
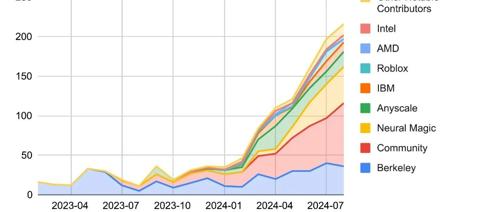
小小vLLM,竟然在2024年后半年实现了部署GPU使用时长10倍增长!
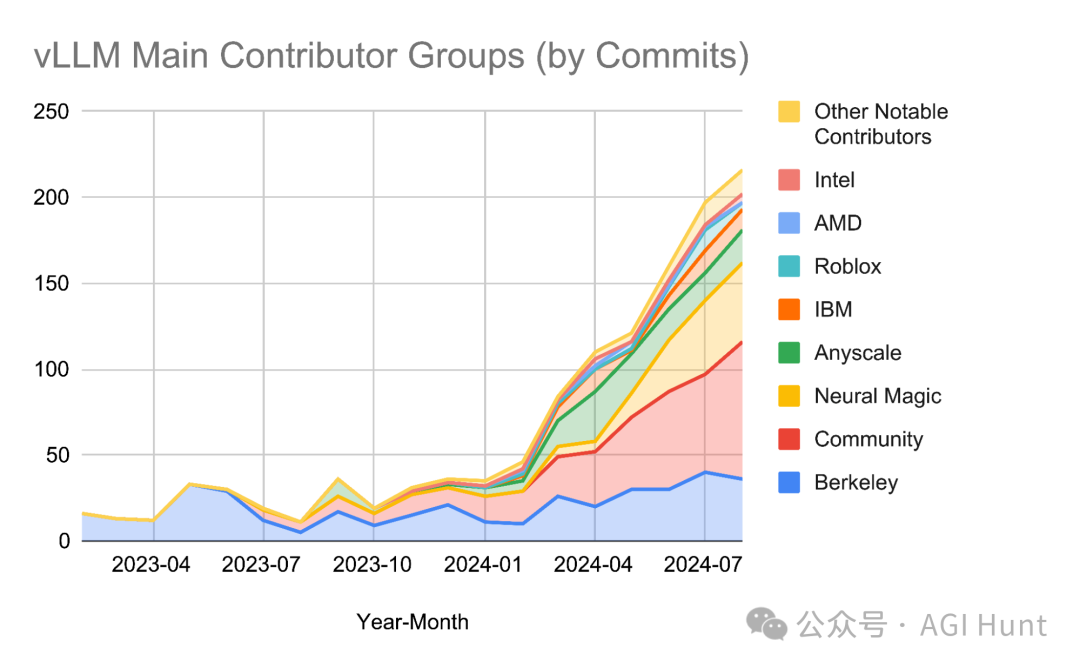
想象一下,这是什么概念?
相当于8.5万多块GPU不间断运转!而这还仅仅是统计数据中的一小部分,真实使用量只会更大。
这个被称为「开源AI生态系统事实标准」的推理引擎,究竟有什么魔力?
一路狂奔的vLLM
让我们看看这些疯狂的数据:
-
GitHub星标:从1.4万飙升到3.26万,增长2.3倍
-
贡献者数量:从190人暴涨到740人,增长3.8倍
-
月下载量:从6000次跃升到2.7万次,增长4.5倍
-
支持的模型架构:突破100+
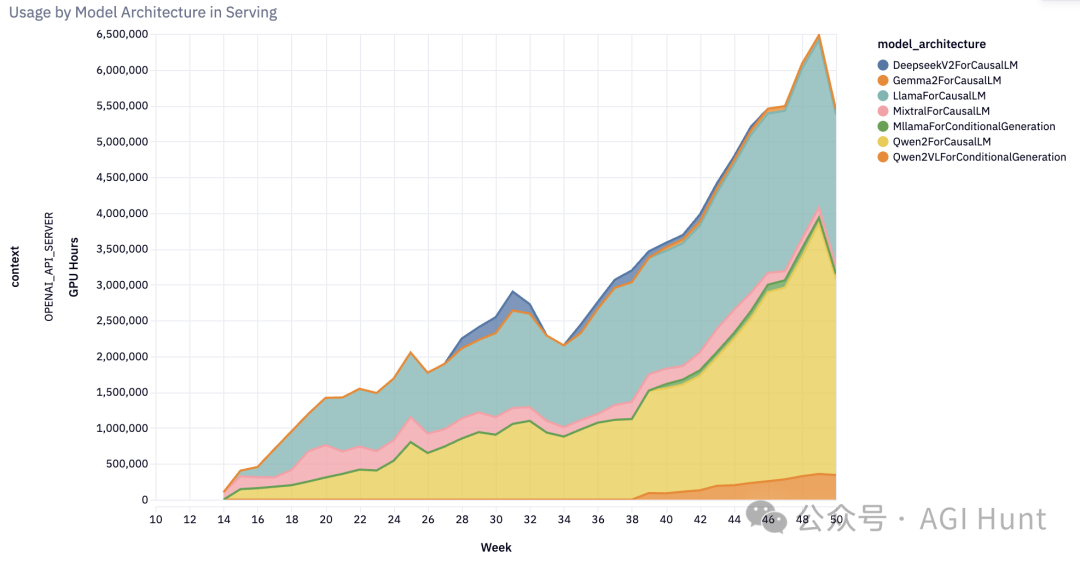
而且,这个「小而美」的项目已经不再小了:它已经为亚马逊Rufus和LinkedIn的AI功能提供支持。
硬件支持全面开花
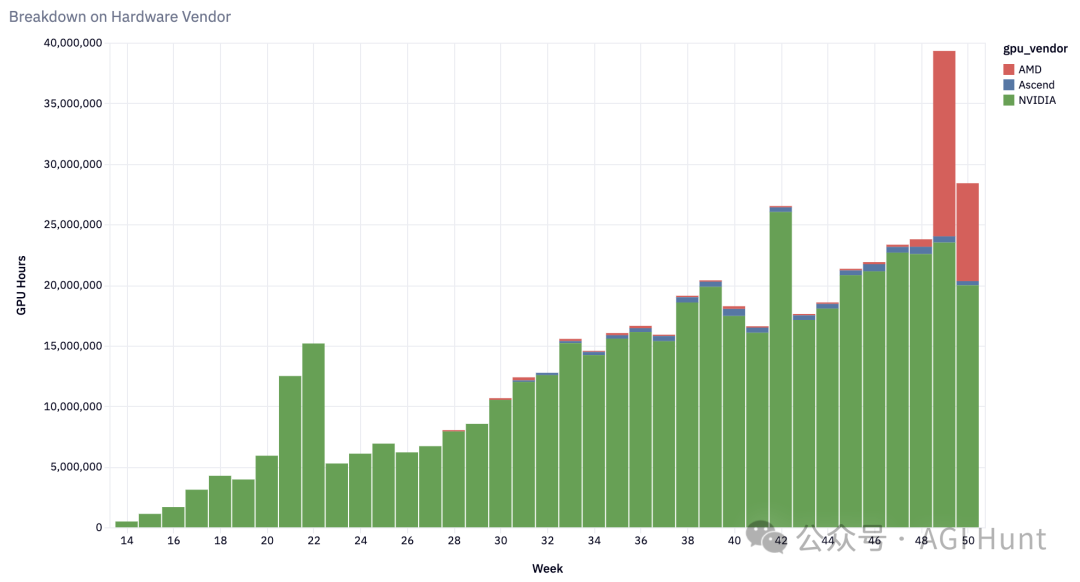
从最初只支持NVIDIA A100,vLLM现在已经成为一个「全能选手」:
-
NVIDIA系列:H100、V100等全系列支持
-
AMD阵营:MI200、MI300和Radeon RX 7900系列
-
谷歌TPU:v4、v5p、v5e,甚至最新的v6e
-
AWS芯片:Inferentia和Trainium
-
英特尔产品:Gaudi和GPU架构
-
CPU支持:x86、ARM和PowerPC全覆盖
「量化」成为新常态
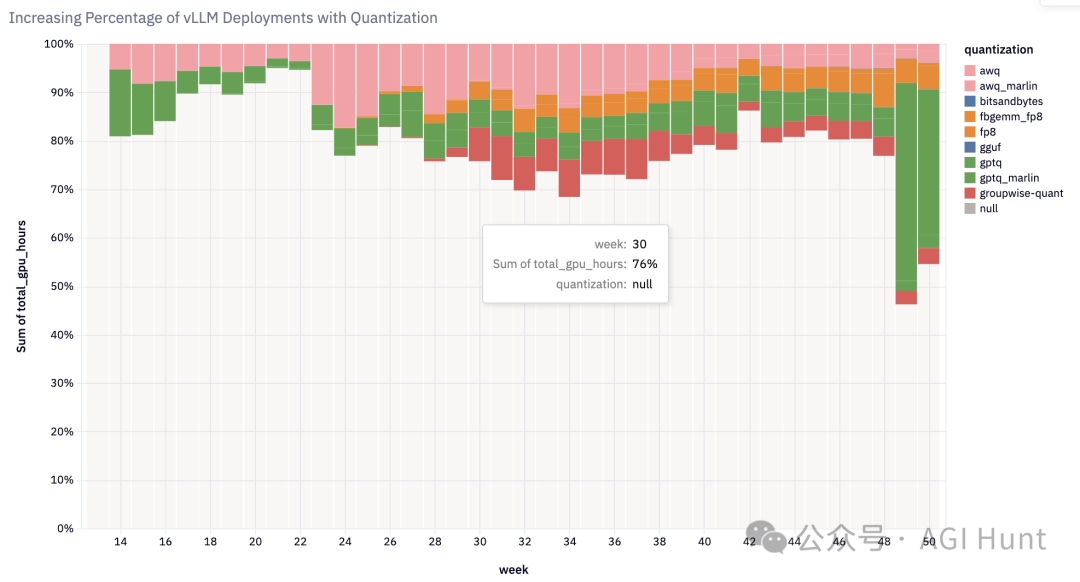
vLLM在量化方面也是「大展拳脚」:
-
支持FP8+INT8的激活量化
-
整合Marlin+Machete内核
-
引入FP8 KV Cache
-
支持AQLM、QQQ、HQQ等多种量化方案
现在,超过20%的vLLM部署都在使用量化技术!
2025:更大的野心
vLLM团队的2025规划更是「野心勃勃」:
-
单GPU运行GPT-4o级别模型
-
打造24/7高可用生产集群
-
在性能、硬件兼容性和场景优化上实现突破
这不仅是一个愿景,更是一个即将实现的目标。
通过优化注意力机制、MoE架构,以及扩展长上下文支持,vLLM正在一步步把不可能变成可能。
不仅如此,vLLM还计划将量化、前缀缓存和推测解码等功能全部标配,让每一个部署都能获得最佳性能。
最关键的是,vLLM始终保持开放。即将发布的V1架构将让每个组件都支持修改和扩展,无论是在研究还是私有分支中。
2025年的AI推理领域,又将迎来一场新革命!
(文:AGI Hunt)