

PAPO团队 投稿
量子位 | 公众号 QbitAI
让大模型在学习推理的同时学会感知。
伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。
现有的强化学习算法(如GRPO)虽然在纯文本推理中表现优异,但当应用于多模态场景时,往往无法充分利用视觉信息进行推理。

-
GRPO错误:未能正确感知和区分不同物体 -
PAPO正确:准确识别不同物体并准确计数
近期有许多工作专注于提升强化学习再多模态场景中的应用,但大多集中在从数据(Data,Rollout)以及奖励机制(Reward)的设计,很少设计对于核心GRPO算法的改动。
而PAPO通过创新的隐式感知损失设计,仅依赖于内部监督信号,让多模态大模型在学习推理的同时学会感知,从根本上解决了现有方法中感知与推理脱节的问题。

PAPO的模型和数据均已开源,详细可见文末链接。
错误分析:发现感知瓶颈
PAPO的第一个重要贡献是通过系统性的错误分析发现了多模态推理中的核心问题,也就是视觉感知的准确性问题。
PAPO团队对使用GRPO训练的Qwen2.5-VL-3B模型在四个基准数据集上的200个错误案例进行详细的人工分析和分类,结果显示:
-
感知错误占67.0%:模型无法准确解读视觉内容,如空间关系判断错误、标签关联错误等; -
推理错误占18.0%:逻辑推理过程中的错误,如应用错误的定理或规则; -
计算错误占10.0%:算术运算错误; -
不一致错误占5.0%:中间推理步骤与最终答案不符。
这一发现颠覆了人们对多模态推理失败原因的普遍认知——问题主要不在于逻辑推理能力,而在于视觉感知的准确性。

上图展现了一个典型例子:在一个几何推理任务中,用户询问”Find x”,正确答案是9。
使用传统GRPO训练的模型会错误地将x与60度角对应的边关联,犯了感知错误;而PAPO训练的模型则正确识别了x是30度角对应的短边,得到了正确答案。
这个例子清晰地展示了PAPO在提升视觉感知准确性方面的显著效果。
PAPO:创新的内驱感知策略优化算法
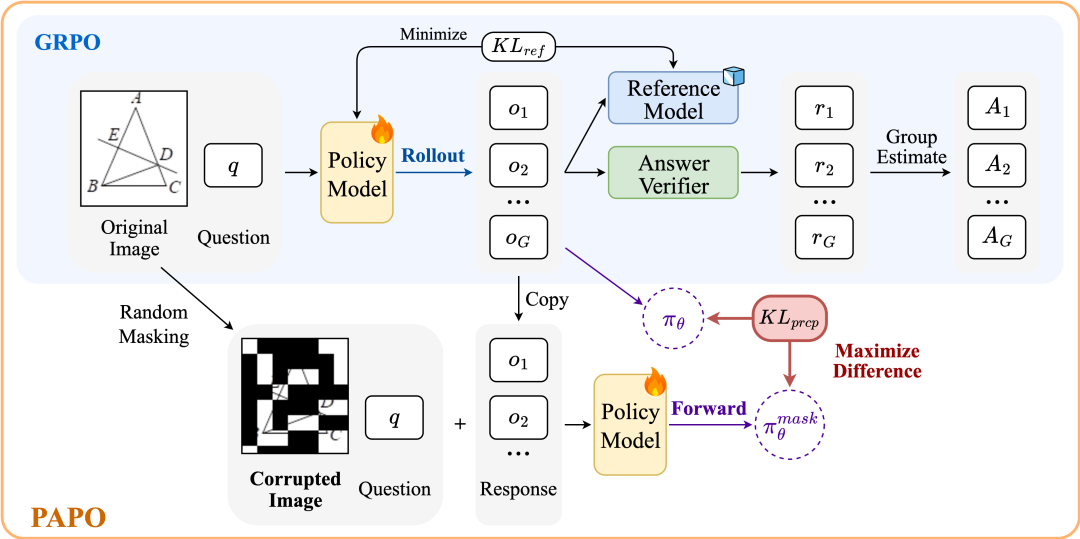
基于上述发现,PAPO提出了创新的隐式感知损失(Implicit Perception Loss)设计。
该方法的核心思想是:一个优秀的多模态推理模型应该在原始图像和损坏图像上产生显著不同的输出分布,这表明模型真正依赖于有意义的视觉内容。
下图展示了PAPO目标函数与传统GRPO的对比:

PAPO的技术创新包括:
感知信息增益比设计:定义了感知信息增益比rprcp=πθ(o|q,I)/π_θ(o|q,I_mask),其中I_mask是通过随机遮盖补丁生成的损坏图像。
KL散度最大化:通过最大化KL散度DKL[πθ(o|q,I)||π_θ(o|q,I_mask)],鼓励模型在原始图像和损坏图像上产生不同的输出。
无缝集成GRPO:PAPO作为GRPO的简单扩展,完整的目标函数为:J_PAPO=J_GRPO+γ·KL_prcp
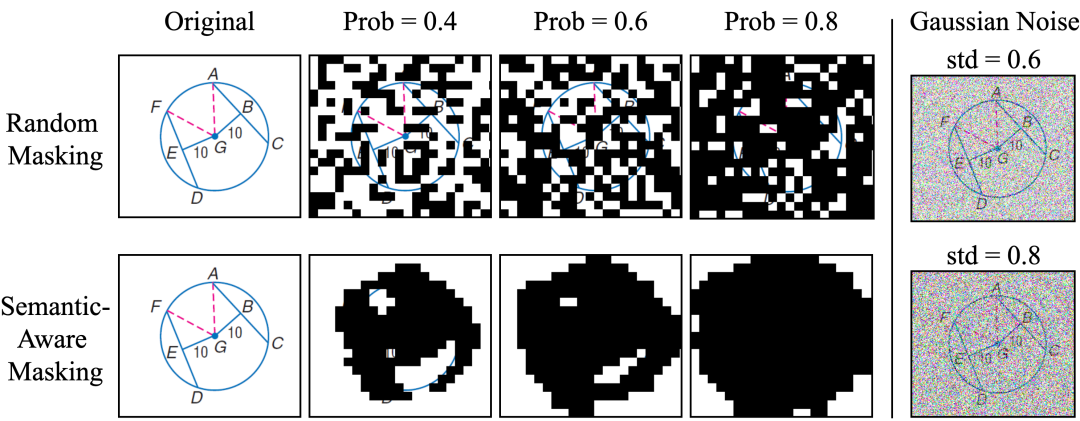
在损坏图像的遮盖上,PAPO探索了两种图像基于Patch的掩码策略来生成损坏图像I_mask。
如上图所示,与加入噪声的方式不同,基于Patch的掩码方式更能有效移除图像的语义信息:
-
随机遮盖:简单高效,随机选择图像补丁进行遮盖; -
语义感知遮盖:利用DINOv2预训练模型识别显著区域并优先遮盖。
后续实验表明,尽管随机遮盖方法更简单,但效果反而优于复杂的语义感知遮盖,这可能是因为语义感知遮盖倾向于完全遮盖显著对象,而随机遮盖能保持更好的平衡。
实验验证:多方位超越GRPO

PAPO团队在8个多模态推理基准上对Qwen2.5-VL-3B和7B模型进行了全面评估。实验结果显示,PAPO在所有基准上都取得了一致的改进。
实现了4.4%的整体平均提升,高视觉依赖任务(如LogicVista、SuperClevrCounting)的8.0%显著提升;30.5%的感知错误减少。
上述实验结果表明,PAPO成功解决了多模态推理中的感知瓶颈,无需额外的计算资源或外部模型。
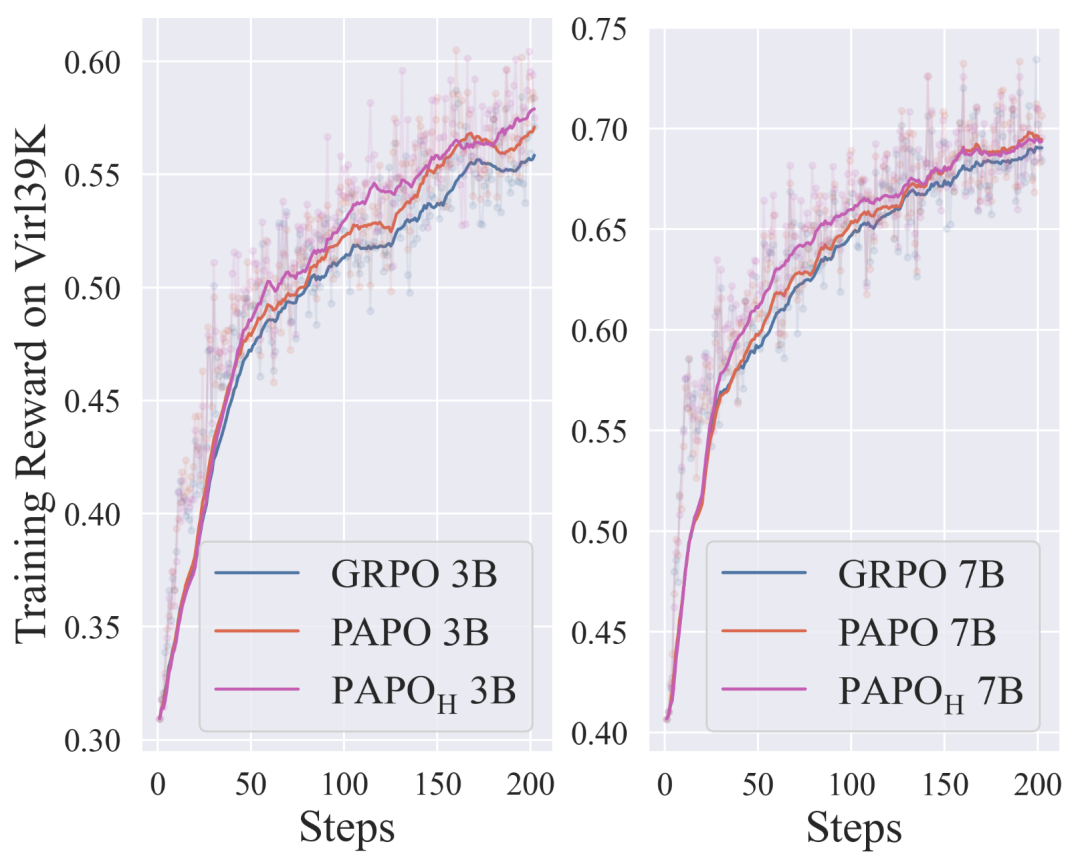
在训练动态分析中,PAPO相比GRPO也展现出明显更优的训练动态特征:
-
更快收敛:PAPO从训练早期(约25步)就开始显现提升 -
更稳定训练:避免了GRPO中常见的奖励不稳定问题 -
持续改进:随着训练进程,改进效果不断增强
消融实验
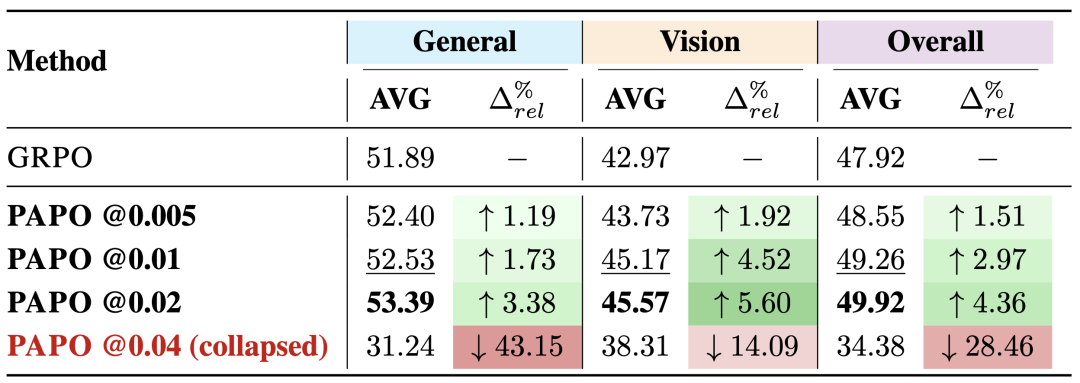
除此之外,PAPO团队还系统研究了隐式感知损失权重γ对性能的影响,发现:
-
γ值适度增大(0.02以内)能带来更显著的改进 -
γ值过大(如0.04)会导致严重的模型崩溃 -
大模型对高γ值更敏感,需要更早的正则化
掩码策略与比例优化
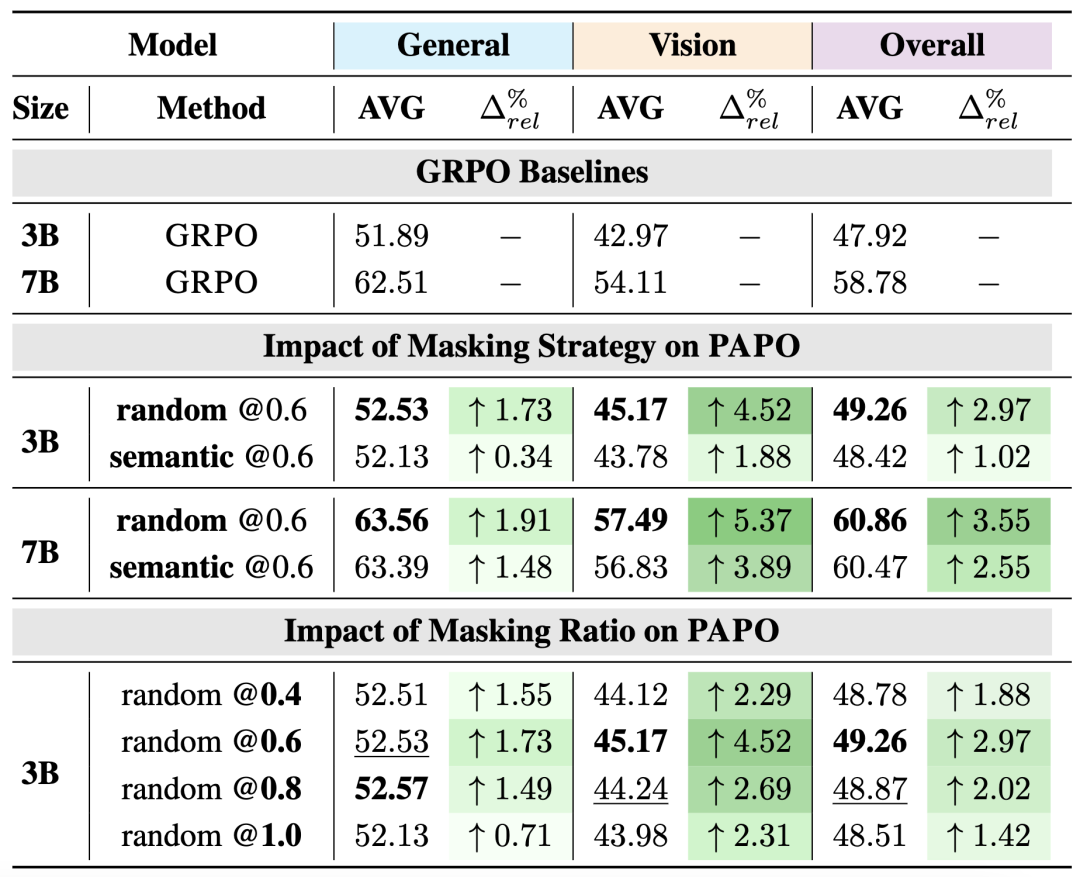
通过分析PAPO掩码策略和比例的影响关键发现:
-
相对大的(0.6-0.8)遮盖比例效果最佳 -
完全遮盖(比例1.0)表现不佳,且容易导致模型崩溃 -
随机遮盖策略尽管简单但优于更复杂的语义感知遮盖
PAPO+移除ReferenceKL的协同效应
PAPO团队验证了PAPO与移除原有的与Reference模型之间的KL约束的组合效果,发现PAPO与现有算法改进高度兼容。
这一结果表明PAPO不仅是一个独立有效的改进,还能与其他优化技术形成协同效应。
技术挑战:KL_prcp Hacking现象
在深入研究PAPO时,研究团队发现了一种特有的模型崩溃现象——KL_prcp Hacking。
当隐式感知损失权重γ设置过大时,模型会“钻空子”过度优化KL_prcp项。
具体表现为Reward快速的下降,熵快速增大,并开始出现生成无关内容。
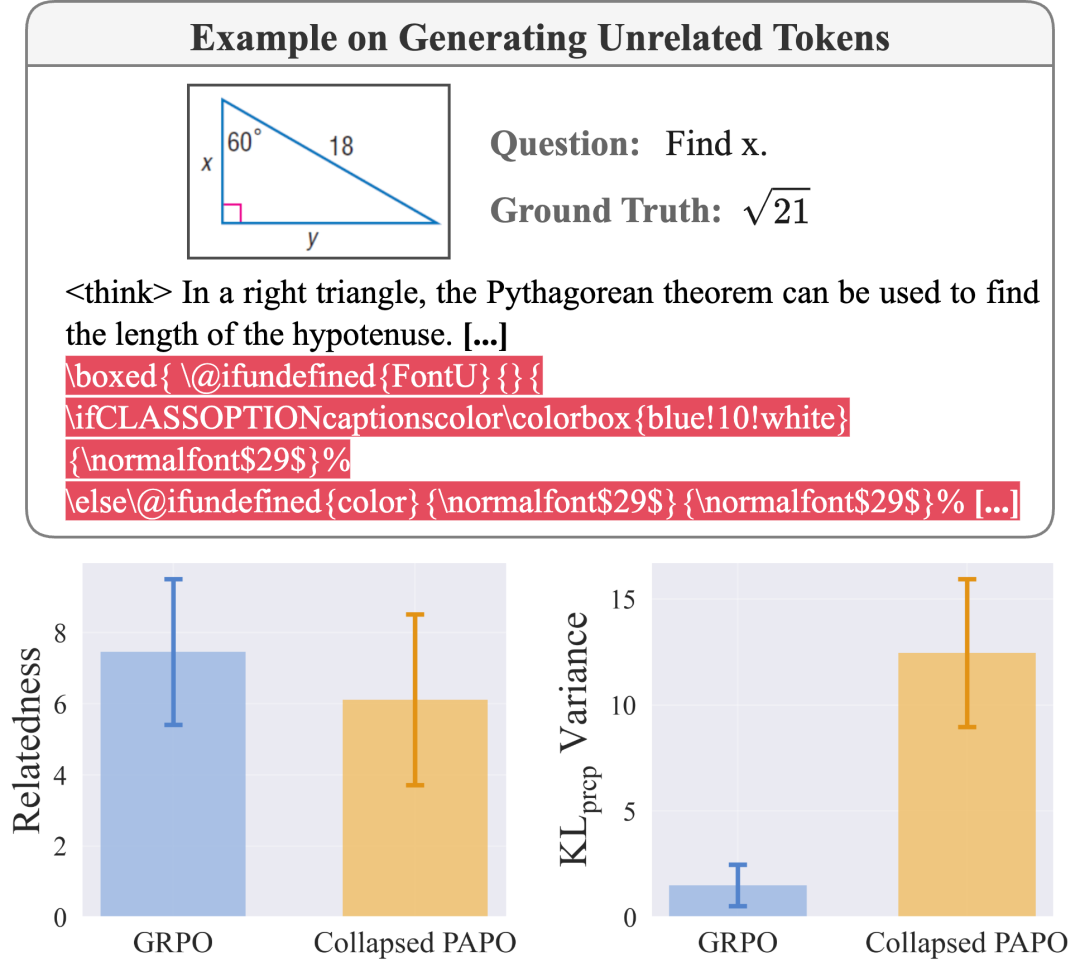
崩溃特征如下:
-
生成与问题无关的Token(相关性降低18%) -
KL_prcp方差增加8.4倍 -
模型输出充斥无意义的LaTeX格式代码
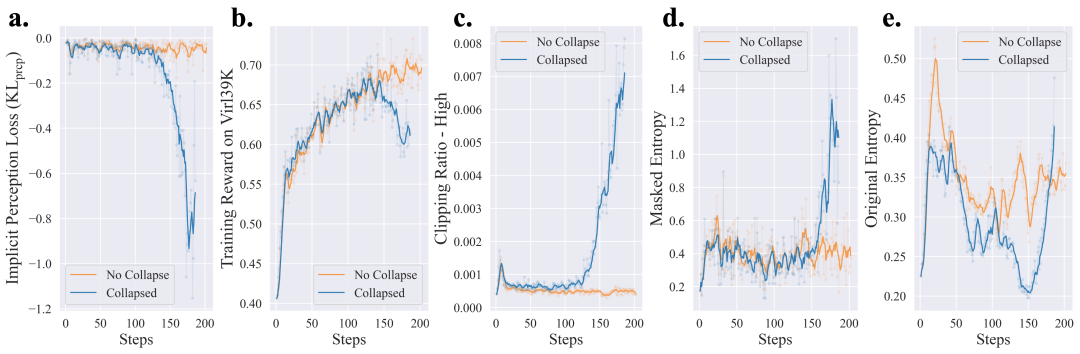
PAPO团队识别了KL_prcp Hacking的早期预警信号,发现了以下几个关键指标:
-
隐式感知损失急剧下降 -
训练奖励崩溃 -
裁剪比例-高持续增长 -
双策略熵损失同时上升
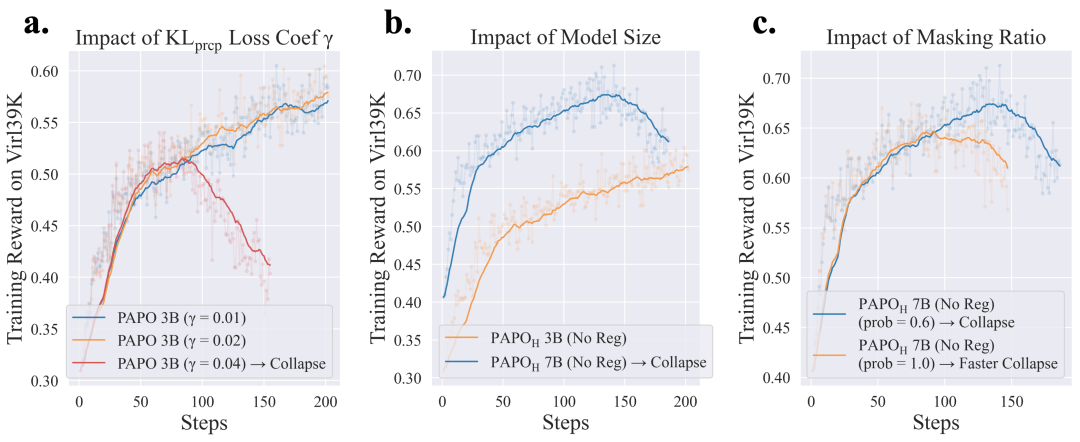
对KL_prcp Hacking的主要影响因素进行分析,发现:
-
损失权重:γ>0.02容易导致崩溃 -
模型规模:大模型更敏感 -
遮盖比例:极端比例(如1.0)风险更高
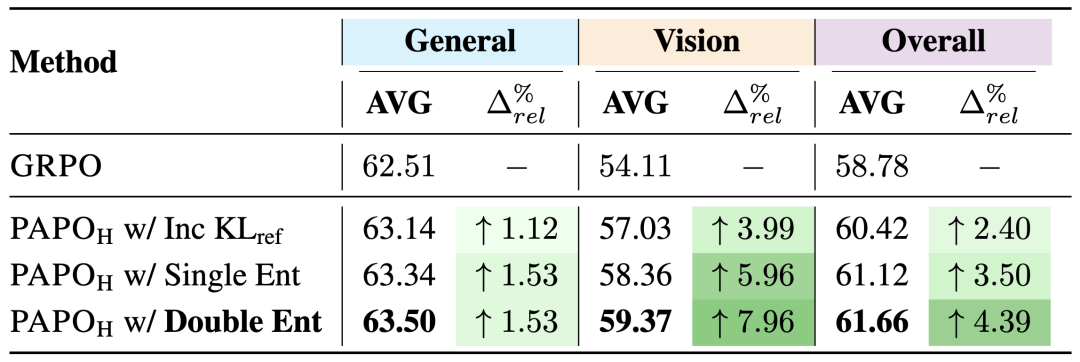
为了在高-γ设置中更好地正则化KLprcp,PAPO团队引入了双重熵损失,这是一种有效的正则化方法,能够在保持性能的同时防止崩溃。
这个想法源于PAPO团队的观察,即πθ和πθ^mask中的展开熵增加是崩溃的早期迹象。双重熵损失鼓励模型保持这两种熵都较低,可以表示为:
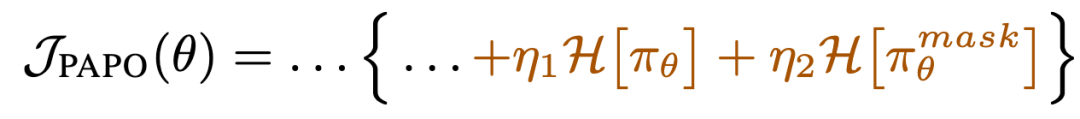
其中H表示熵损失,计算为生成序列的负对数概率,而…部分与上述PAPO目标相同。
实验结果表明,双重熵损失可以在防止崩溃的同时保持最佳性能。
PAPO的视觉依赖性分析
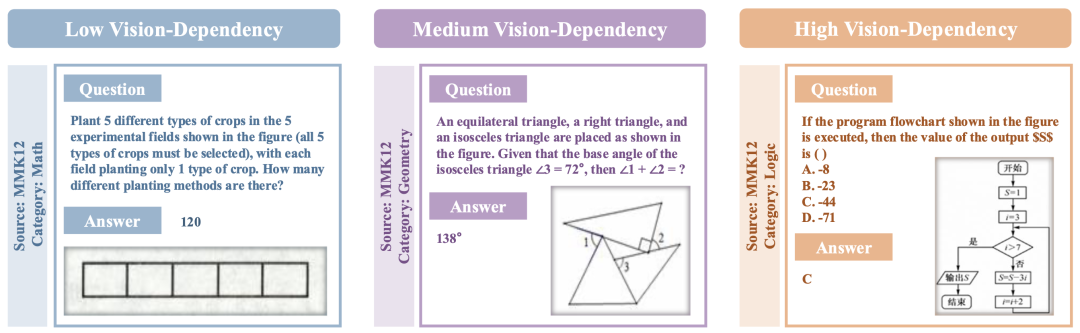
在评估多模态基准的视觉依赖程度时,PAPO团队发现,许多主流的多模态推理基准中实际上包含大量非“多模态”任务。
例如题目的文本部分已经提供了丰富的视觉相关信息,使得模型即便不查看图像也能作出正确回答。
针对这一现象,作者对当前主流数据集进行了系统的视觉依赖性分析,并将任务划分为三个等级:
-
低依赖:文本中包含大部分视觉信息 -
中等依赖:需要视觉和文本信息结合 -
高依赖:主要依靠视觉理解
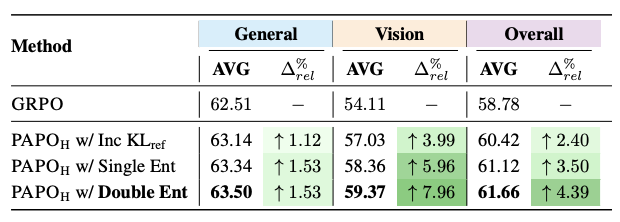
实验结果表明,PAPO在高视觉依赖任务中改进最为显著(接近8%);在中等依赖任务中表现稳定;即使在低依赖任务中也有一致改进。
这一分析进一步验证了PAPO针对感知瓶颈问题的精准定位,以及其进一步提升多模态推理的有效性。
以下是一些实际应用案例:
案例1:直角三角形边长计算

-
GRPO错误:将x与错误的边关联,得到9√3 -
PAPO正确:准确识别x为30度角对应边,得到正确答案9
案例2:圆形几何问题
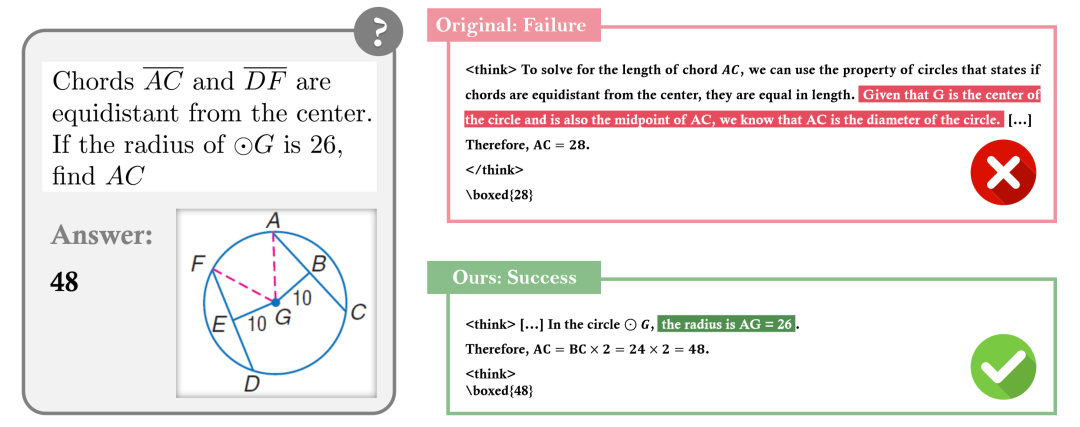
-
GRPO错误:无法正确理解弦与圆心的距离关系 -
PAPO正确:准确把握几何关系,计算出正确结果
案例3:物体计数问题
-
GRPO错误:未能正确感知和区分不同物体 -
PAPO正确:准确识别不同物体并准确计数
案例4:多图逻辑推理问题

-
GRPO错误:错误的视觉感知和视觉推理 -
PAPO正确:准确识别不同子图中的视觉特征,并进行正确的逻辑推理
通过以上案例可以看出,在复杂几何问题中,PAPO显著提升了模型对图形关系的理解。
项目主页:https://mikewangwzhl.github.io/PAPO/
论文:https://arxiv.org/abs/2507.06448
GitHub:https://github.com/MikeWangWZHL/PAPO
模型:https://huggingface.co/collections/PAPOGalaxy/papo-qwen-686d92dd3d43b1ce698f851a
数据:https://huggingface.co/collections/PAPOGalaxy/data-686da53d67664506f652774f
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)