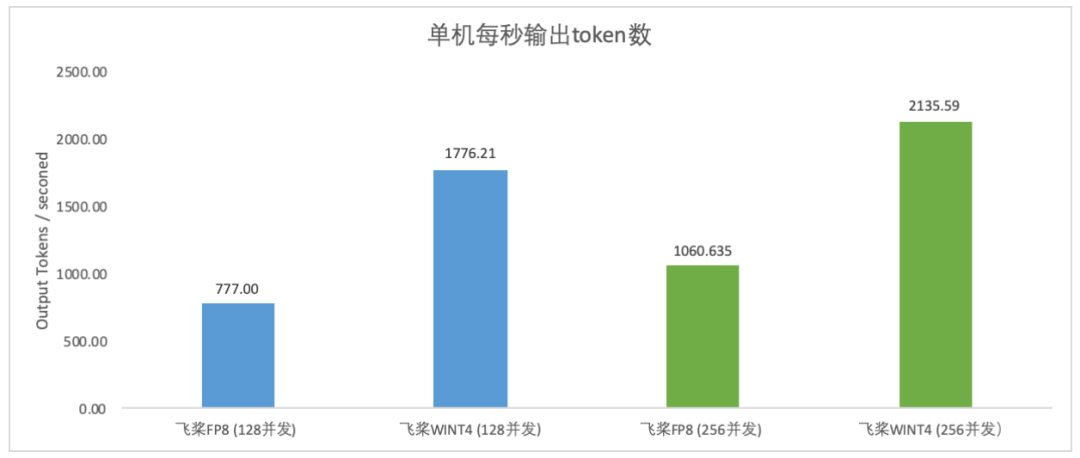
长序列注意力量化加速
—–突破大模型推理效率边界
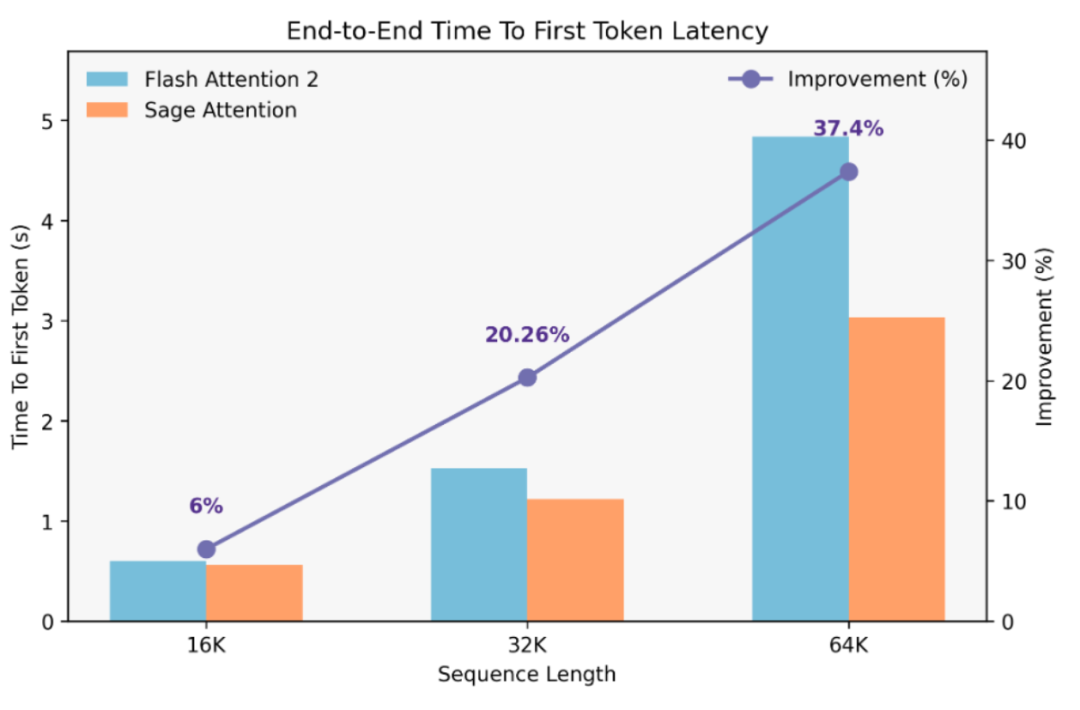
针对长序列输入场景下注意力(Attention)计算复杂度与序列长度平方成正比的性能瓶颈,飞桨框架3.0创新推出SageAttention动态量化加速方案,在Hopper架构GPU上实现精度与效率的完美平衡。
以DeepSeek模型(Head Dim=192)为例,该方案通过以下技术路径显著优化长序列推理性能:
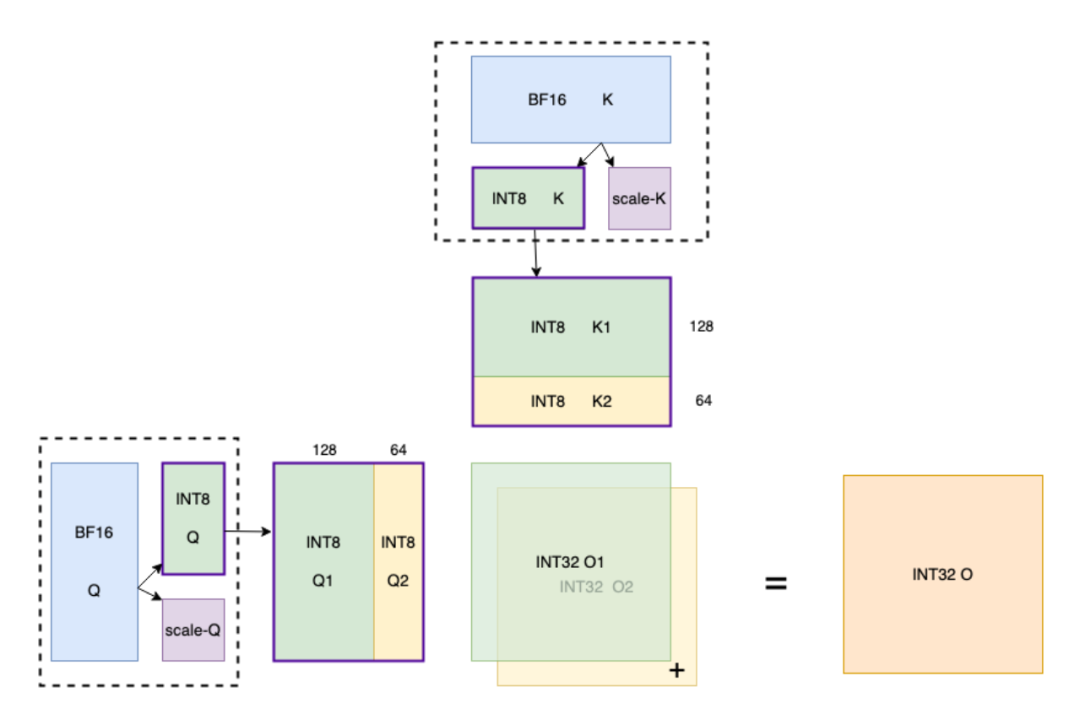
1、动态混合精度量化:
-
Q/K矩阵INT8量化:将Query和Key矩阵动态量化为INT8,减少矩阵乘法的计算与访存开销。
-
V矩阵FP8量化:保留Value矩阵的FP8精度,兼顾数值稳定性与计算效率。
2、分层计算优化:
-
Softmax阶段加速:将INT32格式的Q*K中间结果转换为FP32进行反量化,结合在线式(Online)Softmax计算,避免显存峰值压力。
-
结果矩阵融合:将Softmax输出P量化为FP8,与FP8量化的V矩阵相乘后,仅需一次反量化即可获得最终Attention结果O,最大限度降低计算冗余。
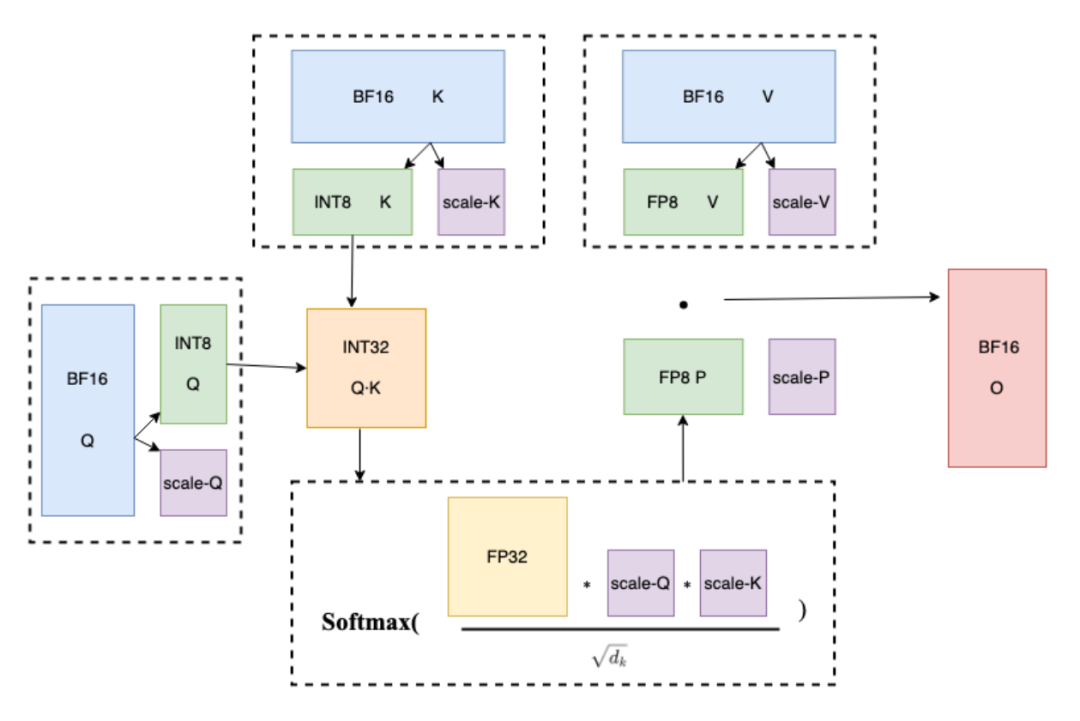
3、端到端性能跃升:
上述两次量化-反量化过程在严格精度控制下,将64K长文本输入的首token推理速度提升37.4%,且模型效果损失可忽略不计(精度保留率超99.5%)。
MTP高效推理
—–突破大批次解码性能瓶颈
投机解码通过“以小搏大”策略优化大模型推理效率,以极低额外时延生成多个Draft Token,通过基础模型快速验证其合理性,从而减少整体推理耗时。其核心价值在于平衡QPS与延迟,尤其适用于高并发、低时延要求的场景,如实时对话、搜索推荐。
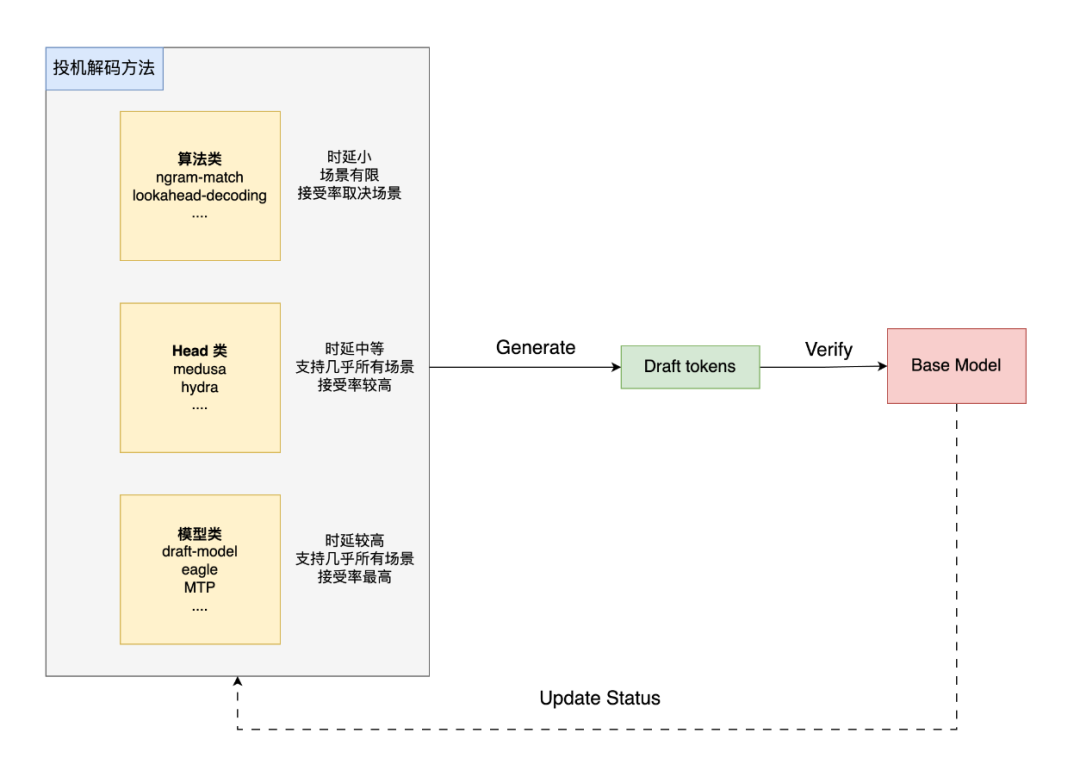
飞桨框架3.0针对类Draft Model系列方法(如MTP、Eagle)设计了灵活可扩展的解码架构。
1、解耦设计:
分离基础模型与投机解码策略,支持通过少量代码适配新方法,模型结构与常规Transformer一致(含Embedding/LM Head、CacheKV等模块)。
2、统一处理逻辑:
-
多状态支持:单次前向传播(Forward)即可处理全部Draft Token的接受状态(全部拒绝、部分接受、全部接受)
-
后处理加速:融合模型状态更新算子,性能较传统方案提升2-4倍。
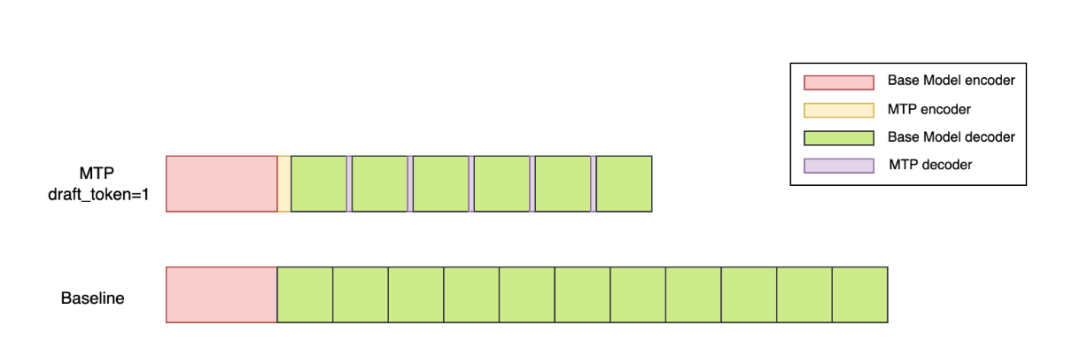
以下是 MTP 推理时的时序图:
一键启动推理服务
飞桨官方提供了一键启动脚本,能让大家快速启动DeepSeek并进行推理请求。
单机WINT4推理
以1台H800为例,部署单机4比特量化推理服务。
-
设置变量model_name声明需要下载的模型。
-
设置模型存储路径MODEL_PATH,默认挂载至容器内/models路径下
export MODEL_PATH=${MODEL_PATH:-$PWD}export model_name="deepseek-ai/DeepSeek-R1/weight_only_int4"docker run \--gpus all \--shm-size 32G \--network=host \--privileged \--cap-add=SYS_PTRACE \-v $MODEL_PATH:/models \-e "model_name=${model_name}" \-e "MP_NUM=8" \-e "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \-dit \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 \/bin/bash -c -ex 'start_server $model_name && tail -f /dev/null'&& docker logs -f $(docker ps -lq)
两机推理
# 第一个节点(master)ping 192.168.0.1# 第二个节点(slave)ping 192.168.0.2
在2个节点上分别执行下列以下命令,一键启动多机推理镜像。
export MODEL_PATH=${MODEL_PATH:-$PWD}export model_name="deepseek-ai/DeepSeek-R1-2nodes/weight_only_int8" #可更换FP8模型export MP_NNODE=${MP_NNODE:-2}export MP_NUM=${MP_NUM:-16}export POD_0_IP=${POD_0_IP:-"192.168.0.1"}export POD_IPS=${POD_IPS:-"192.168.0.1,192.168.0.2"}export BATCH_SIZE=${BATCH_SIZE:-128}export BLOCK_BS=${BLOCK_BS:-40}docker run \--gpus all \--shm-size 32G \--network=host \--privileged \--cap-add=SYS_PTRACE \-v $MODEL_PATH:/models \-e "model_name=${model_name}" \-e "MP_NUM=${MP_NUM}" \-e "MP_NNODE=${MP_NNODE}" \-e "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \-e "POD_0_IP=${POD_0_IP}" \-e "POD_IPS=${POD_IPS}" \-e "BATCH_SIZE=${BATCH_SIZE}" \-e "BLOCK_BS=${BLOCK_BS}" \-dit \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 \/bin/bash -c -ex 'start_server $model_name && tail -f /dev/null'&& docker logs -f $(docker ps -lq)
curl请求示例
curl ${ip}:9965/v1/chat/completions \-H 'Content-Type: application/json' \-d '{"model":"default","text":"Hello, how are you?"}'
OpenAI SDK请求示例
import openaiclient = openai.Client(base_url=f"http://127.0.0.1:9965/v1/chat/completions", api_key="EMPTY_API_KEY")# 非流式返回response = client.completions.create(model="default",prompt="Hello, how are you?",max_tokens=50,stream=False,)print(response)print("\n")# 流式返回response = client.completions.create(model="default",prompt="Hello, how are you?",max_tokens=100,stream=True,)for chunk in response:if chunk.choices[0] is not None:print(chunk.choices[0].text, end='')print("\n")
结语
从 2016 年开源到 2025 年飞桨框架3.0发布,飞桨不仅实现了从训练框架到 AI 基础设施的进化,更是构建起覆盖 1808 万开发者、43 万家企业的产业生态,推动大模型技术从实验室走向千行百业。
当 AI 开发进入 “大模型 + 全场景” 时代,飞桨框架 3.0 以技术创新与生态协同双轮驱动,正在重新定义大模型研发的效率标杆,为智能经济发展奠定坚实的技术底座。
“一次开发,多端部署” 是飞桨的核心理念,飞桨正成为连接技术创新与产业落地的智能桥梁,引领AI基础设施进入普惠化、标准化的新阶段。
相信飞桨作为国产AI之光肯定会做得越来越好。

(文:开源AI项目落地)