


文章转载自「机器之心」。


01
200 万上下文窗口

-
论文标题:Titans: Learning to Memorize at Test Time -
论文地址:https://arxiv.org/pdf/2501.00663v1
02
学习测试时记忆

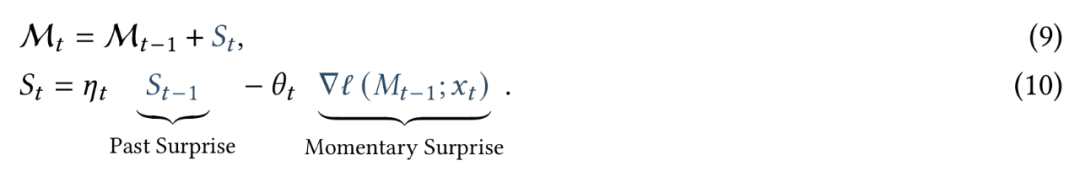
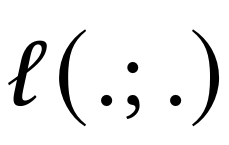 ,它就是我们的记忆在测试时学习充当的目标。也就是说,记忆模块是一个元模型,它基于损失函数来学习一个函数。
,它就是我们的记忆在测试时学习充当的目标。也就是说,记忆模块是一个元模型,它基于损失函数来学习一个函数。



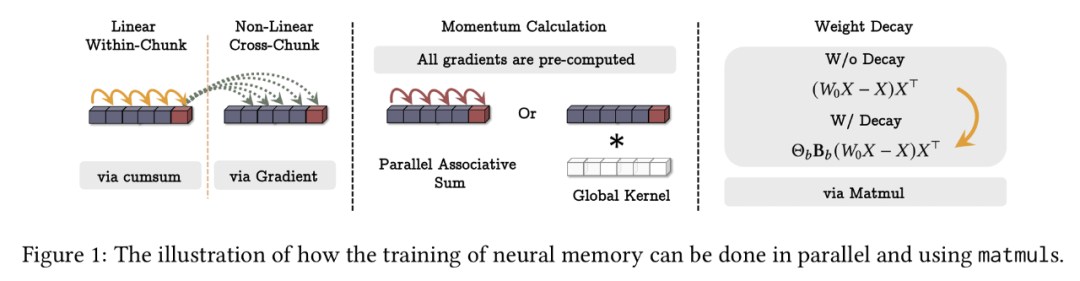
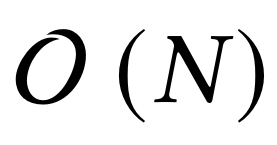 FLOPS,其中 N 为序列长度。不过在实践中,我们需要并行化训练过程并充分利用 TPU、GPU 等硬件加速器,同时需要张量化该过程并使用更多矩阵乘法(matmuls)。
FLOPS,其中 N 为序列长度。不过在实践中,我们需要并行化训练过程并充分利用 TPU、GPU 等硬件加速器,同时需要张量化该过程并使用更多矩阵乘法(matmuls)。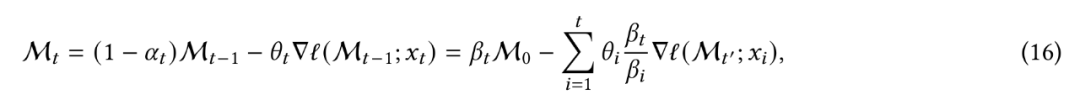
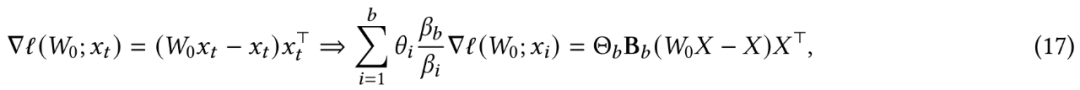

03
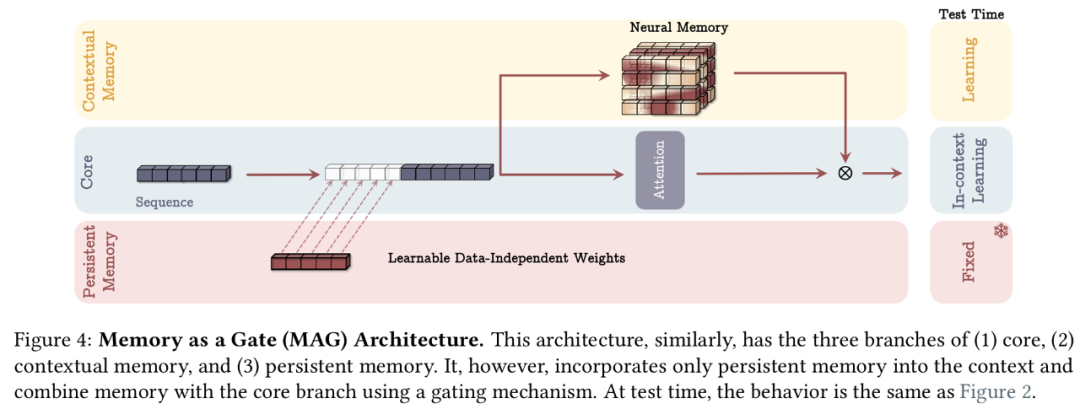
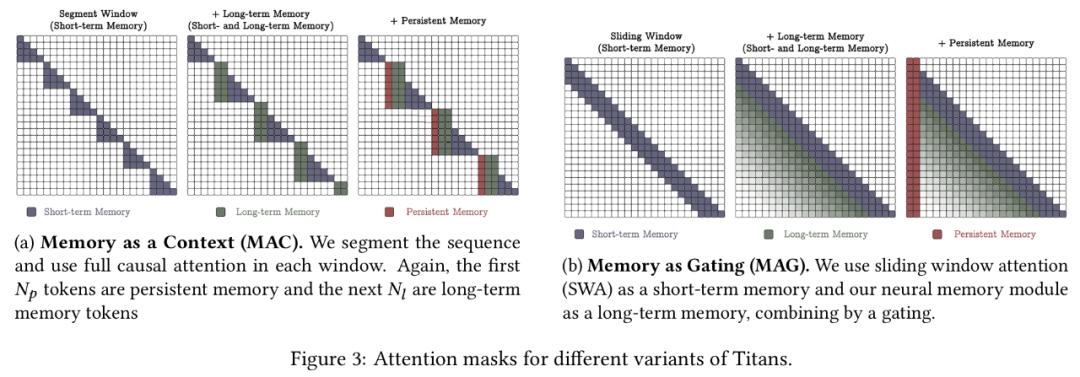
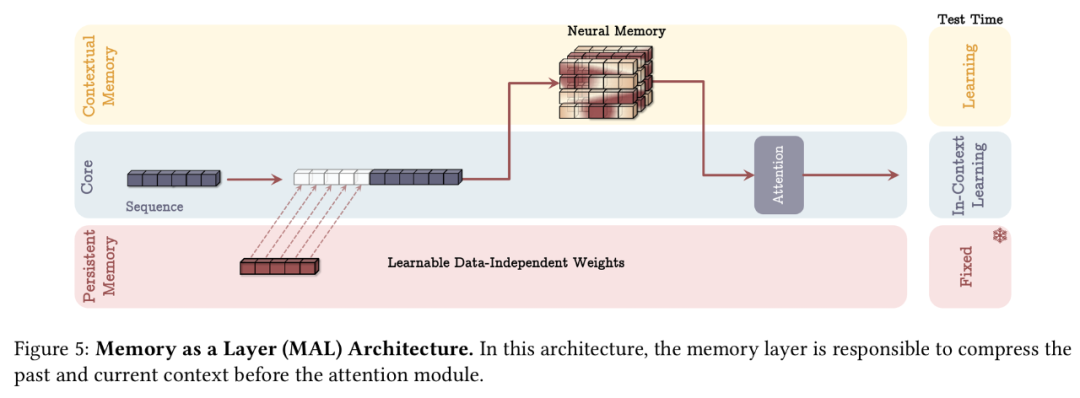
如何融合记忆?
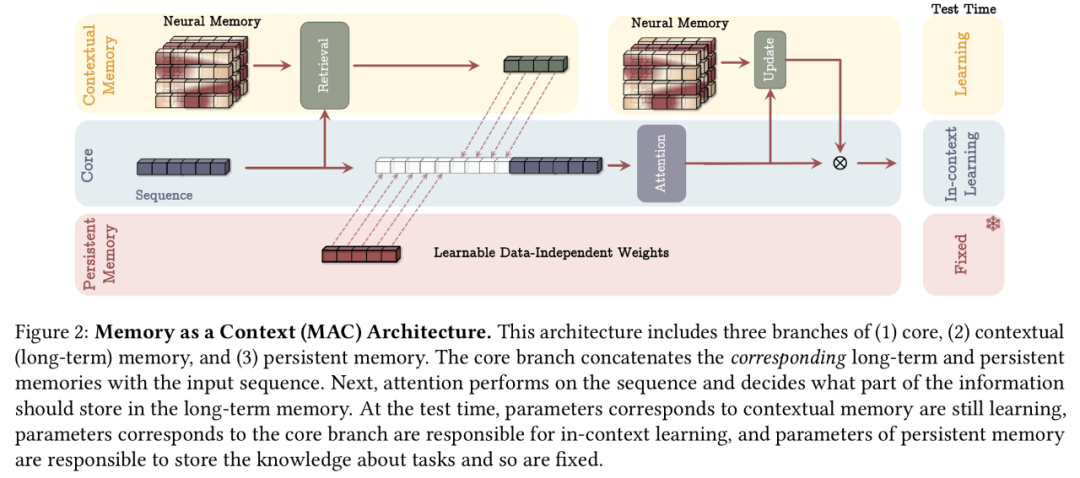
 ,首先将序列分成固定大小的片段 S^(𝑖),其中 𝑖 = 1,…,𝑁/𝐶。给定传入片段 S^(𝑡),谷歌将它视为当前上下文,将其过去的片段视为历史信息。因此,谷歌让 M_𝑡-1 成为片段 S^(𝑡) 之前的长期记忆状态,使用输入上下文作为对记忆 M^𝑡-1 的查询,以从长期记忆中检索相应的信息。谷歌如下所示检索与 S^(𝑡) 相对应的过去信息:
,首先将序列分成固定大小的片段 S^(𝑖),其中 𝑖 = 1,…,𝑁/𝐶。给定传入片段 S^(𝑡),谷歌将它视为当前上下文,将其过去的片段视为历史信息。因此,谷歌让 M_𝑡-1 成为片段 S^(𝑡) 之前的长期记忆状态,使用输入上下文作为对记忆 M^𝑡-1 的查询,以从长期记忆中检索相应的信息。谷歌如下所示检索与 S^(𝑡) 相对应的过去信息:
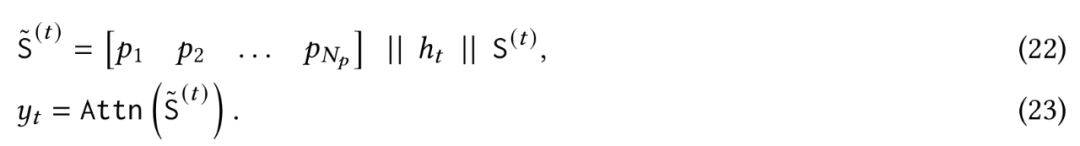


 对查询和键进行归一化。
对查询和键进行归一化。04
实验结果
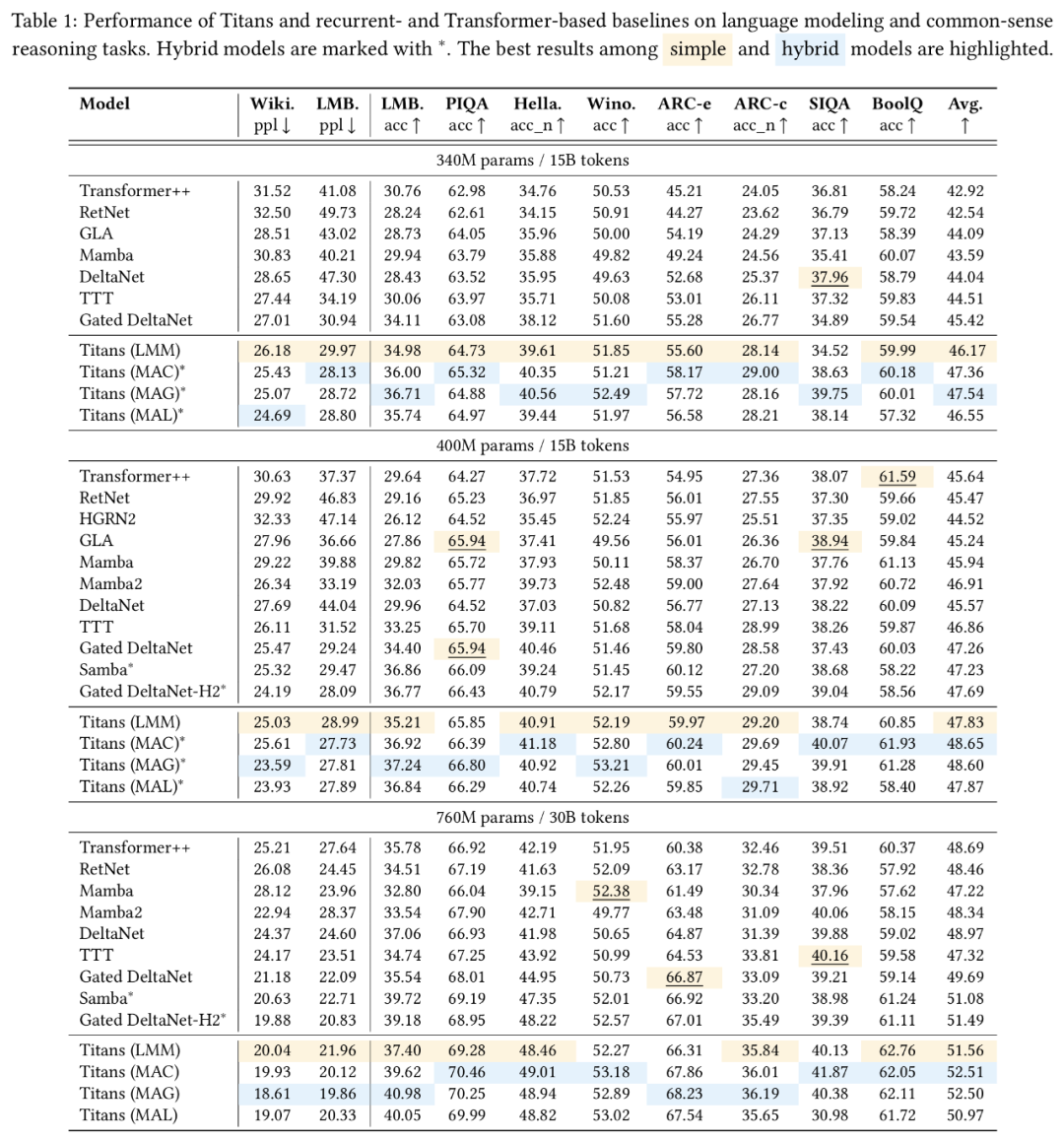
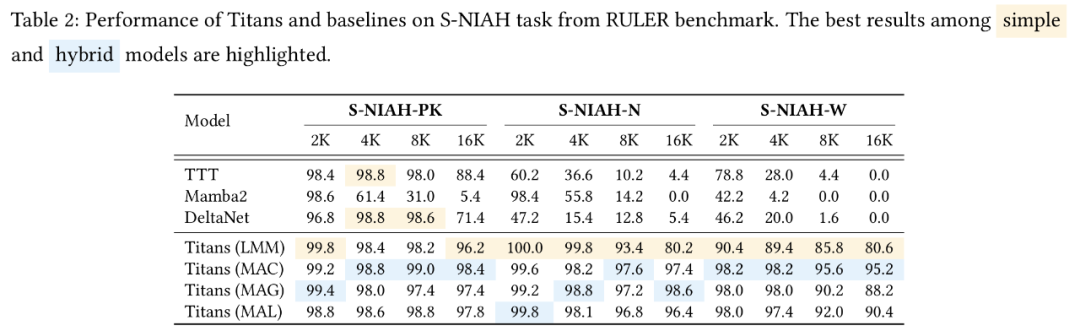
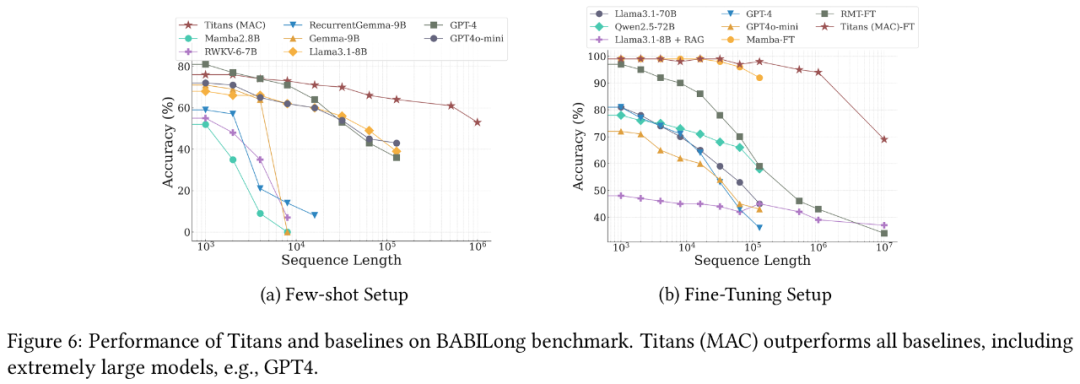
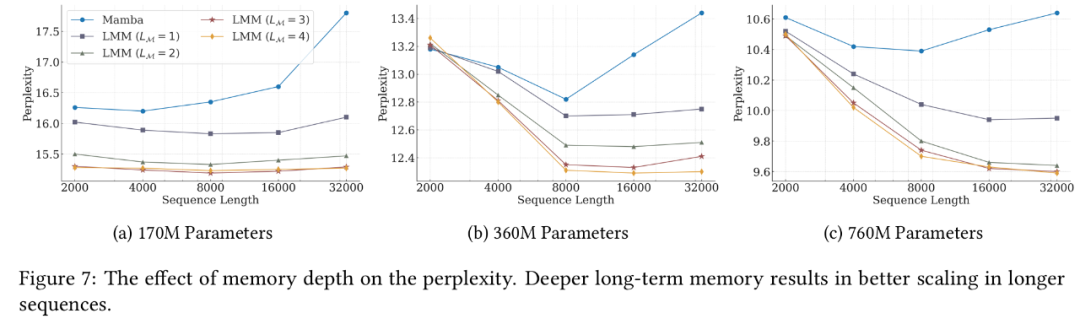
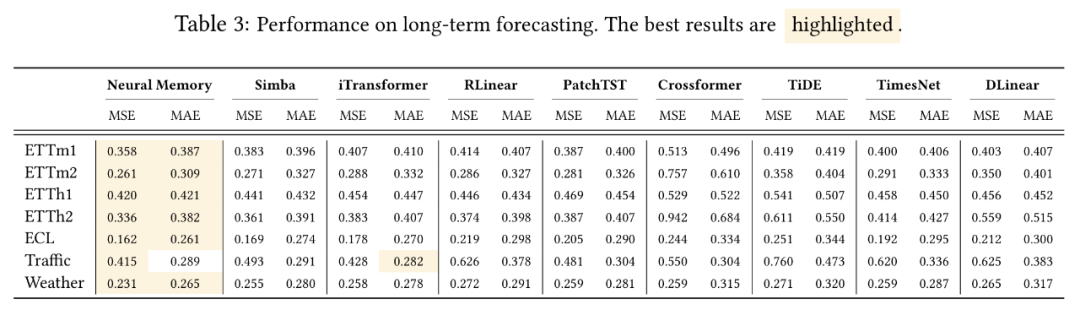
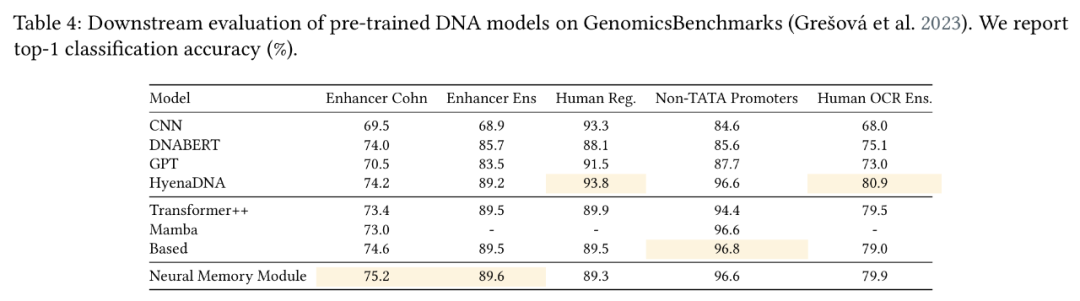
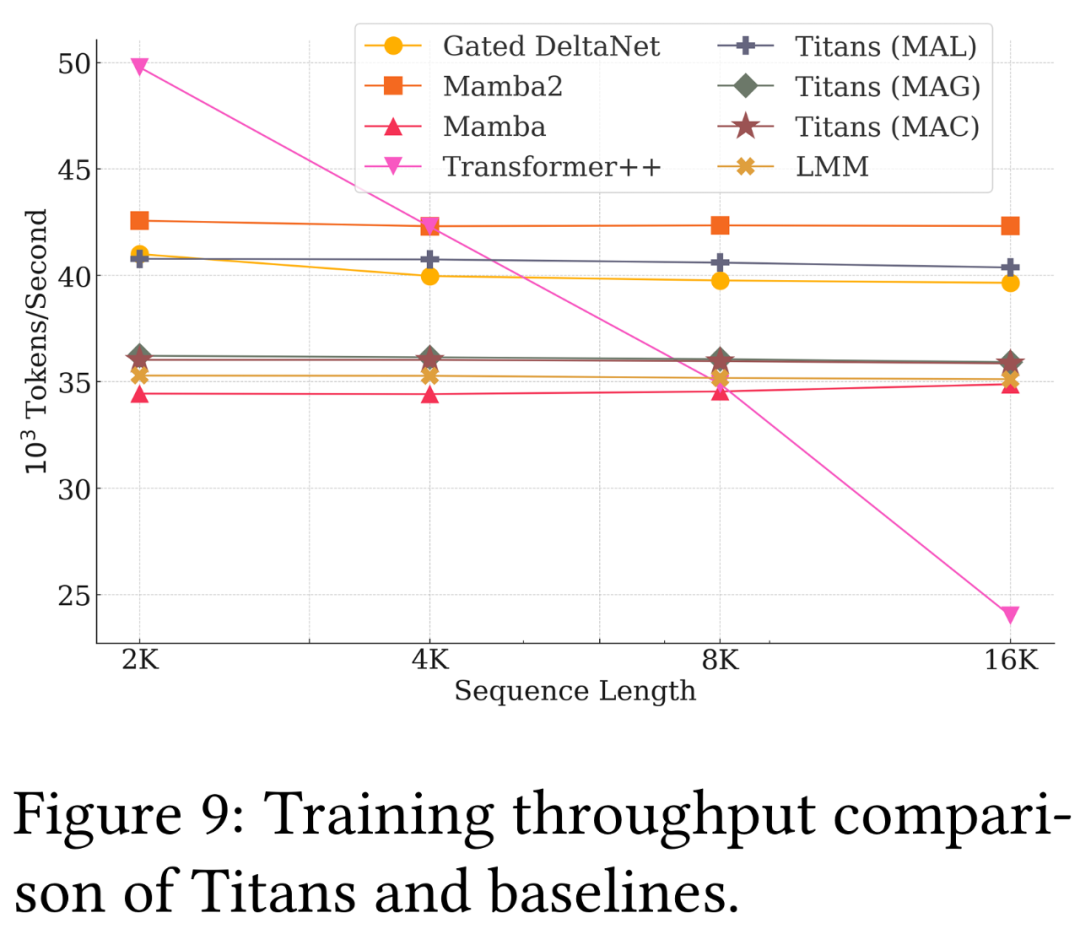

(文:Founder Park)
Transformers 到 Titans?这届论文界怕是要翻盘了!200万上下文窗口这也太逆天了吧!
超越Transformer狗圈顶流?狗破还是我破?