


GPT-5 是真实存在的,而且它已经在我们看不到的地方塑造着世界。— Alberto Romero
反转,还是反转!
1个月前,华尔街日报才爆料了 GPT-5 效果不达预期。虽然已经完成了2轮训练,烧掉$10亿+,但还有很多问题没有解决。OpenAI 雇人写代码、做数学题、用 o1 合成数据也统统不好使。
当下我以为要等到2025年了。但经过这二天的收集整理,我先说说几条可信度极高的结论:
-
GPT-5 已经开发出来了,但被雪藏了,Anthropic 的 Claude 3.5 Opus 也被藏起来了 -
AGI 到来的时间提前了,OpenAI 的目标变成了更厉害的超级智能 ASI -
o 系列推理模型和 GPT 语言模型今年会合并成为一个系列 -
o3-mini 马上就能用了,整体来说比 o1-mini 强,比 o1 弱。这次的版本迭代没有 GPT3.5 升级到 GPT4 的那次大,看来要蹲 o4 了

一、GPT-5 被雪藏的原因
基本假设是:
OpenAI 已经开发出 GPT-5,但留在内部使用了。因为这样获得的回报远大于开放给数百万的用户使用。奥特曼想获得的回报并不是金钱,而是别的东西。

让我们先把时间线调到2024年上半年,当下OpenAI 有 GPT4、GPT-4o、GPT-4o mini,上中下三种模型为的就是平衡性能和价格。
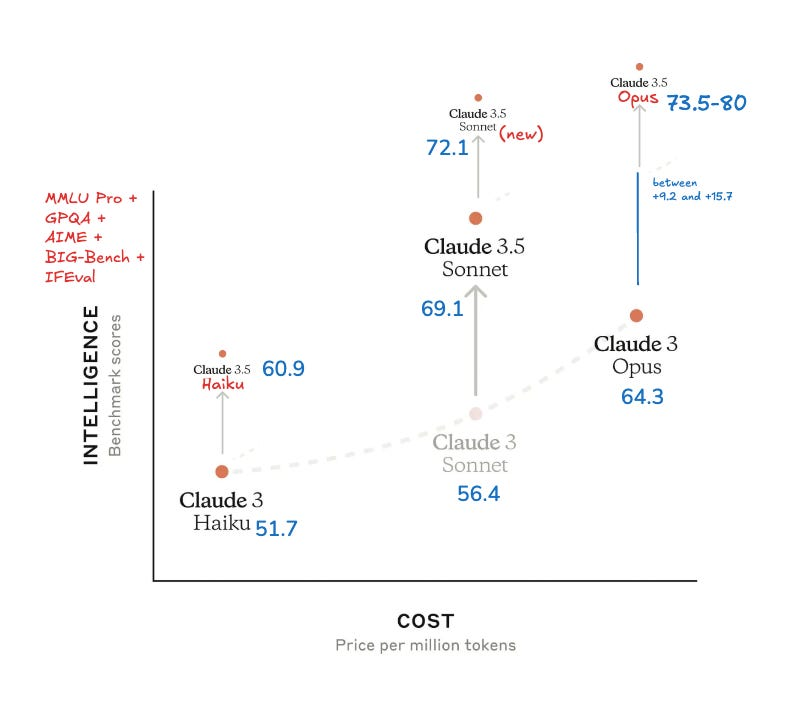
但到了10月份,这套体系就不通用了。所有人都以为 Anthropic 会发布 Claude 3.5 Opus 来对标 GPT-4o,但他们却只发布了 Sonnet 3.5 New。
也就是说 Anthropic 缺少了对标 GPT-4o 的主力模型。完全不像他们之前每次发布都狙击 OpenAI 的习惯。这个反常行为在后续的时间线也被扒出来了:
-
11月11日,Anthropic CEO 在 Lex Fridman 播客上公开否认:3.5 Opus 并没有被放弃 -
11月13日,Bloomberg在一篇报道中证实:“ Anthropic 发现 Opus 3.5 在测试里比上一代表现更好,但远没到它规模、研发成本以及推理开销所应达到的水平。” -
12月11日,Semianalysis 团队给出了最终结论:“Anthropic 完成了 Opus 3.5 的训练,而且表现良好,模型规模也符合预期。但 Anthropic 并未选择公开,而是用 Claude 3.5 Opus 来生成合成数据,并进行奖励模型训练,从而显著提升了 Claude 3.5 Sonnet 的质量”
是不是很熟悉,跟OpenAI“发不出” GPT-5 的行为一模一样。
简单来说,GPT5、Opus 3.5 被雪藏的原因有两个:
1. 从成本收益的角度看,发布 GPT5、Opus 3.5 并不划算,那么不如借助它们进一步训练一款性能更好、推理成本更低(最早版的 GPT-4o 参数可能只有GPT-4的十分之一)的模型。
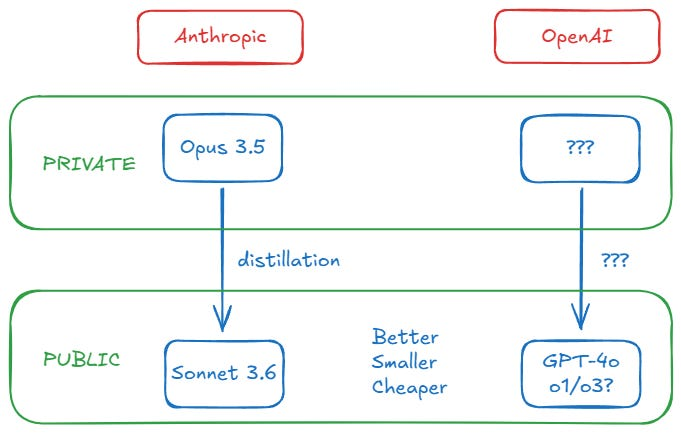
另一个方面 GPT5、Opus 3.5 放在内部使用也能限制开源社区快速追上 GPT-4(毕竟多多少少都会用高级模型生成训练数据)。
而且奥特曼可能还有更多“私心”,大家还记得 OpenAI 跟微软的天价“对赌”协议吗?
「当OpenAI 开发出能够产生至少$1000亿利润的 AI 系统时,就是 AGI 时刻。」
没有用性能、算力、模型大小等学术参数,而是直接从模型能产生的价值出发。如果以“还不成熟”为由,继续藏着 GPT-5,不仅能控制推理成本、缓解公众对性能的争议,还能避免大家去怀疑它是否已经接近“能带来 $1000亿利润”的 AGI,被迫跟微软分道扬镳。
看起来我们已经可以跟 GPT-5 say Goodbye了。
二、GPT-5消失后发生了什么
知道了 GPT-5 被雪藏起来做数据后,奥特曼后续的一大堆动作都有了合理的解析。
-
奥特曼已经不满足于实现 AGI 了,现在要实现超级智能 ASI

先简单总结它们之间的区别:
-
AGI(通用人工智能)是指一种能够理解、学习和应用知识的人工智能系统,其智能水平接近人类。AGI能够在多个领域和任务中表现出灵活性,具备自主学习和解决问题的能力。它的目标是模拟人类的认知能力,能够处理各种复杂的任务和情境。
-
ASI(超级人工智能)则是 AGI 的进一步发展,指的是一种超越人类智能的人工智能。ASI 不仅在所有任务上超越人类的能力,还能够进行自我学习和进化,解决人类难以解决的问题。它的智能水平远高于人类,可能在创造力、问题解决和社交技能等方面表现出极大的优势。
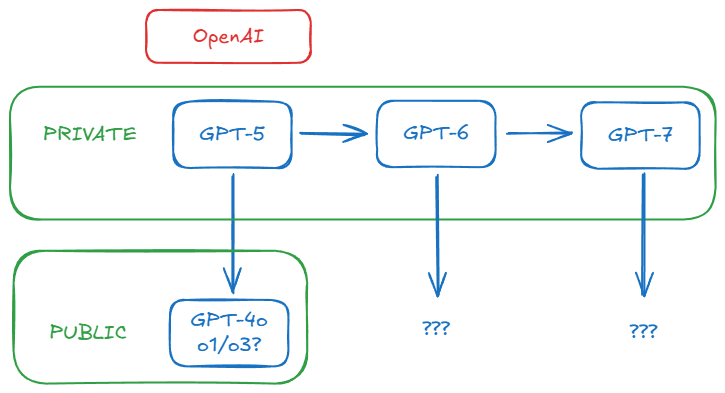
有信心做ASI,大概率是因为 OpenAI 达到了「递归自我改进」的标准,换句话说,o4,甚至是 o5 能自己进化,通过AGI的路已经非常清晰了。
同样因为 GPT-5 消失后,OpenAI开始主推o1、o3。
因为 o3 的发布,在线预测平台 Metaculus 预测在2031年强 AGI 就会实现,提前了一年。而弱 AGI 可能在2026年就会面世,提前了快25年。
虽然 o3 第一批不会对普通用户开放,但 o3-mini 快来了,昨天我都看到有人开始内测了:
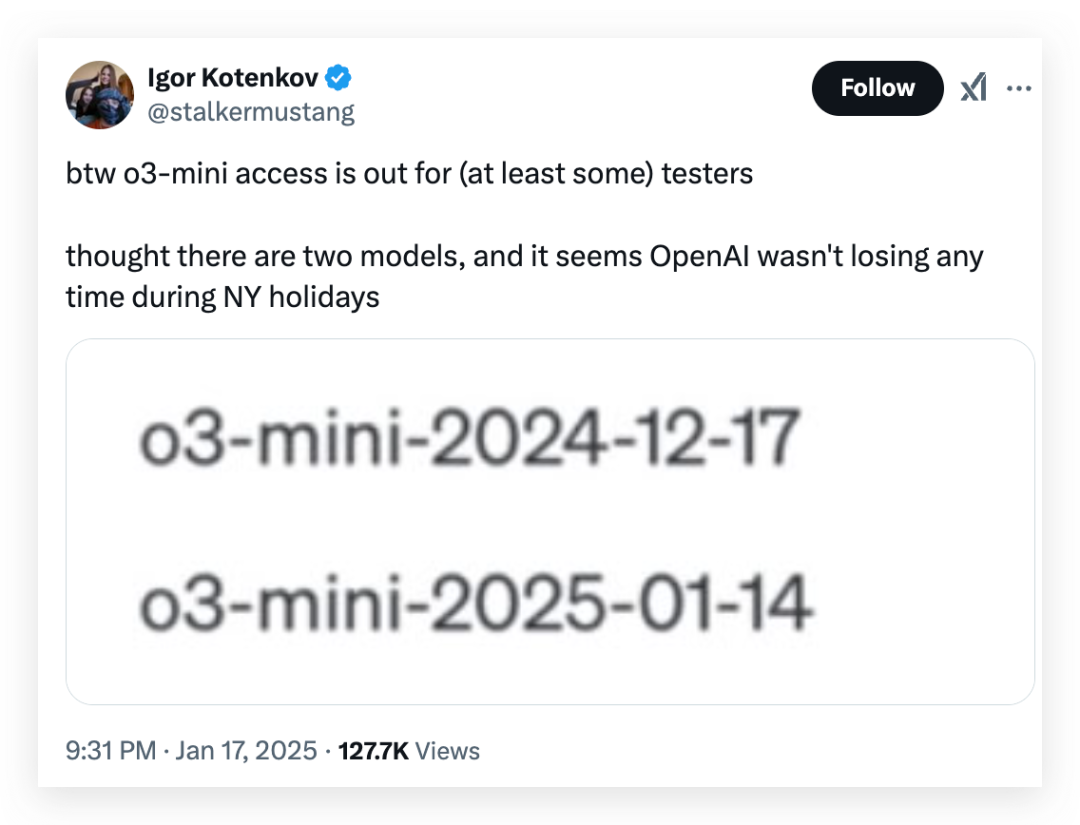
而且奥特曼最近活跃得像个人机,在评论气有问必答,所以也被人疯狂套话:“o3-mini 的性能表现会逊于 o1-pro,但速度会更快。”
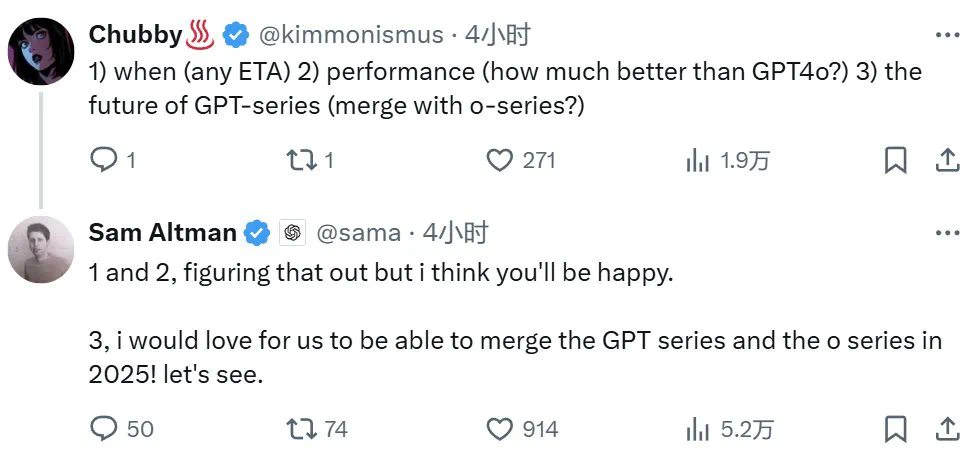
另外,奥特曼也提到了 GPT 语言模型与 o 系列推理模型将在今年完成融合,这下来 GPT-5 更是凉凉了,等 o3 更实际。。。
写在最后
像 GPT5、Claude 3.5 Opus这类模型的主要目的不是为了部署出一个几百万用户都能用上的服务,而是成为下一个模型训练数据的摇篮。
这也可能诞生出一个新的模型范式:
使用大量的显卡,堆出一个超强智力的前沿模型,然后通过合成数据等方式,转化成更小更便宜的模型。
发展至今,回想今年模型提升,大家最大感想是什么?
我印象最深刻的就是,提示语越来越简单了,
别再跟模型对话了,我找到了OpenAI o1的正确打开方式
跟 o1 模型对话的时候,不再需要一大堆内置知识了,也不需要教模型怎么做。
25年要是能用上,
o3-mini+语音通话+视觉能力+联网搜索+图像能力的话
确实离我理想的弱 AGI 不远了,
GPT-5 也变得没那么不可取代了。
@ 作者 / 卡尔 @ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)