


DeepSeek-R1 横空出世!这款由 DeepSeek 团队推出的全新大模型,不仅在数学、编程等领域表现卓越,甚至能像人一样“思考”和“反思”,展现出惊人的自主推理能力。更重要的是,它开源了! 这意味着,更强大的 AI 推理能力,人人可用!DeepSeek-R1 通过纯强化学习,无需预先的监督微调,就能让 AI 自主学习推理。再结合冷启动数据和迭代训练,模型能力更上一层楼。最妙的是,DeepSeek-R1 的“智慧”还能传授给小模型,让轻量级设备也能拥有强大的推理能力。它在 Codeforces 编程竞赛中超过 96.3% 的人类选手,并在 AIME 2024 和 MATH-500 等数学推理测试中与 OpenAI-01-1217 不相上下! DeepSeek-R1 的开源,将彻底改变 AI 领域,让更强大的 AI 触手可及。
震撼发布!能“独立思考”的 DeepSeek-R1 到底有多强?
还在用传统的大模型?你可能已经落后于时代了!今天,DeepSeek 团队带着他们的最新力作——DeepSeek-R1 震撼登场,这款大模型可不一般,它最大的亮点就是:能“独立思考”!别误会,这里的“思考”可不是简单的信息检索和机械回答,而是真正的像人一样的逻辑推理和自我反思。想象一下,一个 AI 不仅能解答数学难题,还能在解题过程中发现自己的错误并进行修正,这是不是有点科幻电影里 AI 觉醒的味道了?而 DeepSeek-R1,正在把这种科幻变成现实。
DeepSeek-R1:开启 AI 推理新纪元
DeepSeek-R1 的出现,标志着 AI 推理能力迈入了一个全新的纪元。它不仅在性能上比肩甚至超越了业界标杆 OpenAI-01-1217,更在技术路线上做出了革命性的创新。那么它是如何实现的呢?
AI 自主学习推理的奥秘
传统的 AI 大模型训练,往往需要大量的标注数据进行“喂饭式”的监督微调 (SFT)。而 DeepSeek-R1 另辟蹊径,选择了纯强化学习 (RL) 的路线。这意味着,DeepSeek-R1-Zero 不需要任何预先标注好的数据,就能像 AlphaGo 一样,通过自我博弈和奖励机制,自主学习并提升推理能力。
更进一步:让 AI 既聪明又好用
纯 RL 训练虽然强大,但也存在一些挑战,比如训练初期不稳定、输出结果不易读等。为了解决这些问题,DeepSeek-R1 引入了“冷启动”策略:利用少量高质量数据进行预热,让模型先“开开胃”。接下来是迭代式的 RL 训练,分为两个阶段:
-
• 面向推理的强化学习: 专注于提升模型在数学、编程等需要复杂推理的任务上的能力。 -
• 面向所有场景的强化学习: 让模型学习如何更好地与人类交互,提供更符合人类偏好的回答,增强模型的通用性。
通过这种 “冷启动 + 迭代式 RL” 的组合拳,DeepSeek-R1 不仅推理能力超强,还非常好用。
知识蒸馏:小模型也能拥有大智慧
DeepSeek-R1 不仅自身强大,还能将自己的“智慧”传授给其他模型。通过知识蒸馏技术,DeepSeek-R1 可以将自己的推理能力“浓缩”到参数量更小的模型中。这意味着,即使是手机、平板等轻量级设备,也能拥有强大的 AI 推理能力。DeepSeek 团队已经开源了多个基于 Qwen2.5 和 Llama3 的蒸馏模型,涵盖了 1.5B 到 70B 等不同参数规模,让更多人能够享受到 DeepSeek-R1 的强大能力。
性能对比:比肩 OpenAI o1,实力说话!
光说不练假把式,DeepSeek-R1 的实力到底如何?让我们用数据说话!
数学推理:AIME 2024 与 MATH-500 双双告捷
在 AIME 2024 美国数学邀请赛上,DeepSeek-R1 取得了 79.8% 的惊人成绩,与 OpenAI-01-1217 持平,远超其他模型。而在更具挑战性的 MATH-500 数学难题数据集上,DeepSeek-R1 更是以 97.3% 的准确率一骑绝尘,将一众对手甩在身后。这充分证明了 DeepSeek-R1 在数学推理方面的强大实力。
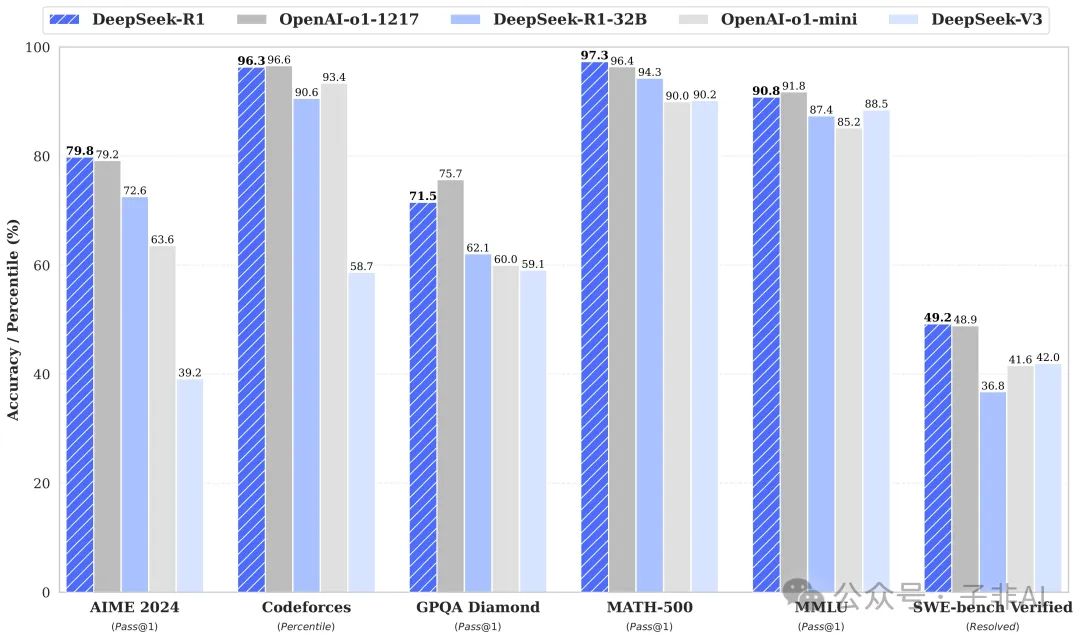
代码能力:Codeforces 竞赛中力压群雄
DeepSeek-R1 不仅能解数学题,还能写代码!在 Codeforces 编程竞赛中,DeepSeek-R1 获得了 2029 的 Elo 评分,超越了 96.3% 的人类选手。这意味着,DeepSeek-R1 的编程能力已经达到了专业程序员的水平。在 LiveCodeBench 代码生成任务上, DeepSeek-R1 也取得了 65.9% 的准确率,表现同样出色。
通用任务:知识问答与文本生成同样出色
除了数学和编程,DeepSeek-R1 在其他任务上也毫不逊色。在 MMLU、MMLU-Pro 等知识问答数据集上,DeepSeek-R1 的表现超越了 DeepSeek-V3。在 AlpacaEval 2.0 和 ArenaHard 等文本生成评测中,DeepSeek-R1 同样取得了优异成绩。这说明,DeepSeek-R1 不仅是一个“理科高手”,还是一个“文科状元”。
模型与代码全面开源,助力 AI 社区发展
DeepSeek 团队秉承开源精神,将 DeepSeek-R1 的模型和代码全部开源,让全球的开发者都能参与到 AI 推理能力的研究和应用中来。
DeepSeek-R1 系列模型: DeepSeek 团队开源了 DeepSeek-R1-Zero 和 DeepSeek-R1 两个模型。DeepSeek-R1-Zero 是纯 RL 训练的产物,而 DeepSeek-R1 则是在 DeepSeek-R1-Zero 的基础上,结合了冷启动数据和迭代式 RL 训练,性能更加强大。
蒸馏模型: 除了 DeepSeek-R1 系列模型,DeepSeek 团队还开源了多个蒸馏模型,让轻量级设备也能拥有强大的 AI 推理能力。这些蒸馏模型基于 Qwen2.5 和 Llama3,参数规模从 1.5B 到 70B 不等,可以满足不同场景的需求。
亮点解读:DeepSeek-R1 的“超能力”
DeepSeek-R1 的强大性能背后,是哪些技术创新在发挥作用?
“顿悟”时刻:AI 竟然会自主反思了!
DeepSeek-R1-Zero 在训练过程中,展现出了一种令人惊叹的能力:自我反思。在解决数学问题时,DeepSeek-R1-Zero 会先尝试解答,然后在解答过程中突然意识到可能存在的错误,并进行自我修正。这种“顿悟”式的行为,类似于人类在解决问题时的思维过程,展现了 RL 强大的潜力。如下所示, 我们可以看到在一个数学问题的解决中,模型输出了”Wait, wait. Wait. That’s an aha moment I can flag here.” 这种类似人类的表达。

创新训练策略:兼顾专精与通用的新思路
DeepSeek-R1 采用了一种创新的训练策略:冷启动 + 迭代式 RL。这种策略既保证了模型在推理能力上的专注提升,又兼顾了模型在其他任务上的通用性。通过先进行面向推理的强化学习,再进行面向所有场景的强化学习,DeepSeek-R1 实现了“既专又博”的目标。
深入解读:DeepSeek-R1 的技术奥秘
强化学习的魔力
DeepSeek-R1 的核心在于强化学习(RL)。不同于传统的监督学习,RL 通过与环境的交互来学习,就像一个孩子通过不断的尝试和错误来学习走路一样。DeepSeek-R1 采用了两种不同的 RL 训练流程:DeepSeek-R1-Zero 的纯 RL 训练和 DeepSeek-R1 的基于冷启动的 RL 训练。
DeepSeek-R1-Zero:纯粹的强化学习之路
DeepSeek-R1-Zero 的训练过程完全依赖于 RL,没有使用任何人工标注的数据。
高效的 GRPO 算法: DeepSeek-R1-Zero 采用了 GRPO (Group Relative Policy Optimization) 算法进行训练。GRPO 是一种高效的 RL 算法,它通过比较一组输出的优劣来估计奖励,而不需要一个独立的 Critic 模型,从而节省了大量的计算资源。相较于传统的 PPO 算法需要维护一个 Critic 模型,GRPO 通过在每次更新时采样一组响应并进行比较,避免了Critic 模型的训练和维护成本。
基于规则的奖励: DeepSeek-R1-Zero 使用了一种基于规则的奖励模型。对于数学题,模型需要给出最终的答案,并根据答案的正确性获得奖励。对于代码题,模型生成的代码会通过编译器进行测试,并根据测试结果获得奖励。这种基于规则的奖励模型简单有效,避免了训练复杂的神经奖励模型的开销和不稳定性。
结构化的训练模板: 为了引导模型生成清晰的推理过程,DeepSeek-R1-Zero 使用了一个结构化的训练模板。模型需要在 <think> 和 </think> 标签之间输出推理过程,在 <answer> 和 </answer> 标签之间输出最终答案。如下所示,我们可以看到清晰的推理过程和答案。

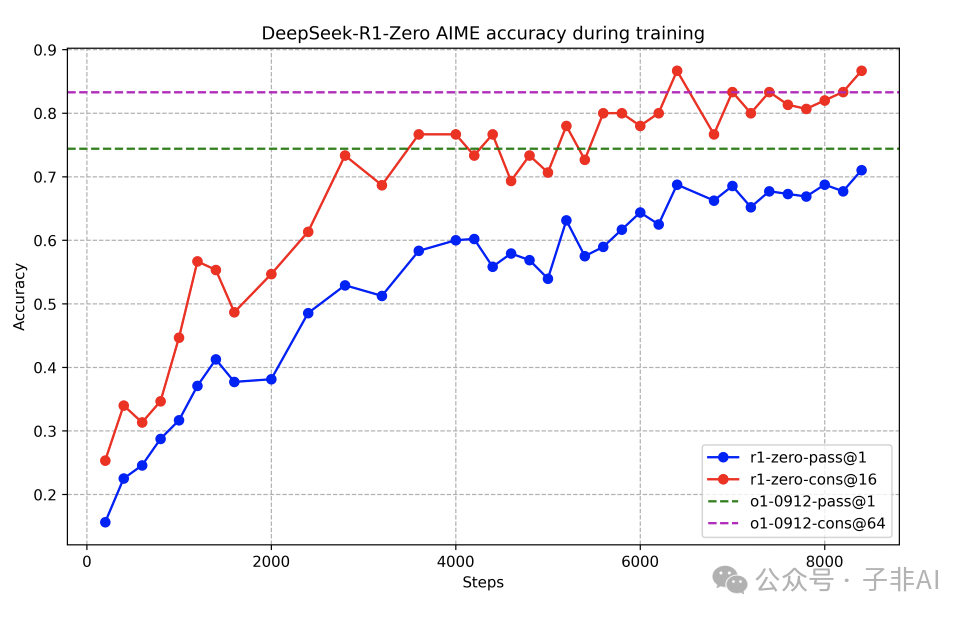
DeepSeek-R1-Zero 的非凡表现: DeepSeek-R1-Zero 在 AIME 2024 上的表现证明了纯 RL 训练的有效性。随着训练的进行,DeepSeek-R1-Zero 的性能稳步提升,最终达到了与 OpenAI-01-0912 相当的水平。如下所示,我们可以看到 AIME 2024 分数随着训练逐步上升。
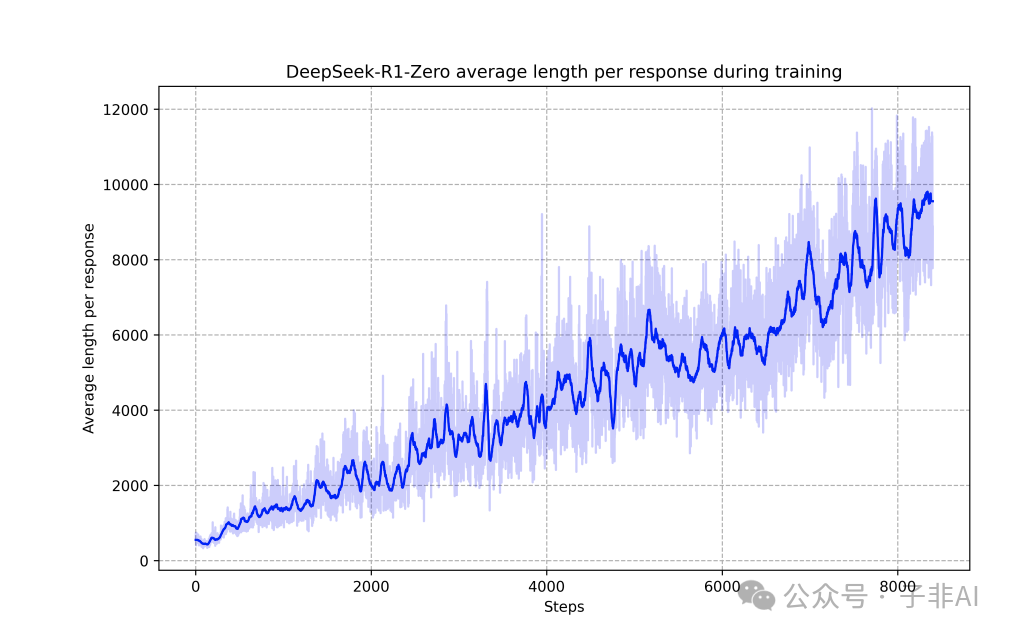
更有趣的是,DeepSeek-R1-Zero 在训练过程中展现出了自进化的能力。模型的推理过程越来越长,越来越复杂,并且自发地学会了反思和自我修正。如下所示,我们可以看到推理过程随着训练逐步变长。
DeepSeek-R1:更进一步,精益求精
DeepSeek-R1 在 DeepSeek-R1-Zero 的基础上,引入了冷启动数据和迭代式 RL 训练,进一步提升了模型的性能和通用性。
冷启动的妙用: 为了解决纯 RL 训练初期阶段的不稳定性和输出可读性差等问题,DeepSeek-R1 使用了少量高质量的“冷启动”数据。这些数据通过人工标注或从 DeepSeek-R1-Zero 的输出中筛选得到,为模型的训练提供了一个良好的起点。这些数据确保模型在训练初期就能生成符合人类阅读习惯的、格式正确的推理过程和答案。
专注推理的强化学习: 在冷启动之后,DeepSeek-R1 首先进行面向推理的强化学习,专注于提升模型在数学、编程等需要复杂推理的任务上的能力。在这个阶段,模型会继续使用基于规则的奖励模型,并针对推理任务进行优化。
拒绝采样与监督微调: 在面向推理的 RL 训练收敛后,DeepSeek-R1 会利用当前的 checkpoint 进行拒绝采样,生成大量的 SFT 数据。这些数据不仅包含推理任务,还包含其他类型的任务,例如写作、问答等。然后,DeepSeek-R1 会利用这些数据进行监督微调,从而增强模型的通用性。通过拒绝采样,模型可以探索更多样化的输出空间,并从中学习到更丰富的知识和表达方式。
面向所有场景的强化学习: 在监督微调之后,DeepSeek-R1 会进行面向所有场景的强化学习,进一步提升模型的通用性和安全性。在这个阶段,模型会学习如何更好地与人类交互,提供更符合人类偏好的回答,并避免生成有害或有偏见的内容。这一阶段的训练目标是让模型在各种场景下都能给出安全、可靠、符合人类价值观的回答。
知识蒸馏: DeepSeek-R1 不仅自身强大,还能将自己的“智慧”传授给其他模型。通过知识蒸馏技术,DeepSeek-R1 可以将自己的推理能力“浓缩”到参数量更小的模型中。这使得即使是手机、平板等轻量级设备,也能拥有强大的 AI 推理能力。通过蒸馏,可以将大模型的知识和能力迁移到小模型上,从而实现模型的小型化和高效化。
DeepSeek-R1:人人可用的 AI 推理神器
DeepSeek-R1 不仅是一个技术突破,更是一个人人可用的 AI 推理神器。你可以通过 DeepSeek 的官方网站 chat.deepseek.com 与 DeepSeek-R1 进行在线对话,感受它的强大能力。同时,DeepSeek 团队还提供了 OpenAI 兼容的 API platform.deepseek.com,方便开发者将 DeepSeek-R1 集成到自己的应用中。
DeepSeek-R1 的代码和模型权重基于 MIT 协议开源,允许商业使用和二次开发。
DeepSeek-R1 的发布,标志着 AI 推理能力迈入了一个全新的时代。它不仅在性能上取得了重大突破,更在技术路线上做出了革命性的创新。DeepSeek 团队的开源精神,也为 AI 社区的发展注入了新的活力。我们相信,DeepSeek-R1 将成为 AI 发展史上的一个重要里程碑,开启 AI 推理的新篇章!
推荐阅读
-
2024 年度 AI 报告(一):Menlo 解读企业级 AI 趋势,掘金 AI 时代的行动指南 2024年度AI报告(二):来自Translink的前瞻性趋势解读 – 投资人与创业者必看 2024年度AI报告(三):ARK 木头姐对人形机器人的深度洞察 2024年度AI报告(四):洞察未来科技趋势 – a16z 2025 技术展望 2024年度AI报告(五):中国信通院《人工智能发展报告(2024)》深度解读 2025 AI 展望 (一):LLM 之上是 Agent AI,探索多模态交互的未来视界 2025 AI 展望 (二):红杉资本展望2025——人工智能的基础与未来 2025 AI 展望(三):Snowflake 洞察 – AI 驱动的未来,机遇、挑战与变革
-
• DeepSeek 官网: https://www.deepseek.com/ -
• DeepSeek Chat: https://chat.deepseek.com/ -
• DeepSeek-R1 论文: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf -
• DeepSeek-R1-Zero 模型: https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero
-
• DeepSeek API 平台: https://platform.deepseek.com/
(文:子非AI)
Wow! 这款DeepSeek-R1真是厉害了!参数量破亿,性能强劲,开源更是给力!在数学、编程和知识问答上都表现出色,简直就像是人工智能界的划时代人物!
听说DeepSeek-R1开源了?那我滴AI不就是 Everyone Can Have 了吗?开源后什么都没说,性能直接秒杀同类选手。数学、编程都不弱,知识问答同样666!这种AI真的让码农都失业了。